Download to read offline

![The Data Deluge: Data Data Everywhere
22
180 zettabytes will be created in 2025 [IDC report]](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-2-2048.jpg)
![600$
to buy a disk drive that can store all of the world’s
music
3
[McKinsey Global Institute Special Report, June ’11]
Data Storage is Cheap](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-3-2048.jpg)

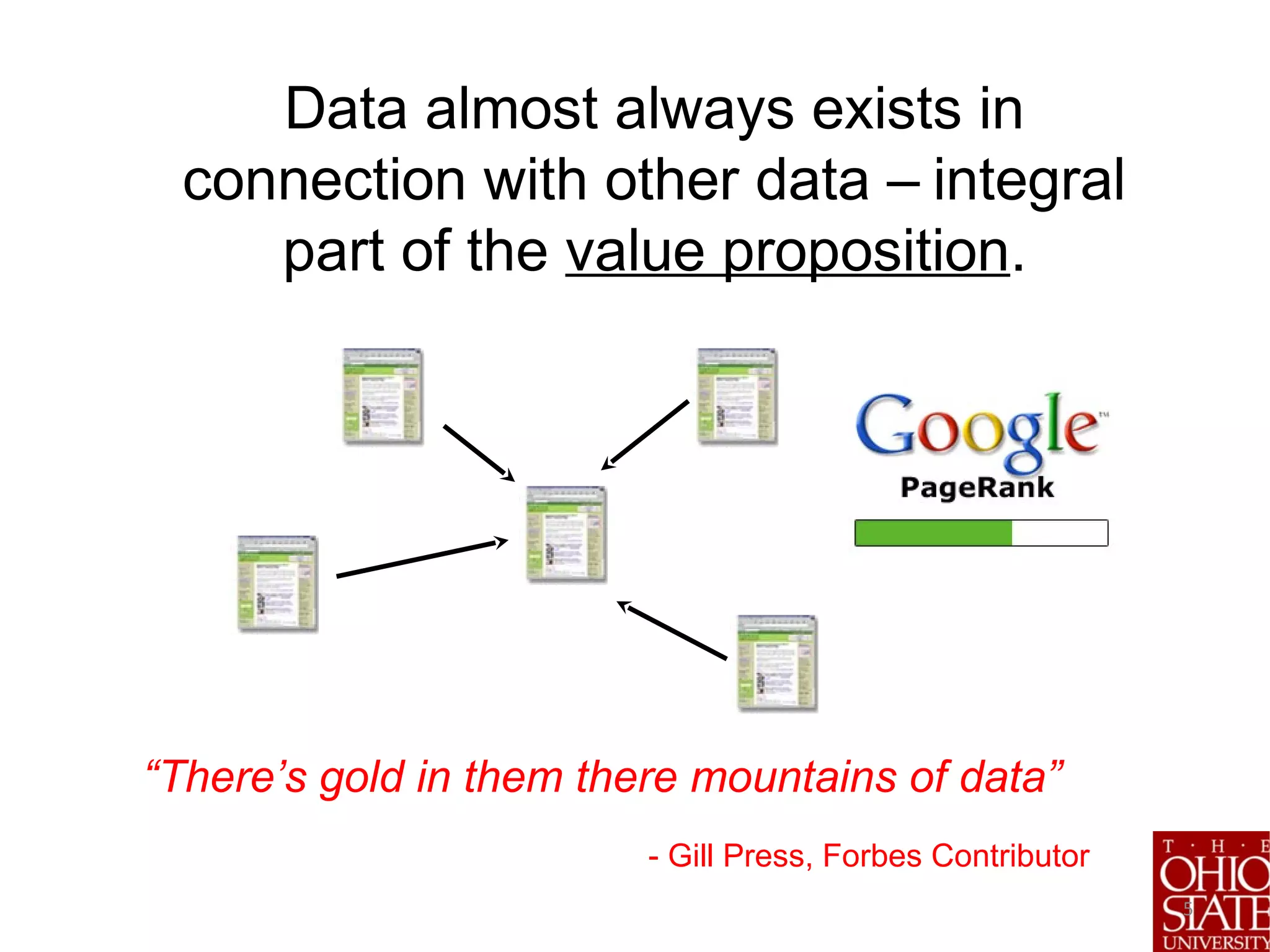
