Downloaded 37 times











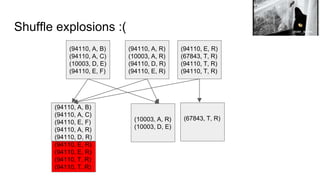
![So what does that look like?
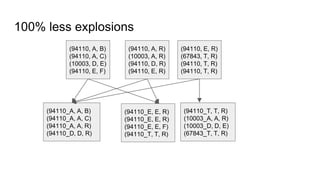
(94110, A, B)
(94110, A, C)
(10003, D, E)
(94110, E, F)
(94110, A, R)
(10003, A, R)
(94110, D, R)
(94110, E, R)
(94110, E, R)
(67843, T, R)
(94110, T, R)
(94110, T, R)
(67843, T, R)(10003, A, R)
(94110, [(A, B), (A, C), (E, F), (A, R), (D, R), (E, R), (E, R), (T, R) (T, R)]
Tomomi](https://image.slidesharecdn.com/beyondshuffling-stratalondon1-160602091219/85/Beyond-shuffling-Strata-London-2016-13-320.jpg)









![How to avoid lineage explosions:
/**
* Cut the lineage of a DataFrame which has too long a query plan.
*/
def cutLineage(df: DataFrame): DataFrame = {
val sqlCtx = df.sqlContext
//tag::cutLineage[]
val rdd = df.rdd
rdd.cache()
sqlCtx.createDataFrame(rdd, df.schema)
//end::cutLineage[]
}
karmablue](https://image.slidesharecdn.com/beyondshuffling-stratalondon1-160602091219/85/Beyond-shuffling-Strata-London-2016-29-320.jpg)

![Using Datasets to mix functional & relational style:
val ds: Dataset[RawPanda] = ...
val happiness = ds.toDF().filter($"happy" === true).as[RawPanda].
select($"attributes"(0).as[Double]).
reduce((x, y) => x + y)](https://image.slidesharecdn.com/beyondshuffling-stratalondon1-160602091219/85/Beyond-shuffling-Strata-London-2016-31-320.jpg)
![So what was that?
ds.toDF().filter($"happy" === true).as[RawPanda].
select($"attributes"(0).as[Double]).
reduce((x, y) => x + y)
convert a Dataset to a
DataFrame to access
more DataFrame
functions. Shouldn’t be
needed in 2.0 + &
almost free anyways
Convert DataFrame
back to a Dataset
A typed query (specifies the
return type).Traditional functional
reduction:
arbitrary scala code :)](https://image.slidesharecdn.com/beyondshuffling-stratalondon1-160602091219/85/Beyond-shuffling-Strata-London-2016-32-320.jpg)
![And functional style maps:
/**
* Functional map + Dataset, sums the positive attributes for the
pandas
*/
def funMap(ds: Dataset[RawPanda]): Dataset[Double] = {
ds.map{rp => rp.attributes.filter(_ > 0).sum}
}](https://image.slidesharecdn.com/beyondshuffling-stratalondon1-160602091219/85/Beyond-shuffling-Strata-London-2016-33-320.jpg)






: Option[(T, T)] = {
expected.zip(result).filter{case (x, y) => x !=
y}.take(1).headOption
}
Matti Mattila](https://image.slidesharecdn.com/beyondshuffling-stratalondon1-160602091219/85/Beyond-shuffling-Strata-London-2016-40-320.jpg)
:
Option[(T, Int, Int)] = {
val expectedKeyed = expected.map(x => (x, 1)).reduceByKey(_ +
_)
val resultKeyed = result.map(x => (x, 1)).reduceByKey(_ + _)
expectedKeyed.cogroup(resultKeyed).filter{case (_, (i1, i2))
=>
i1.isEmpty || i2.isEmpty || i1.head !=
i2.head}.take(1).headOption.
map{case (v, (i1, i2)) => (v, i1.headOption.getOrElse(0),
i2.headOption.getOrElse(0))}
}
Matti Mattila](https://image.slidesharecdn.com/beyondshuffling-stratalondon1-160602091219/85/Beyond-shuffling-Strata-London-2016-41-320.jpg)


(Arbitrary.arbitrary[String])) {
rdd => rdd.map(_.length).count() == rdd.count()
}
check(property)
}](https://image.slidesharecdn.com/beyondshuffling-stratalondon1-160602091219/85/Beyond-shuffling-Strata-London-2016-44-320.jpg)

(Arbitrary.arbitrary[String])) {
rdd => rdd.map(_.length).count() == rdd.count()
}
check(property)
}](https://image.slidesharecdn.com/beyondshuffling-stratalondon1-160602091219/85/Beyond-shuffling-Strata-London-2016-45-320.jpg)







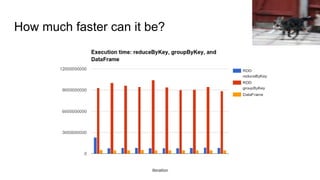
The document discusses advanced techniques for scaling Apache Spark, covering topics such as RDD reuse, key/value data handling, and the pitfalls of using groupbykey. It introduces new features in Spark like datasets and SQL optimizations, and emphasizes the importance of testing Spark code effectively. Key takeaways include strategies to avoid common performance issues and the significance of efficient data processing in Spark applications.






















































![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)