Downloaded 16 times












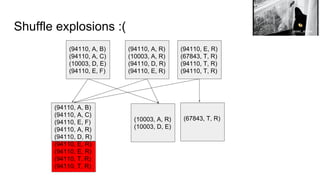
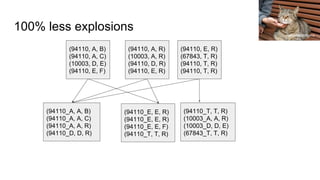
![So what does that look like?
(94110, A, B)
(94110, A, C)
(10003, D, E)
(94110, E, F)
(94110, A, R)
(10003, A, R)
(94110, D, R)
(94110, E, R)
(94110, E, R)
(67843, T, R)
(94110, T, R)
(94110, T, R)
(67843, T, R)(10003, A, R)
(94110, [(A, B), (A, C), (E, F), (A, R), (D, R), (E, R), (E, R), (T, R) (T, R)]
Tomomi](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-13-320.jpg)












![How to avoid lineage explosions:
/**
* Cut the lineage of a DataFrame which has too long a query
plan.
*/
def cutLineage(df: DataFrame): DataFrame = {
val sqlCtx = df.sqlContext
//tag::cutLineage[]
val rdd = df.rdd
rdd.cache()
sqlCtx.createDataFrame(rdd, df.schema)
//end::cutLineage[]
}
karmablue](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-31-320.jpg)

![Using Datasets to mix functional & relational style:
val ds: Dataset[RawPanda] = ...
val happiness = ds.toDF().filter($"happy" === true).as[RawPanda].
select($"attributes"(0).as[Double]).
reduce((x, y) => x + y)](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-33-320.jpg)
![So what was that?
ds.toDF().filter($"happy" === true).as[RawPanda].
select($"attributes"(0).as[Double]).
reduce((x, y) => x + y)
convert a Dataset to a
DataFrame to access
more DataFrame
functions. Not needed in
2.0 + & almost free
anyways
Convert DataFrame
back to a Dataset
A typed query (specifies the
return type).Traditional functional
reduction:
arbitrary scala code :)](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-34-320.jpg)
![And functional style maps:
/**
* Functional map + Dataset, sums the positive attributes for the
pandas
*/
def funMap(ds: Dataset[RawPanda]): Dataset[Double] = {
ds.map{rp => rp.attributes.filter(_ > 0).sum}
}](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-35-320.jpg)




, Some
(1000)))
)
val sqlCtx = new SQLContext(sc)
val v = Validation(sc, sqlCtx, vc)
//Do work here....
assert(v.validate(5) === true)
}
Photo by Dvortygirl](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-40-320.jpg)




: Option[(T, T)] = {
expected.zip(result).filter{case (x, y) => x != y}.take(1).
headOption
}
Matti Mattila](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-45-320.jpg)
: Option
[(T, Int, Int)] = {
val expectedKeyed = expected.map(x => (x, 1)).reduceByKey(_ +
_)
val resultKeyed = result.map(x => (x, 1)).reduceByKey(_ + _)
expectedKeyed.cogroup(resultKeyed).filter{case (_, (i1, i2))
=>
i1.isEmpty || i2.isEmpty || i1.head != i2.head}.take(1).
headOption.
map{case (v, (i1, i2)) => (v, i1.headOption.getOrElse(0),
i2.headOption.getOrElse(0))}
}
Matti Mattila](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-46-320.jpg)


(Arbitrary.arbitrary[String])) {
rdd => rdd.map(_.length).count() == rdd.count()
}
check(property)
}](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-49-320.jpg)

(Arbitrary.arbitrary[String])) {
rdd => rdd.map(_.length).count() == rdd.count()
}
check(property)
}](https://image.slidesharecdn.com/beyondshuffling-scaladays2-160620194253/85/Beyond-shuffling-Scala-Days-Berlin-2016-50-320.jpg)










The document is a presentation by Holden Karau, a principal software engineer at IBM, that covers various aspects of Apache Spark, including RDD reuse, key/value data processing, and the benefits of Spark SQL. It addresses common pitfalls, such as key skew and the use of groupByKey, and introduces concepts like datasets and testing Spark code. Additionally, it discusses techniques for ensuring data validation and performance optimization in Spark jobs.
















































