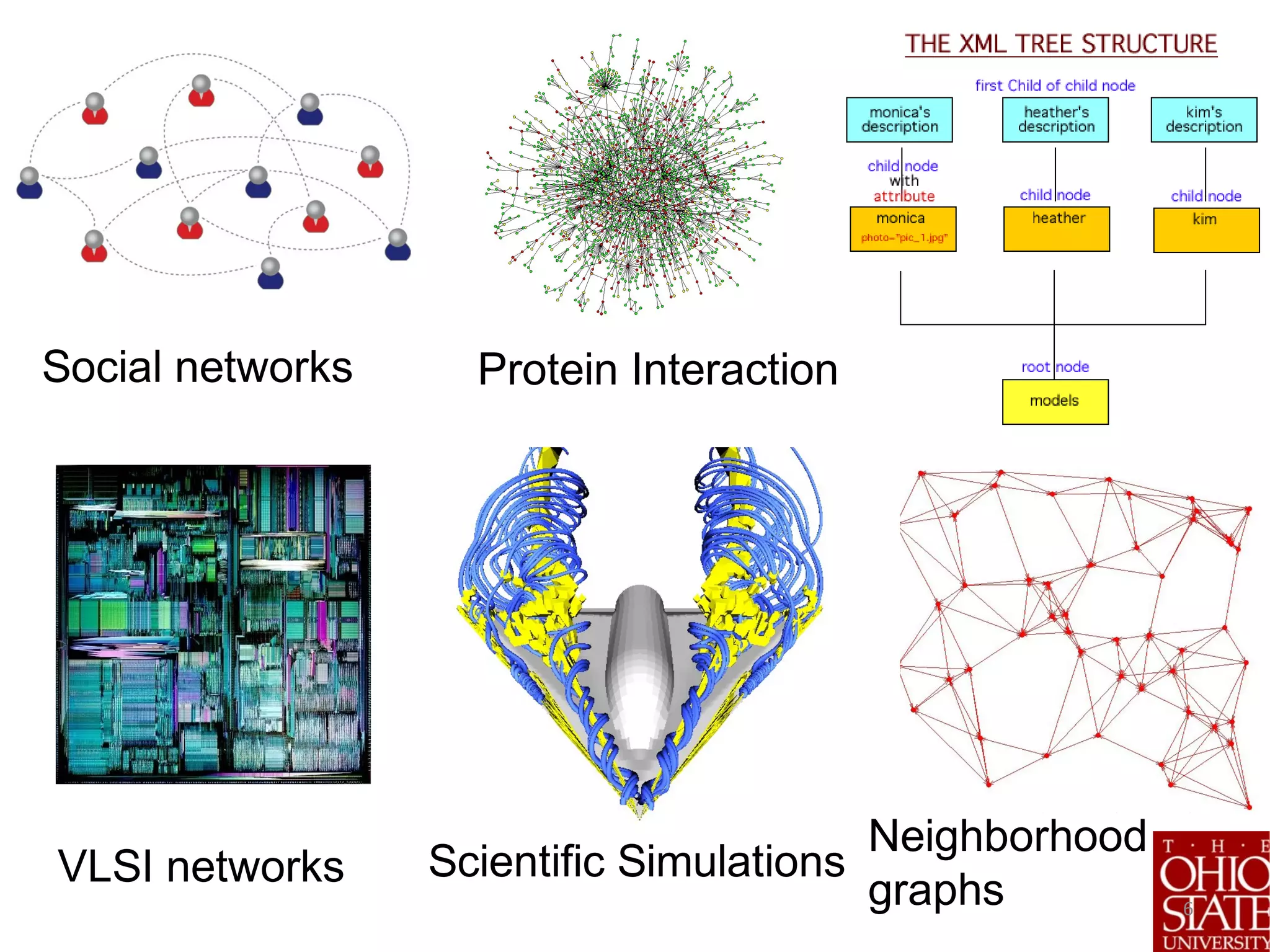
![7
Big Data Challenge: All this data is only useful if we can extract interesting and actionable
information from large complex data stores efficiently
Projected to be a $200B industry in 2020. [IDC report]](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-7-2048.jpg)


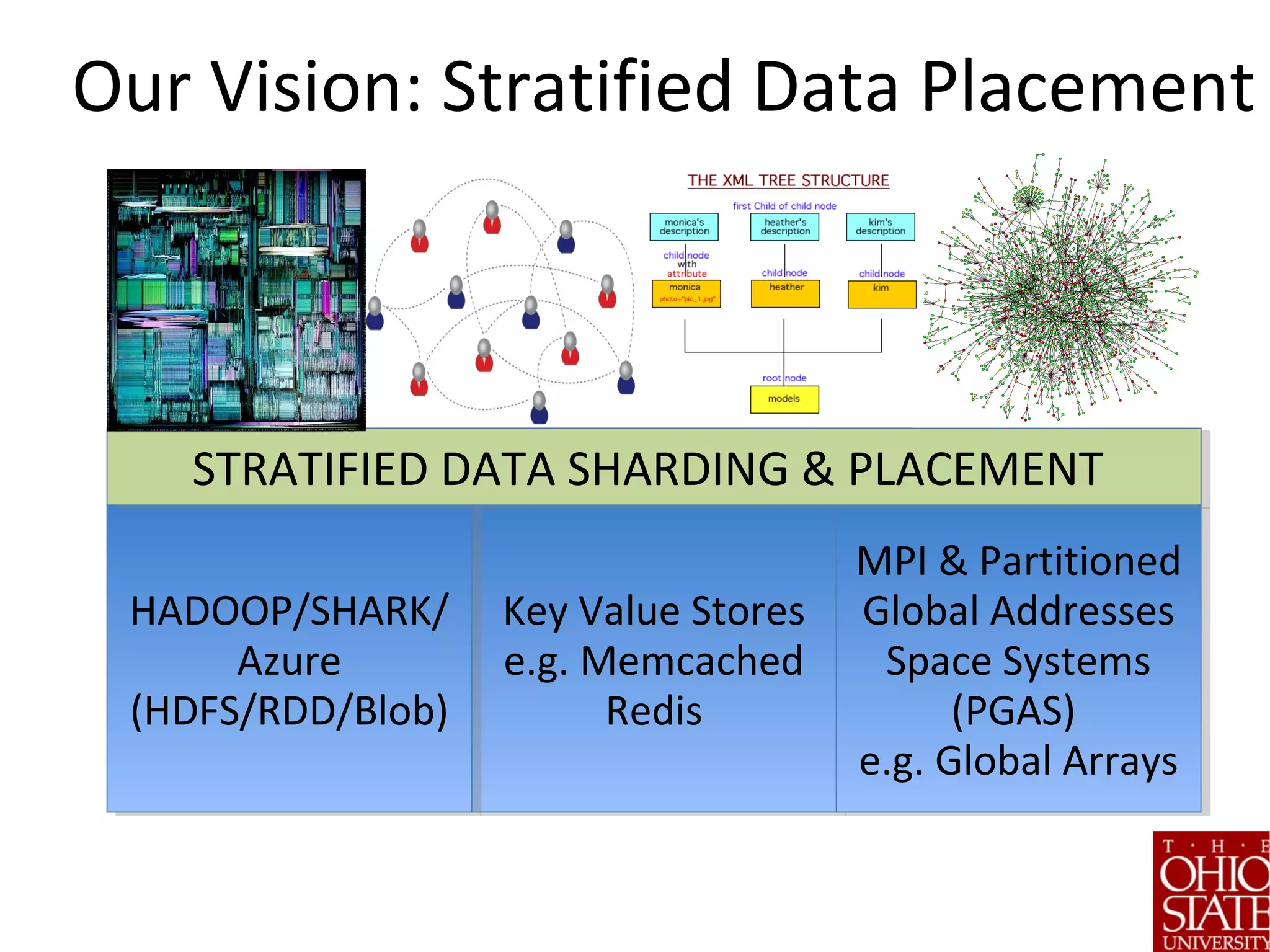

![Key Challenge: Creating Strata
(of Complex Data)
• What about Clustering?
