Downloaded 22 times


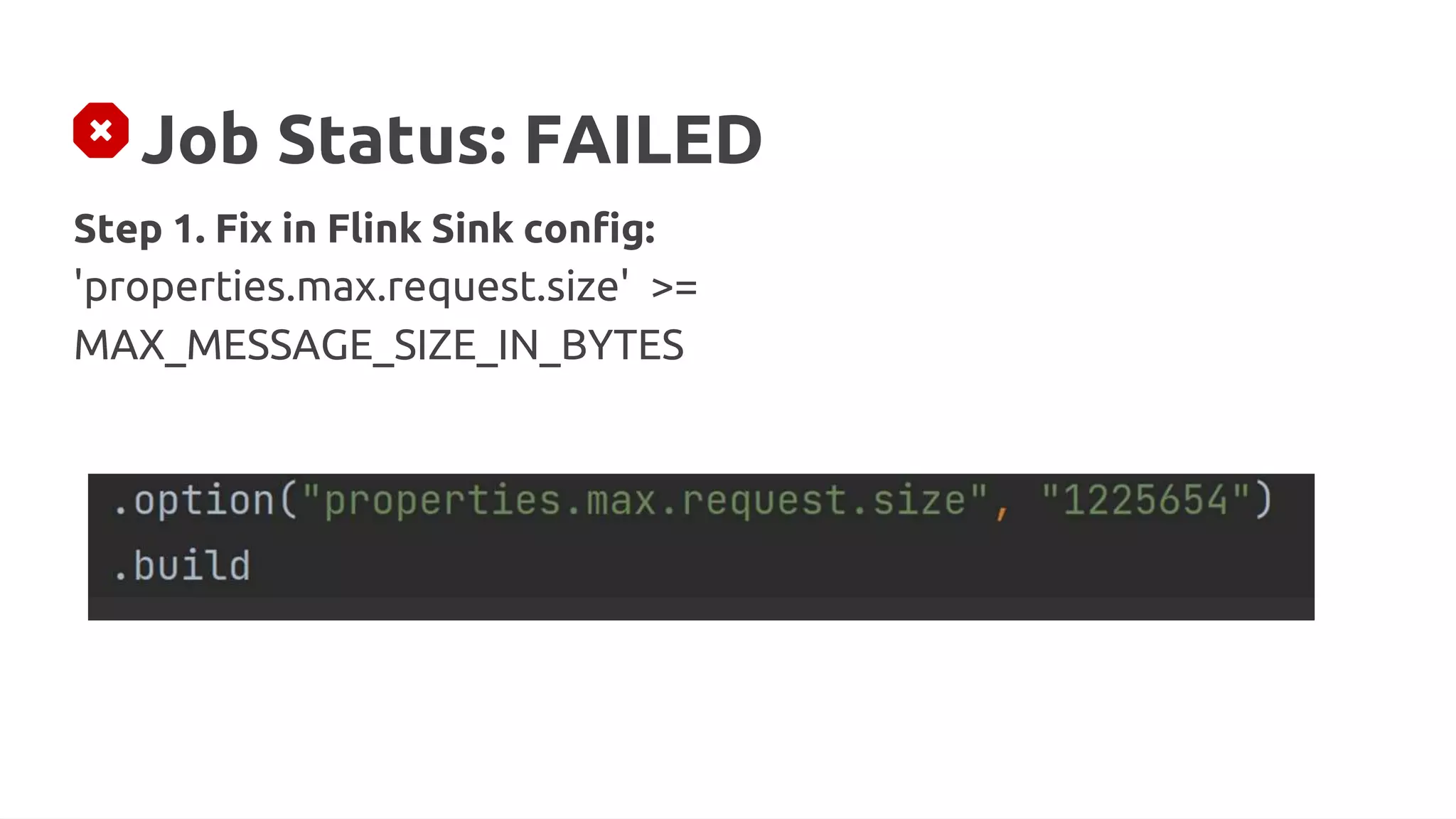
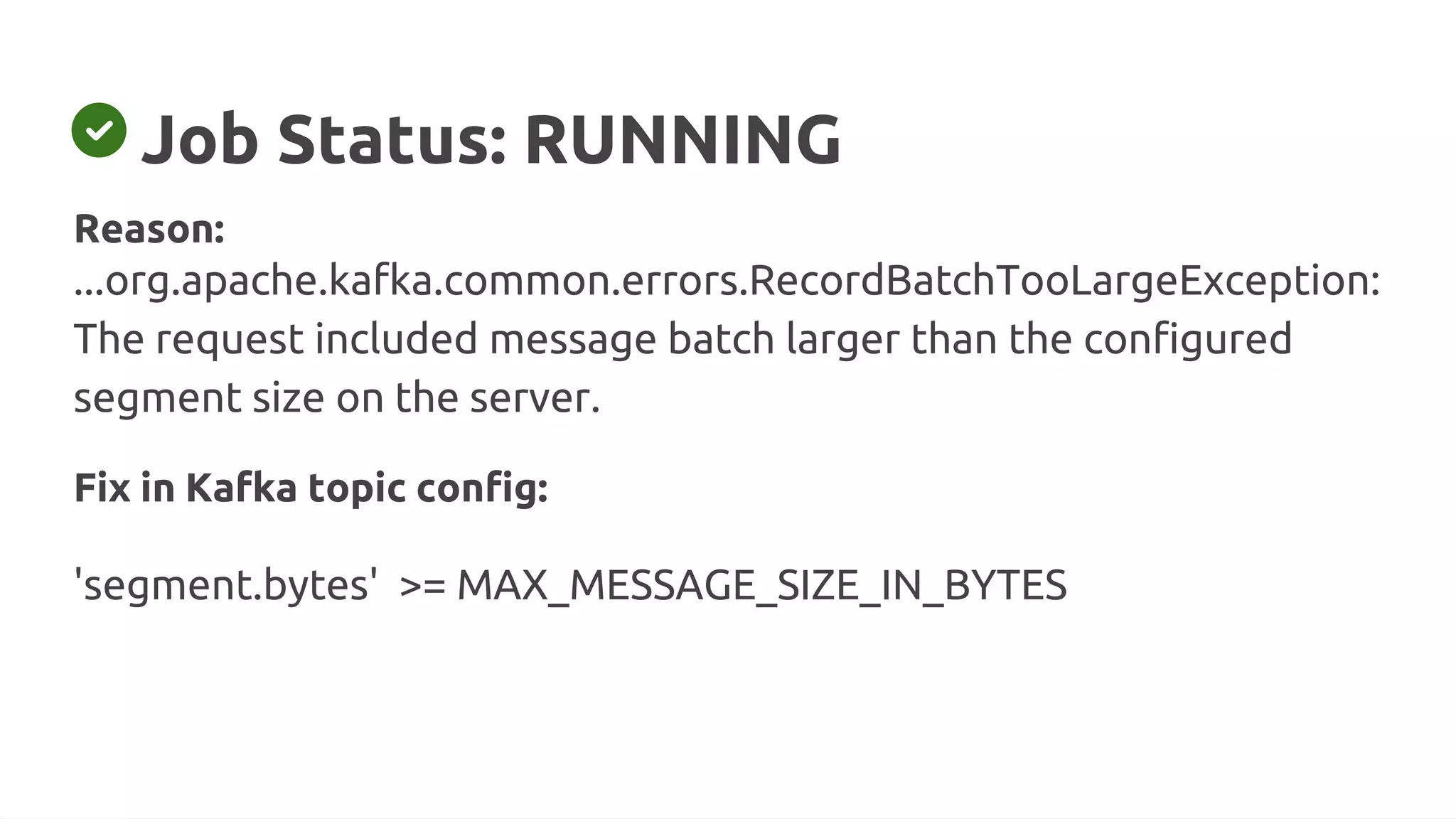
![Job Status: FAILED
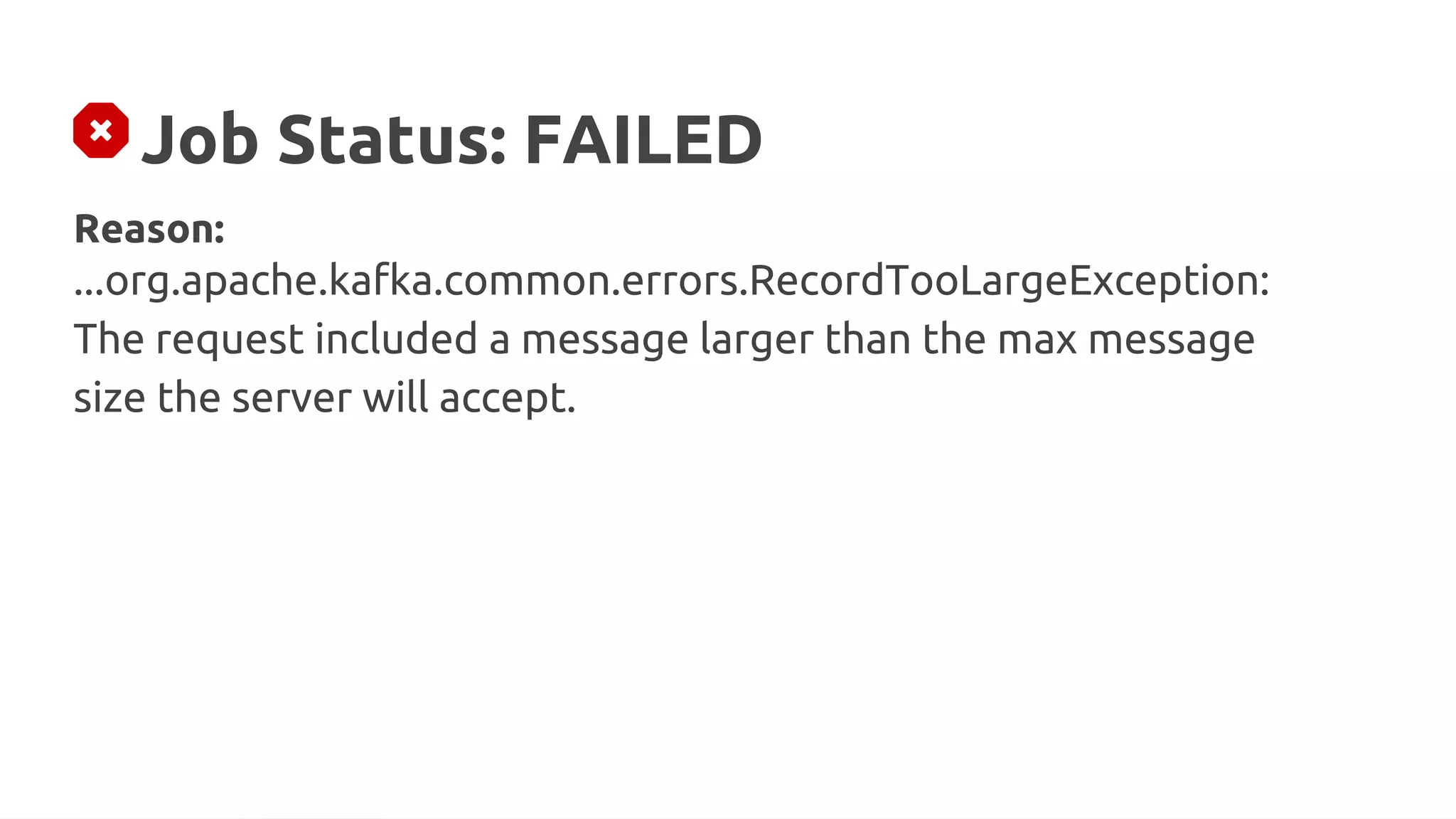
