Downloaded 108 times













![#EUds5
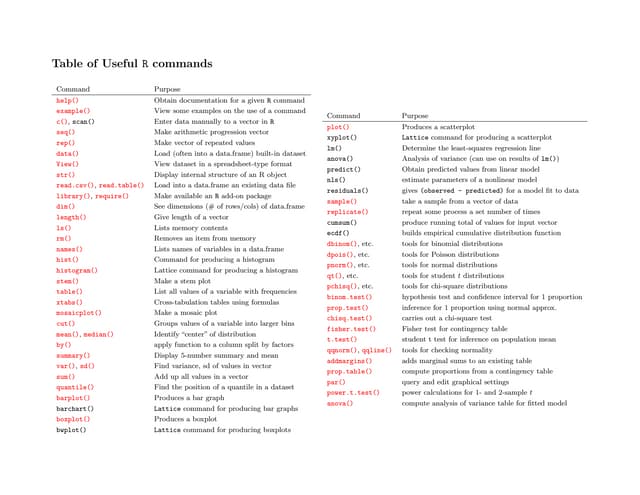
Training self-organizing maps
12
while t < maxupdates:
random.shuffle(examples)
for ex in examples:
t = t + 1
if t == maxupdates:
break
bestMatch = closest(somt, ex)
for (unit, wt) in neighborhood(bestMatch, sigma(t)):
somt+1[unit] = somt[unit] + (ex - somt[unit]) * alpha(t) * wt](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-14-320.jpg)
![#EUds5
Training self-organizing maps
12
while t < maxupdates:
random.shuffle(examples)
for ex in examples:
t = t + 1
if t == maxupdates:
break
bestMatch = closest(somt, ex)
for (unit, wt) in neighborhood(bestMatch, sigma(t)):
somt+1[unit] = somt[unit] + (ex - somt[unit]) * alpha(t) * wt
process the training
set in random order](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-15-320.jpg)
![#EUds5
Training self-organizing maps
12
while t < maxupdates:
random.shuffle(examples)
for ex in examples:
t = t + 1
if t == maxupdates:
break
bestMatch = closest(somt, ex)
for (unit, wt) in neighborhood(bestMatch, sigma(t)):
somt+1[unit] = somt[unit] + (ex - somt[unit]) * alpha(t) * wt
process the training
set in random order
the neighborhood size controls
how much of the map around
the BMU is affected](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-16-320.jpg)
![#EUds5
Training self-organizing maps
12
while t < maxupdates:
random.shuffle(examples)
for ex in examples:
t = t + 1
if t == maxupdates:
break
bestMatch = closest(somt, ex)
for (unit, wt) in neighborhood(bestMatch, sigma(t)):
somt+1[unit] = somt[unit] + (ex - somt[unit]) * alpha(t) * wt
process the training
set in random order
the neighborhood size controls
how much of the map around
the BMU is affected
the learning rate controls
how much closer to the
example each unit gets](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-17-320.jpg)




![#EUds5
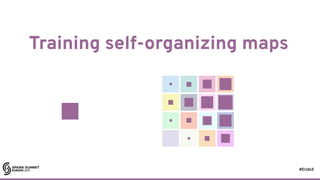
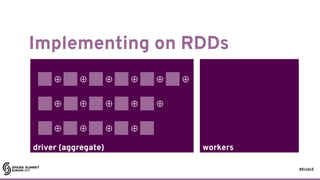
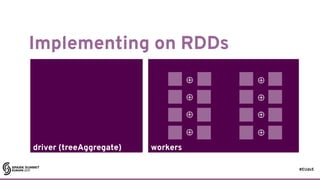
What forces serial execution?
17
state[t+1] =
combine(state[t], x)](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-22-320.jpg)
![#EUds5
What forces serial execution?
18
state[t+1] =
combine(state[t], x)](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-23-320.jpg)