• Non-trivial for data with complex structure
• Potentially expensive
• Variable sized entities
• 4-step approach [ICDE’13; ICDE’15]
1. Pivotization
2. Sketching
3. Stratification
4. Partition according to application needs](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-14-2048.jpg)
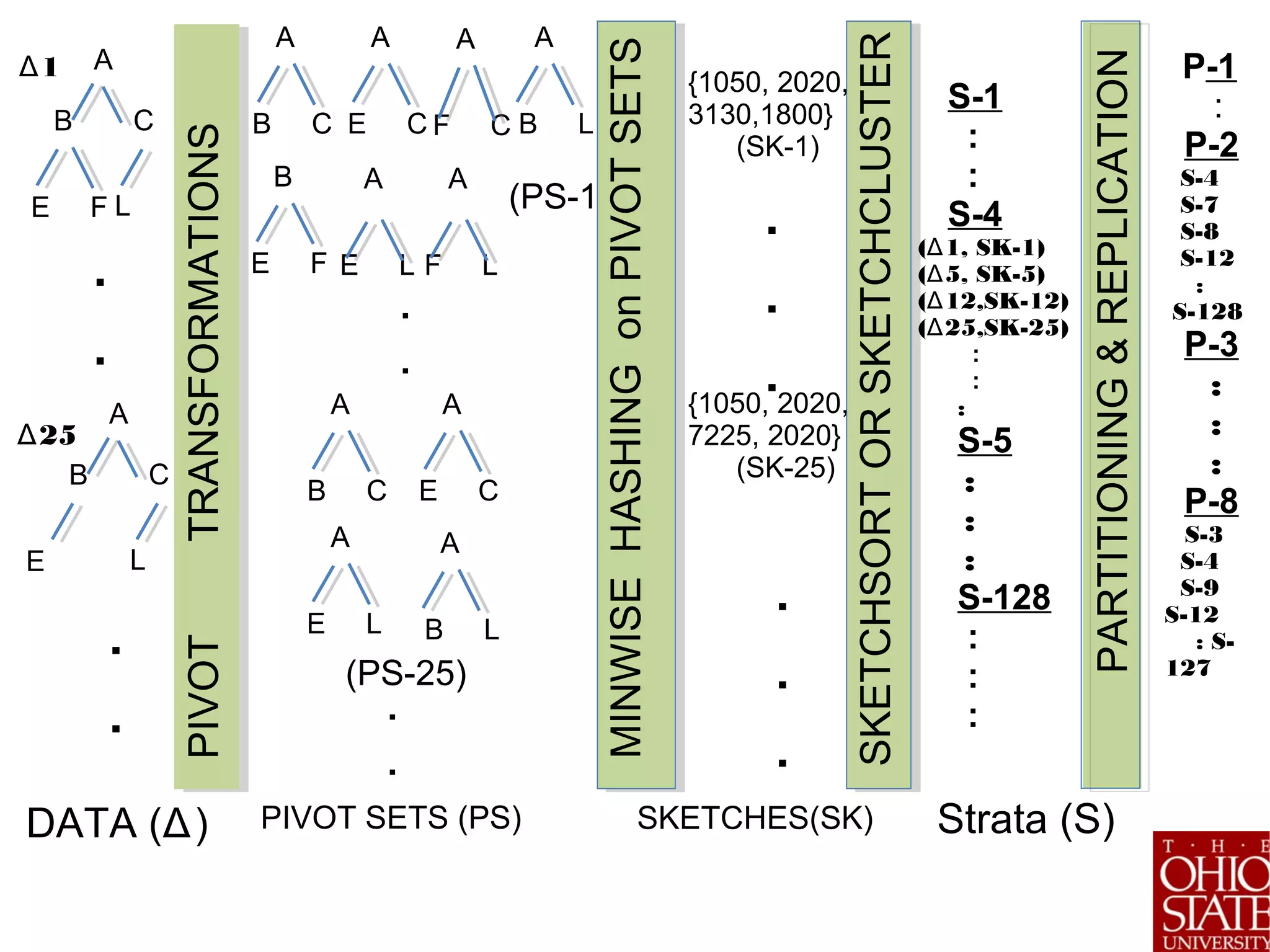
![Step 1: Pivotization
Problem: Need to simplify complex
representation.
Key Idea: Think Globally Act
Locally
– Construct set or vector of local
features that collectively
captures global properties
Solution: Specific to Data & Domain
TEXT SHINGLES (BRODER’98]Spatial/Image Data Kernels/KLSH
(Leslie’03, Kulis’10, Chakrabarti’16]
Graph Pivots (e.g. Adjacency lists [Buehrer’15],
Wedge Decompositions [Seshadri’11], Graphlets [Pruzlj’09])
PIVOTTRANSFORMATIONS
A
B C
LE
A
B C
LE F
.
.
.
.
Δ
1
2Δ
5
DATA (Δ)
A
B C
A
F C
A
E C
A
F L
B
E F
A
E L
A
B L
A
B C
A
E C
A
E L
A
B L
.
.
.
.
(PS-1)
(PS-25)
PIVOT SETS (PS)
Trees (XML, Linguistic data) [Tatikonda’10]](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-15-2048.jpg)
![Step 2. Sketching
• Problem: Pivot sets may be
variable length, similarity
computation is expensive:
O(n^2)
• Key Idea: Use Sketching
• Solution: Locality Sensitive
Hashing [Broder’98, Indyk’99, Charikar’01]
– Resulting representation is fixed-
length (k)
– Tradeoff: Representation Fidelity
vs. Sketch size
– Can handle kernel functions
[Kulis’09] and statistical priors
[Satuluri’12, Chakrabarti’15, ‘16]
A
B C
A
F C
A
E C
A
F L
B
E F
A
E L
A
B L
A
B C
A
E C
A
E L
A
B L
.
.
.
.
(PS-1)
(PS-25)
PIVOT SETS (PS)
MINWISEHASHINGonPIVOTSETS
{1050, 2020,
3130,1800}
(SK-1)
{1050, 2020,
7225, 2020}
(SK-25)
.
.
.
.
.
.