Reason:
...org.apache.kafka.common.errors.RecordTooLargeException:
The message is [X] bytes when serialized which is larger than [Y]](https://image.slidesharecdn.com/315pmtuningapachekafkaconnectorsforflinkobabenko-220809121057-9b32c89f/75/Tuning-Apache-Kafka-Connectors-for-Flink-pptx-3-2048.jpg)











![Job Status: FINISHED
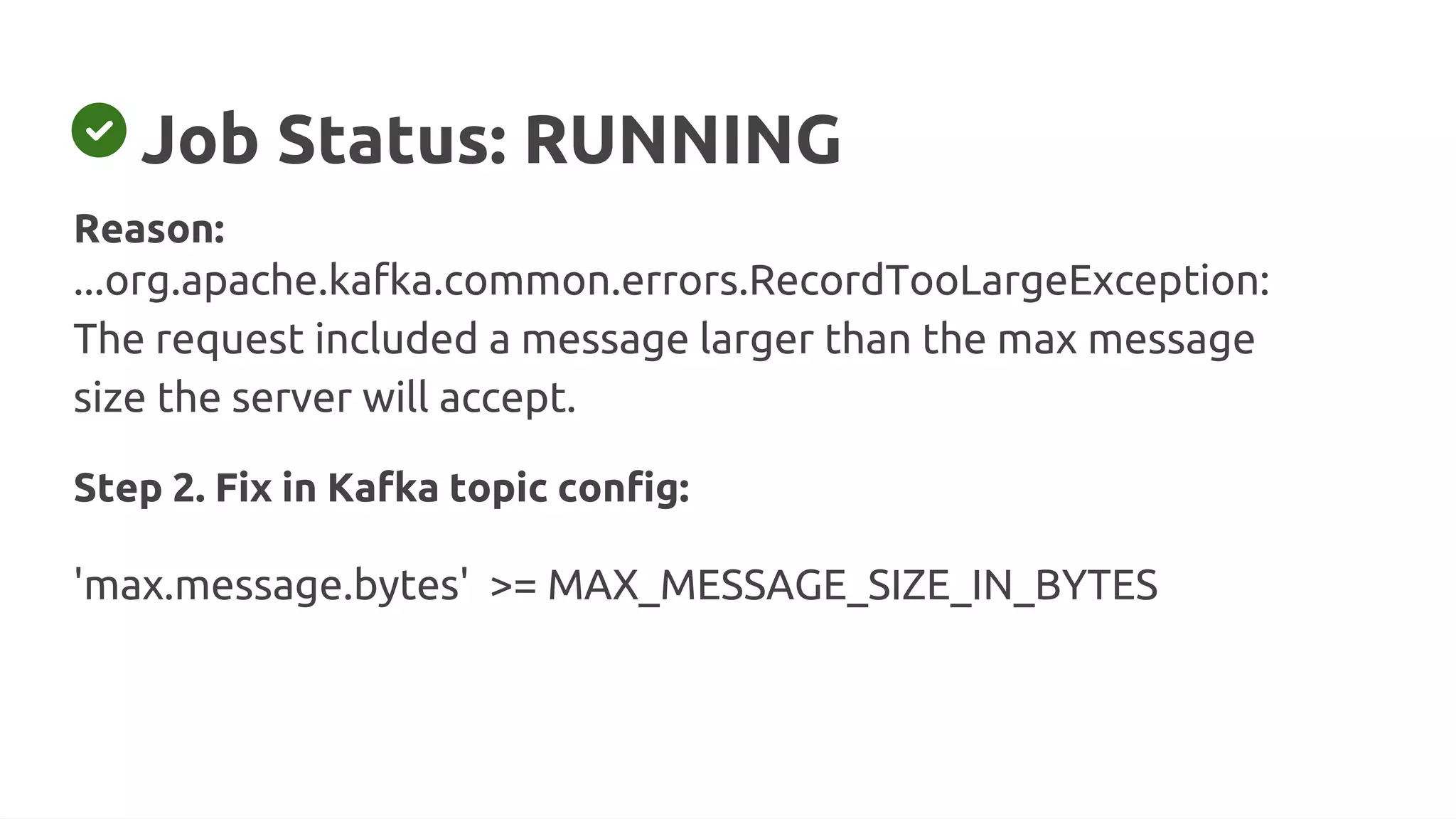
Fix in Flink Sink Config:
'properties.compression.type' = 'snappy' ['gzip', 'lz4', 'zstd']