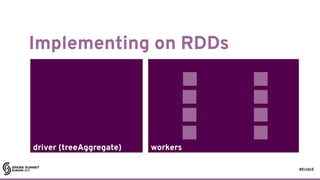
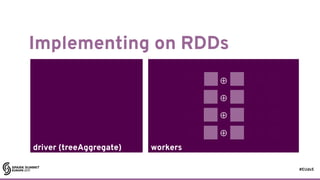
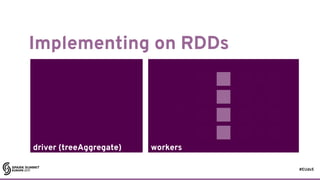
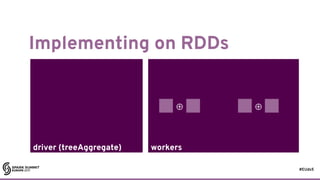



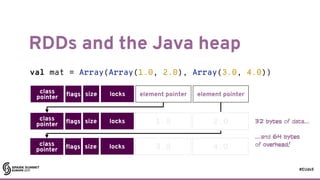
![#EUds5
RDDs: some good parts
47
val rdd: RDD[String] = /* ... */
rdd.map(_ * 3.0).collect()
val df: DataFrame = /* data frame with one String-valued column */
df.select($"_1" * 3.0).show()](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-56-320.jpg)
![#EUds5
RDDs: some good parts
48
val rdd: RDD[String] = /* ... */
rdd.map(_ * 3.0).collect()
val df: DataFrame = /* data frame with one String-valued column */
df.select($"_1" * 3.0).show()
doesn’t compile](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-57-320.jpg)
![#EUds5
RDDs: some good parts
49
val rdd: RDD[String] = /* ... */
rdd.map(_ * 3.0).collect()
val df: DataFrame = /* data frame with one String-valued column */
df.select($"_1" * 3.0).show()
doesn’t compile](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-58-320.jpg)
![#EUds5
RDDs: some good parts
50
val rdd: RDD[String] = /* ... */
rdd.map(_ * 3.0).collect()
val df: DataFrame = /* data frame with one String-valued column */
df.select($"_1" * 3.0).show()
doesn’t compile
crashes at runtime](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-59-320.jpg)










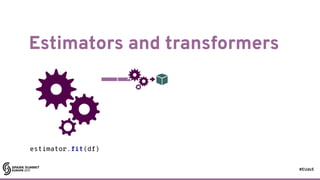
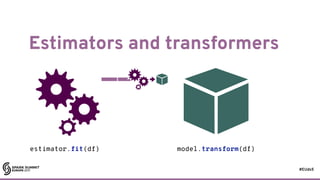
![#EUds5
Defining parameters
65
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-76-320.jpg)
![#EUds5
Defining parameters
66
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-77-320.jpg)
![#EUds5
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...
Defining parameters
67
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-78-320.jpg)
![#EUds5
Defining parameters
68
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-79-320.jpg)
![#EUds5
Defining parameters
69
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-80-320.jpg)
![#EUds5
Defining parameters
70
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...
private[som] trait SOMParams extends Params
with DefaultParamsWritable {
final val x: IntParam =
new IntParam(this, "x", "width of self-organizing map (>= 1)",
ParamValidators.gtEq(1))
final def getX: Int = $(x)
final def setX(value: Int): this.type = set(x, value)
// ...](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-81-320.jpg)
![#EUds5
Don’t repeat yourself
71
/**
* Common params for KMeans and KMeansModel
*/
private[clustering] trait KMeansParams extends Params
with HasMaxIter with HasFeaturesCol
with HasSeed with HasPredictionCol with HasTol { /* ... */ }](https://image.slidesharecdn.com/lb5williambenton-171031212144/85/Building-Machine-Learning-Algorithms-on-Apache-Spark-with-William-Benton-82-320.jpg)















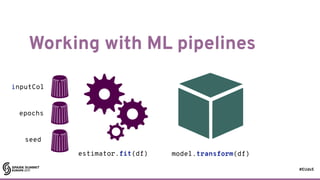
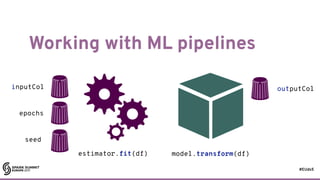
The document discusses building machine learning algorithms on Apache Spark, focusing on self-organizing maps (SOMs) and their practical implementation in parallel environments. It covers techniques for training SOMs using partitioned collections, with essential considerations on the learning rate and neighborhood size. Additionally, it explores the transition from RDDs to DataFrames and ML pipelines, highlighting methods for efficiently processing data and evolving models in a distributed architecture.