SKETCHES(SK)](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-16-2048.jpg)

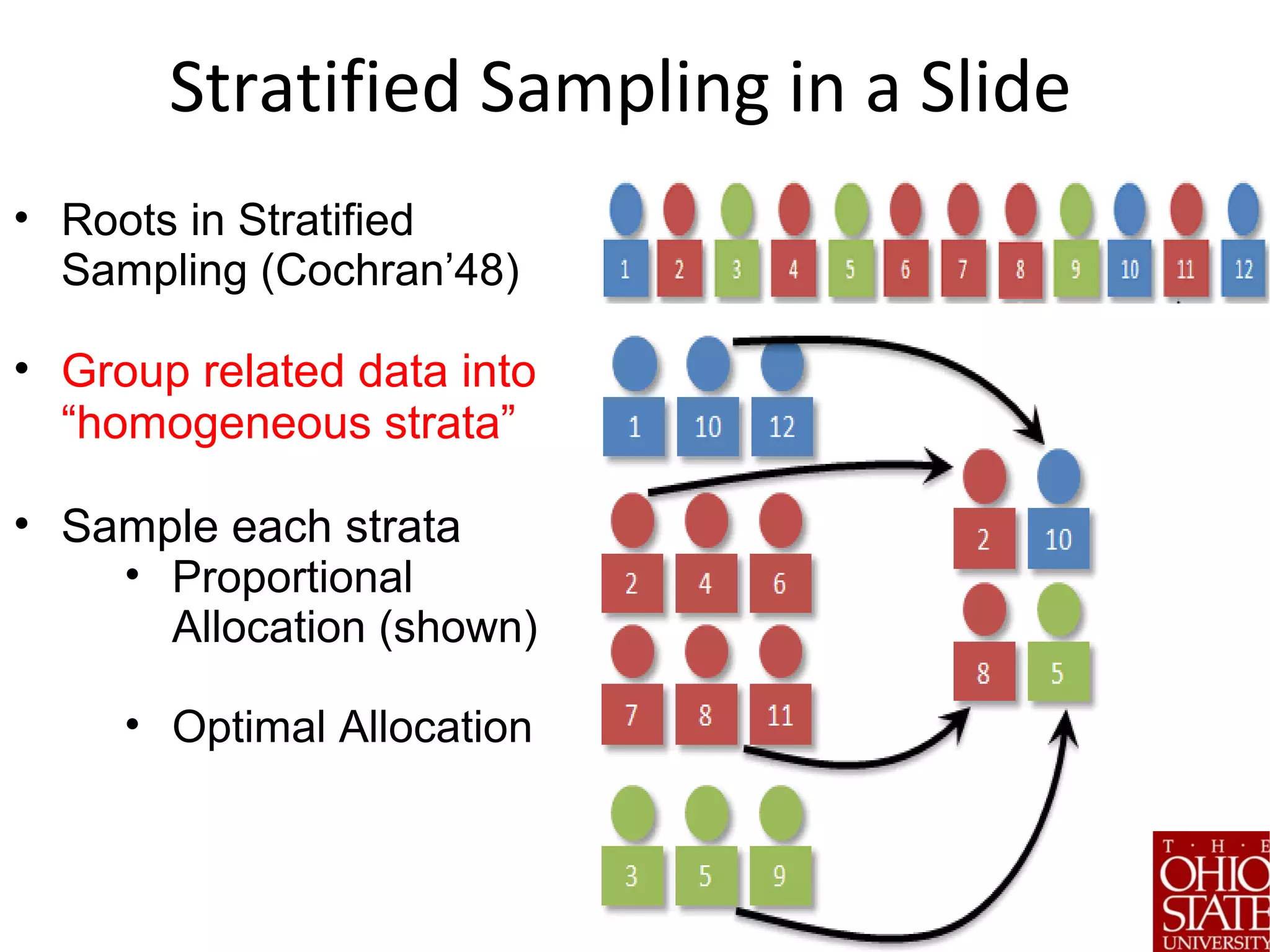
![Step 3: Stratification
Problem: Group related entities
into strata
Key Idea: Inspired by W.
Cochran’s work on stratified
sampling [1940s]
Solutions:
•Sort pivot sets directly (skip sketch
step) – Pivot Sort
•Directly use output of LSH/Minwise
Hash – SketchSort
•Cluster sketches with fast variant of k-
modes – SketchCluster
SKETCHSORTorSKETCHCLUSTER
S-1
:
:
S-4
( 1, SK-1)Δ
( 5, SK-5)Δ
( 12,SK-12)Δ
( 25,SK-25)Δ
:
:
:
S-5
:
:
:
S-128
:
:
:
MINWISEHASHINGonPIVOTSETS
{1050, 2020,
3130,1800}
(SK-1)
{1050, 2020,
7225, 2020}
(SK-25)
.
.
.
.
.
.