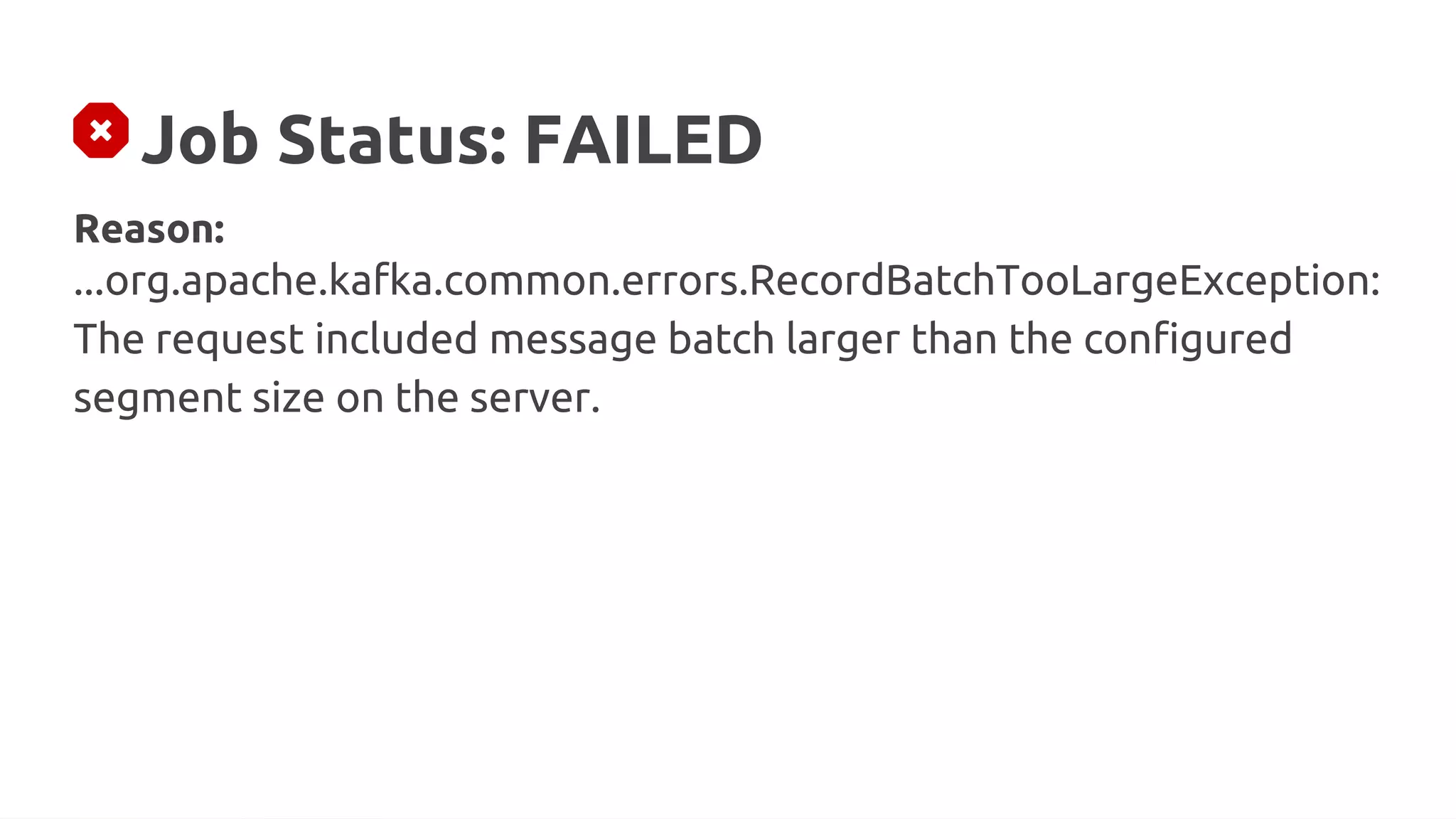
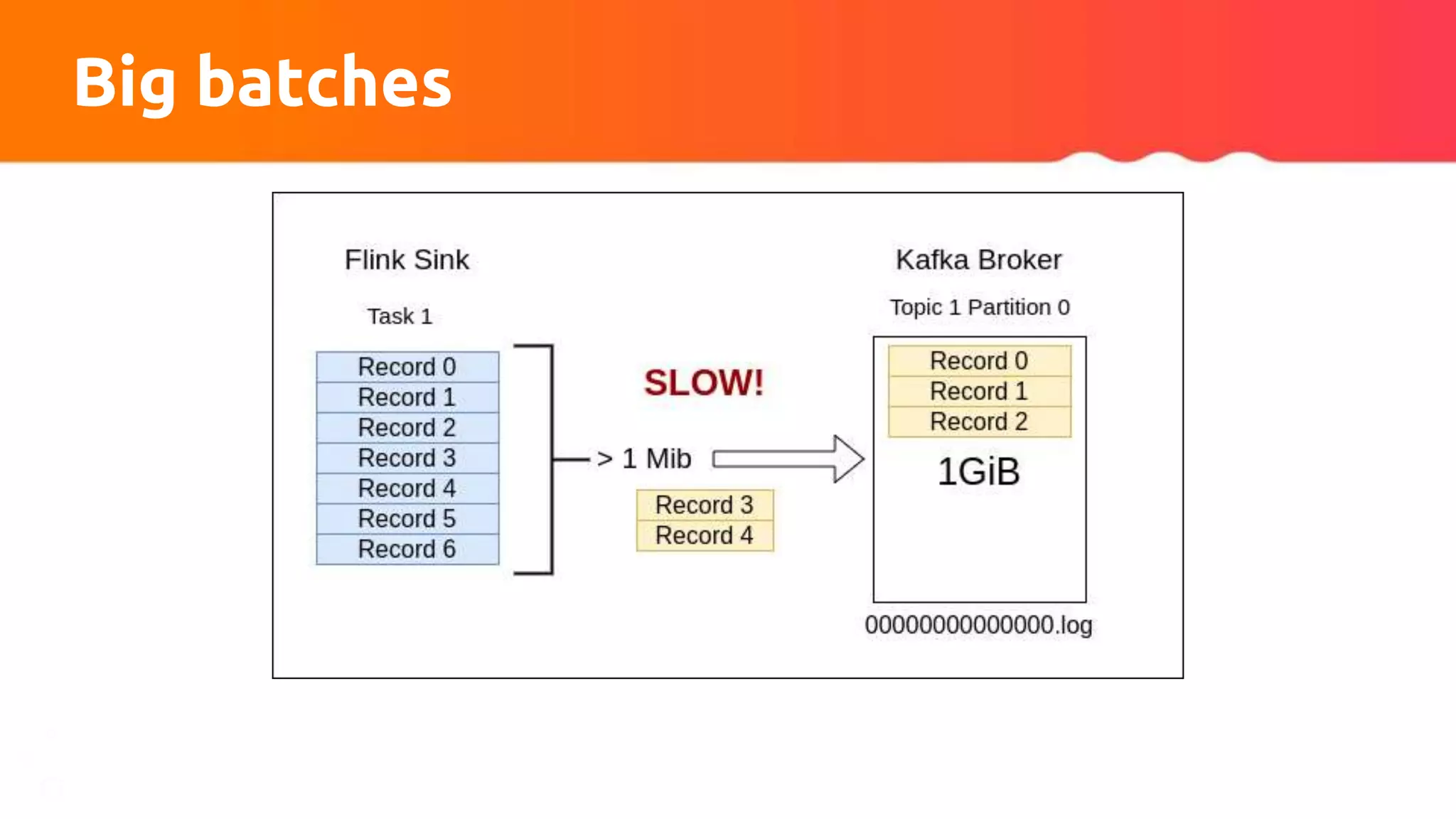
Reason:
...WARN...org.apache.kafka.clients.producer.internals.Sender - Got
error produce response in correlation id 137 on topic-partition
response-0, splitting and retrying (2147483647 attempts left).