SKETCHES(SK)](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-18-2048.jpg)
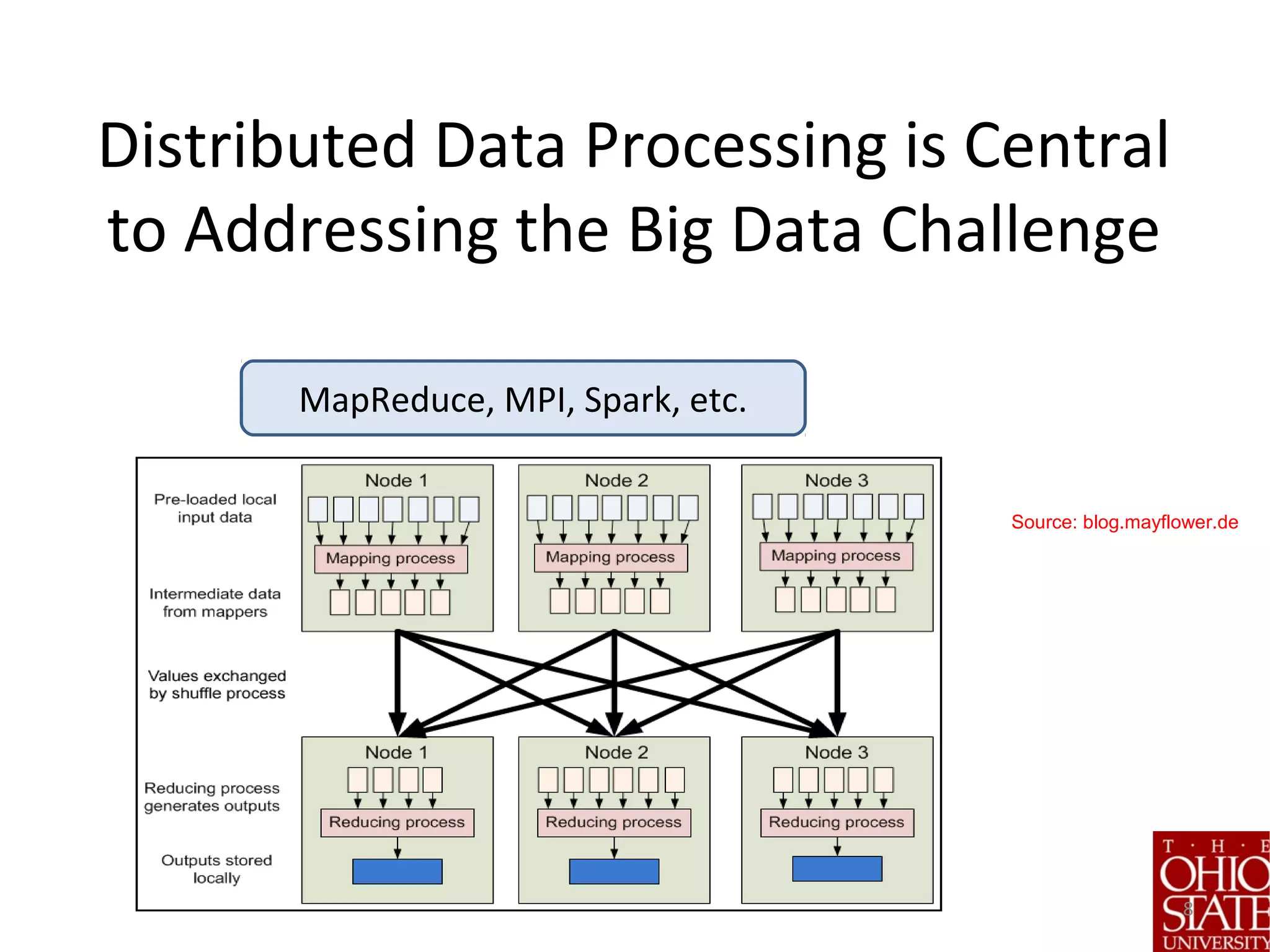
![Step 4: Sharding and Placement
• Problem: How to partition stratified data?
• Key Ideas: Guided by application hints and system state.
• Solutions:
1. Proportional Allocation: Split each stratum uniformly
proportionally across all partitions mitigates skew
1. Optimal Allocation for first strata, proportional for
rest [C77]
1. All-in-One : Place each stratum in its entirety within a
partition
IMPORTANT NOTE: We use sketches to create strata – but
partitioning happens on original data.](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-19-2048.jpg)
![Empirical Evaluation
• We report wall clock times
• All times include cost of placement
• Evaluations on several key analytic tasks
• Top-K algorithms [Fagin], Outlier Detection [Ghoting’08, Otey’06],
Frequent Tree[Zaki’05, Tatikonda’09] and Graph Mining [Buehrer’06,
Yan’02, Nijlsson’04], XML Indexing [Tatikonda’07], Community
detection in Social/Biological data [Ucar’06, Satuluri’11], Web Graph
Compression [Chellapilla’08-09; Vigna’11, LZ’77], Itemset Mining
[Buehrer-Fuhry’15]
• All applications are run straight out of the box – the only thing
the user specifies relates to locality, skew, and interaction.](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-21-2048.jpg)
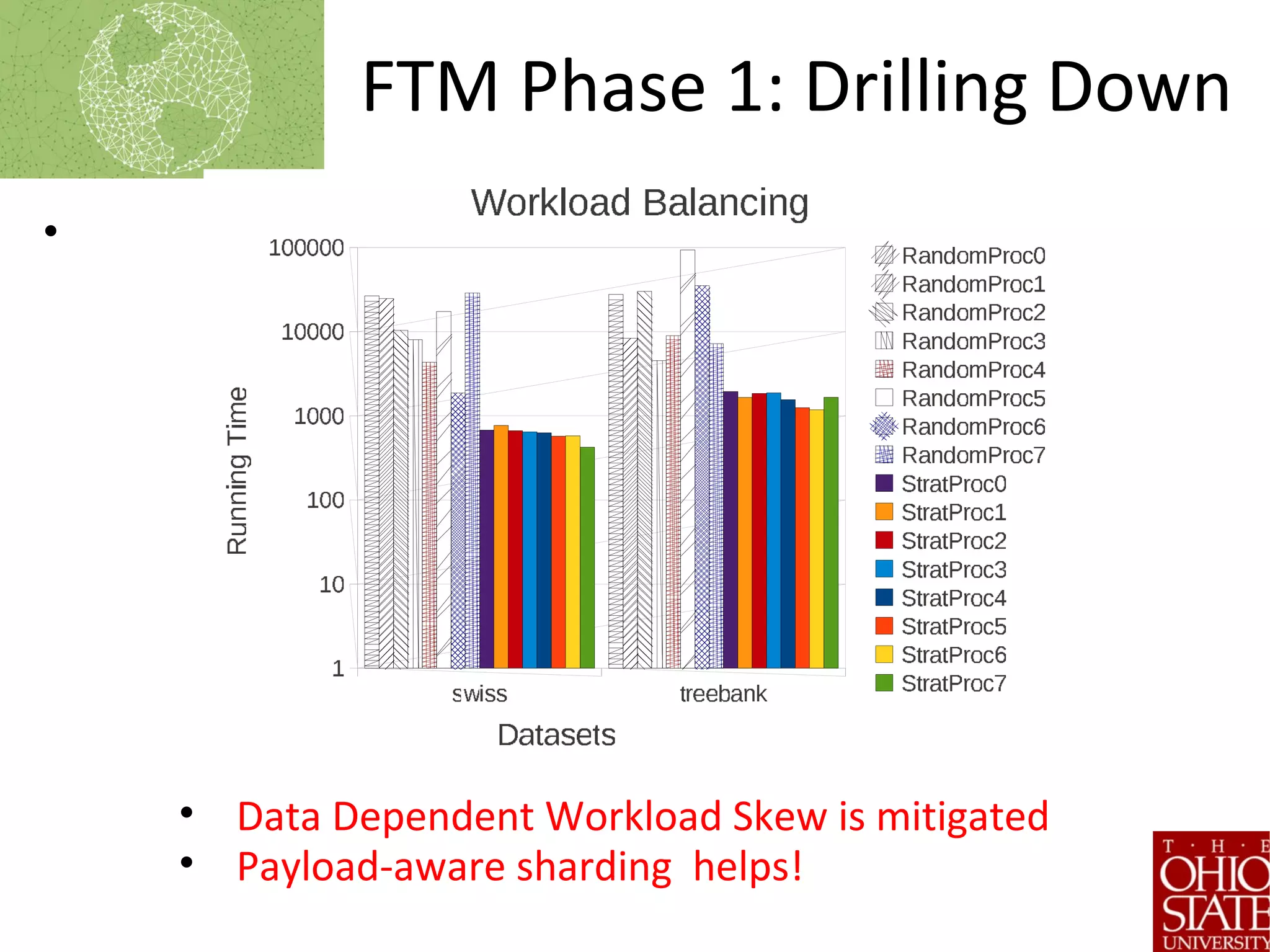
![Frequent Tree Mining
[Tatikonda’09]
• Used Widely
– Transactions, graphs, trees
• Approach
1. Distribute Data
• Proportional
Allocation
1. Run Phase 1
2. Exchange Meta Data
3. Run Phase 2
4. Final Reduction
• Sharding mainly impacts steps
1-3. Steps 3 and 5 are
sequential.
Proposed approaches shows 100X gains](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-22-2048.jpg)
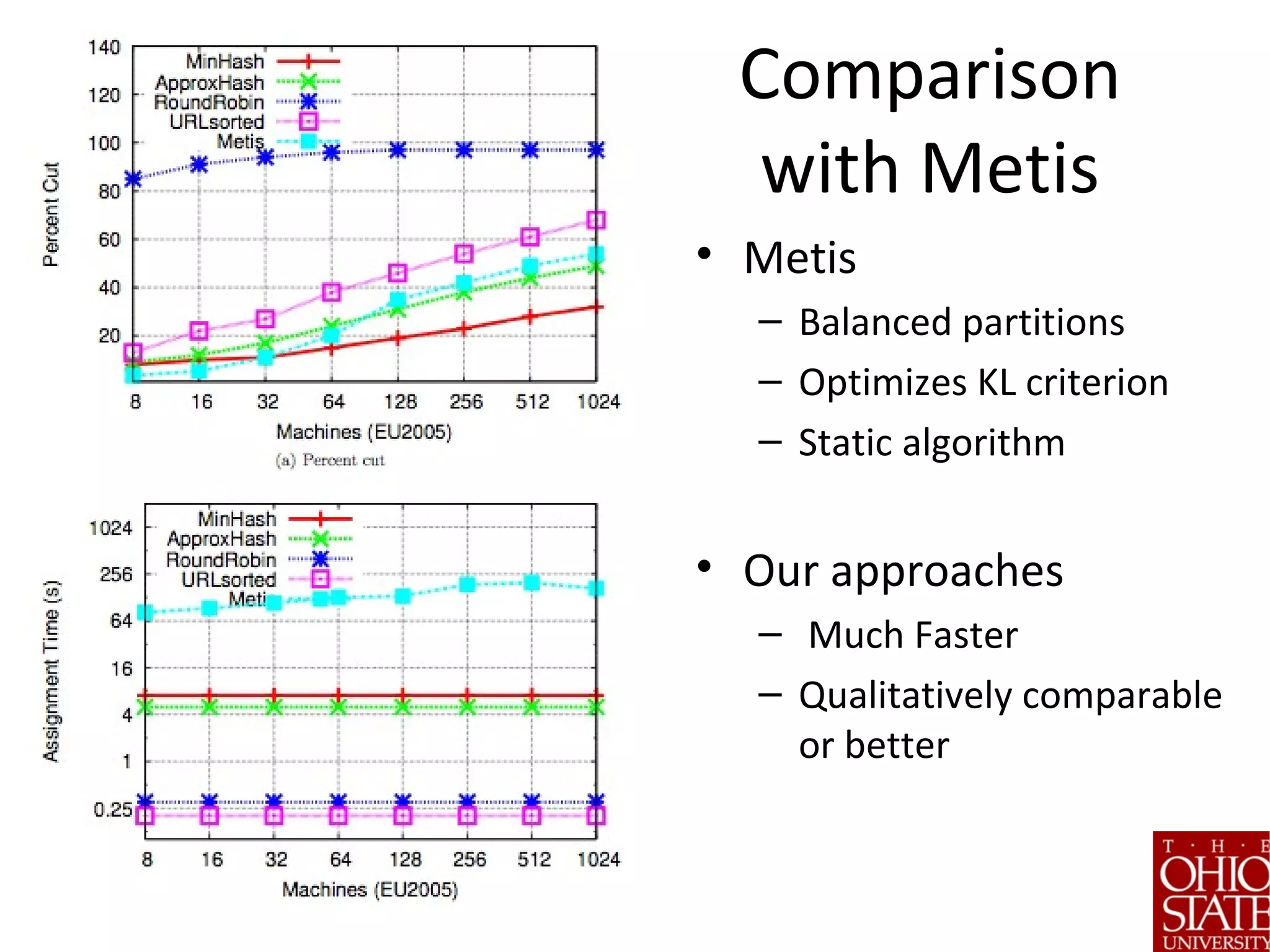
![WebGraph Compression [Vigna et
al 2011]
Critical application for search
companies
Key Requirement: Locality
Approach:
• Distribute data via placement
• Run compression algorithm
in parallel
• Parameters (similar to FTM)
– Use adjacency/triangle pivots
– Use All-in-one partitioning](https://image.slidesharecdn.com/stratifiedshardingforai-parthasarathy-190217001325/75/Scalable-Machine-Learning-The-Role-of-Stratified-Data-Sharding-24-2048.jpg)

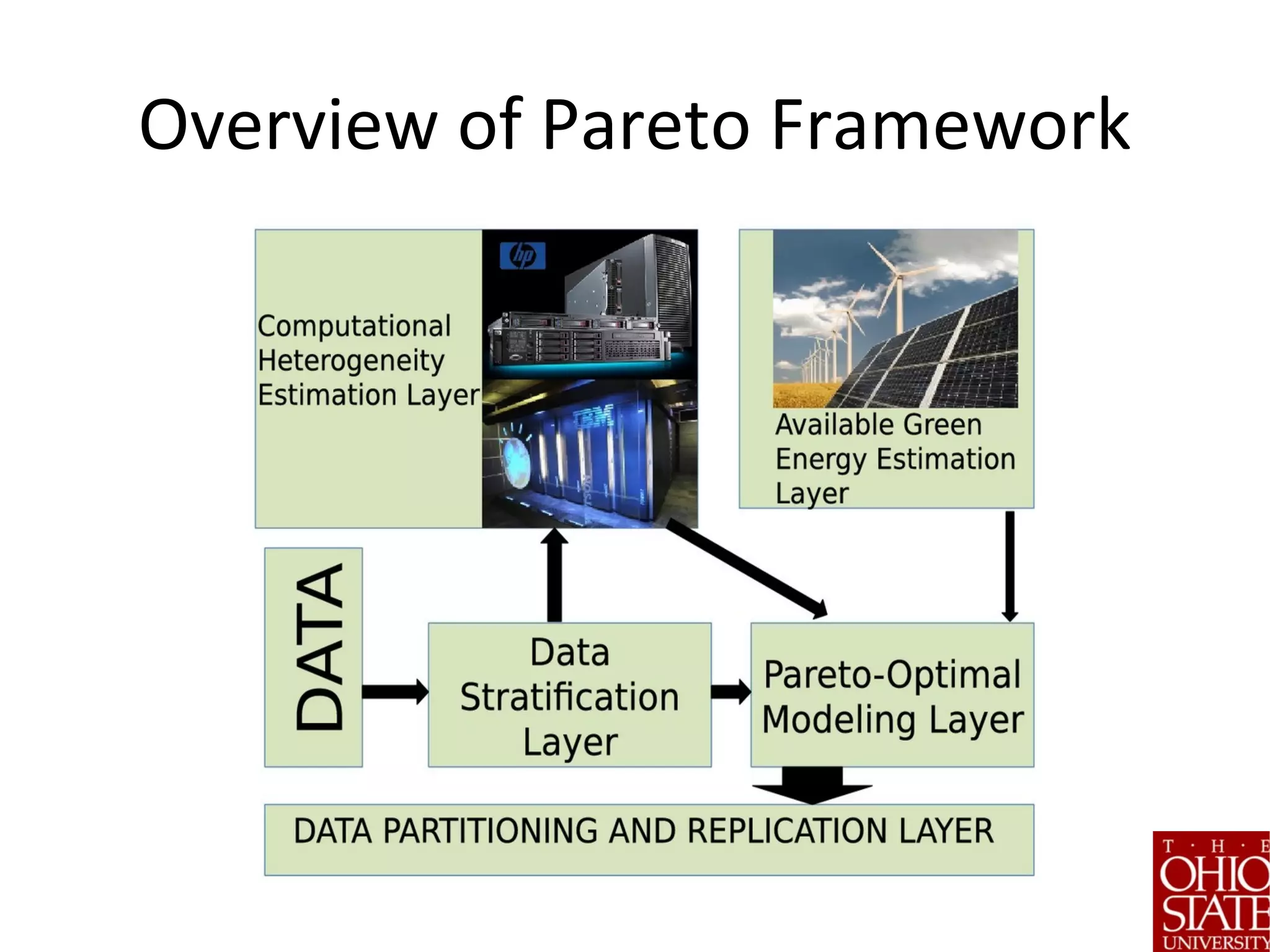
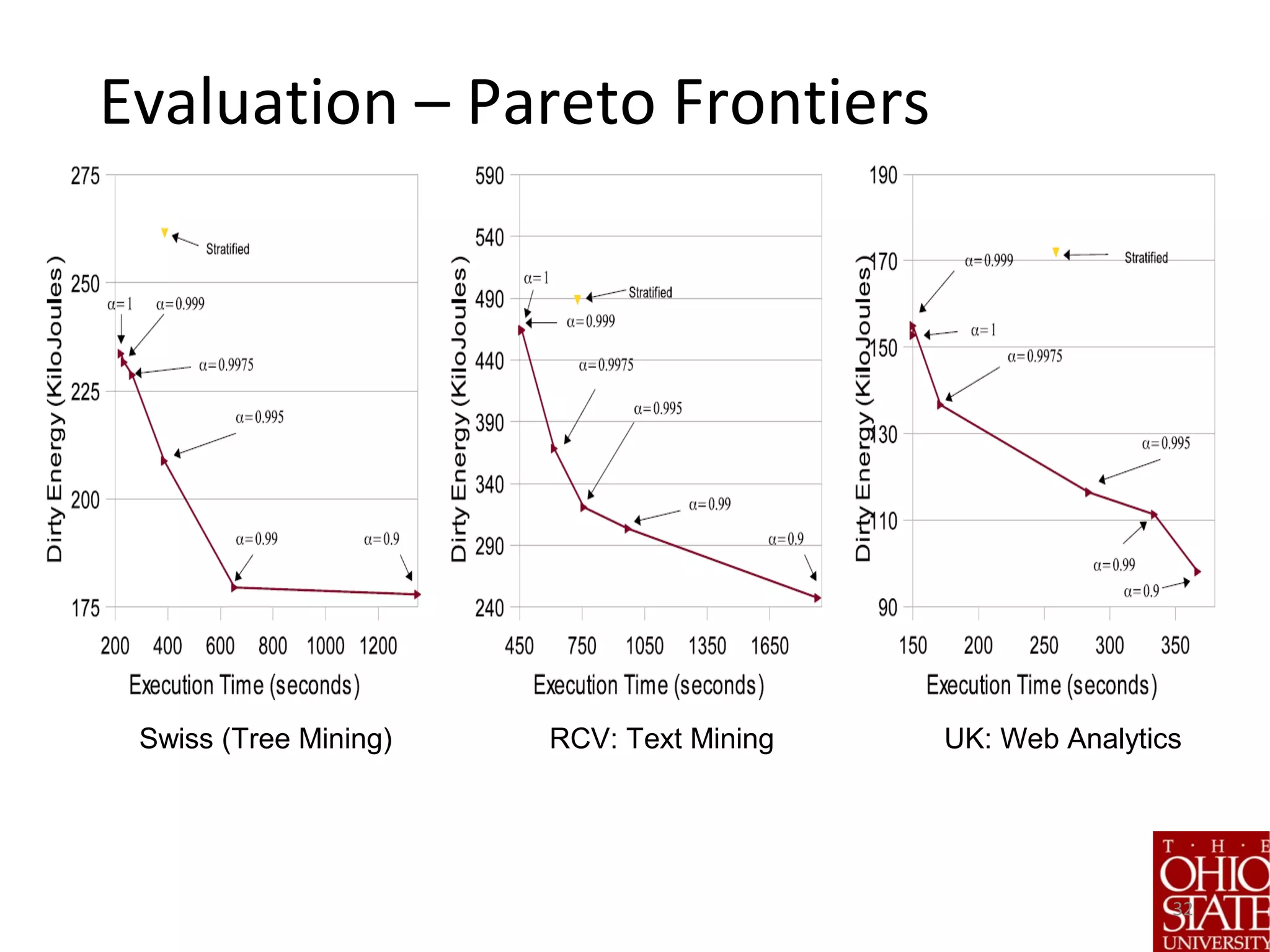
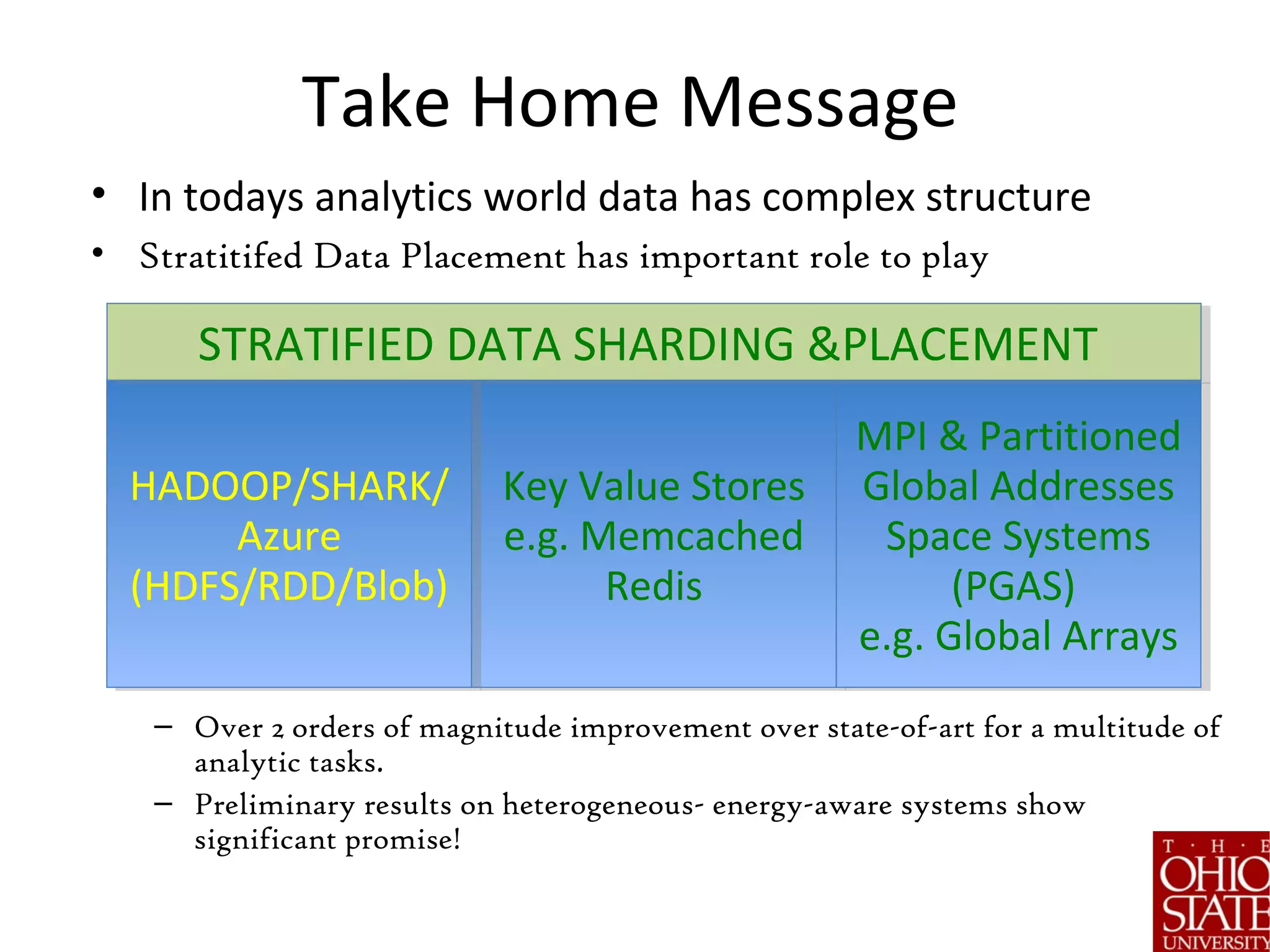


The document discusses the role of stratified data sharding in addressing the challenges of big data, including locality of reference, data skew, and interactive response times. It outlines a four-step approach to data handling: pivotization, sketching, stratification, and sharding, emphasizing the importance of optimizing data placement for varied application needs. Preliminary results indicate that this method leads to significant performance improvements in analytic tasks across heterogeneous computing environments.




































































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