Error: MESSAGE_TOO_LARGE](https://image.slidesharecdn.com/315pmtuningapachekafkaconnectorsforflinkobabenko-220809121057-9b32c89f/75/Tuning-Apache-Kafka-Connectors-for-Flink-pptx-23-2048.jpg)


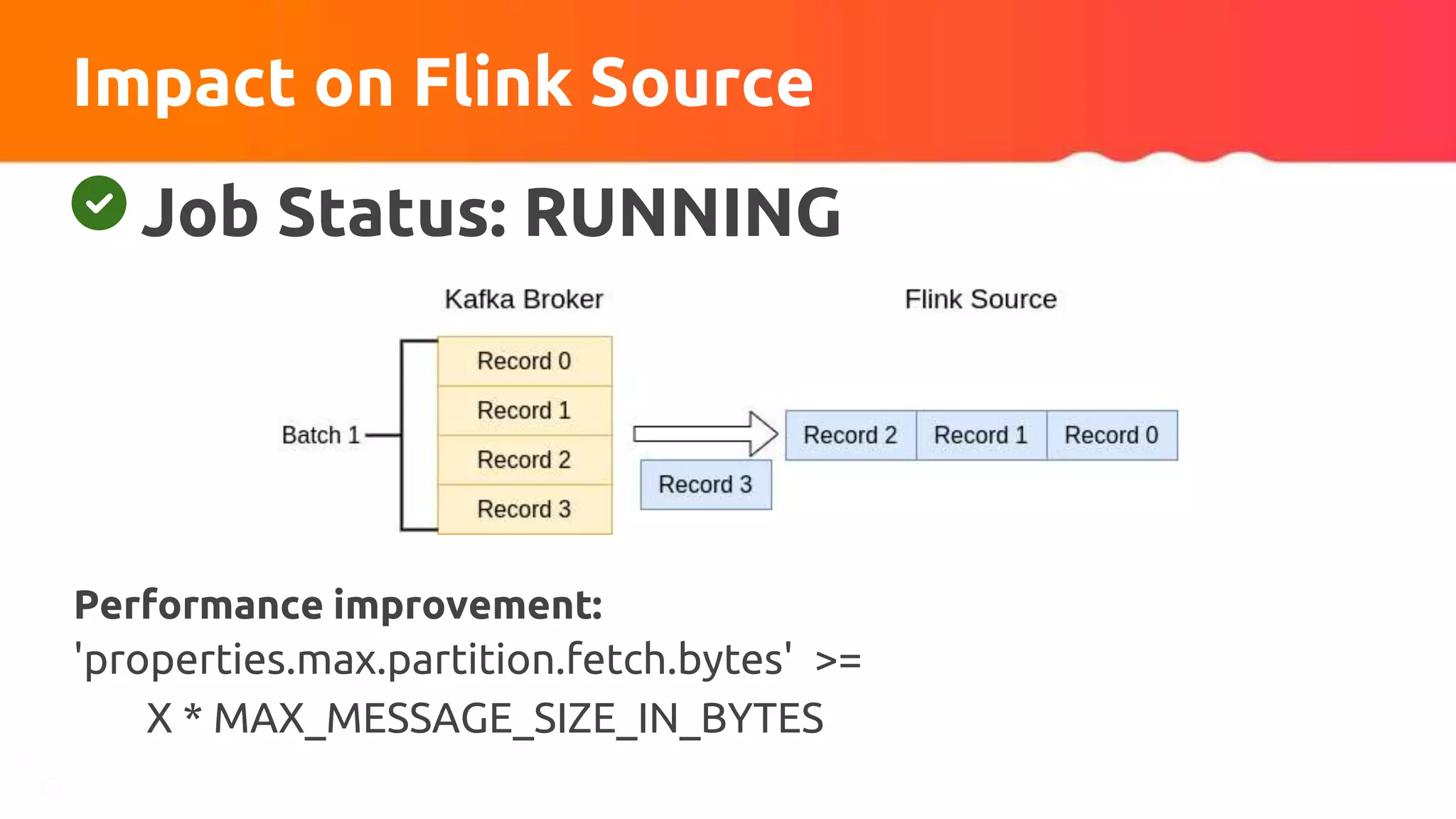

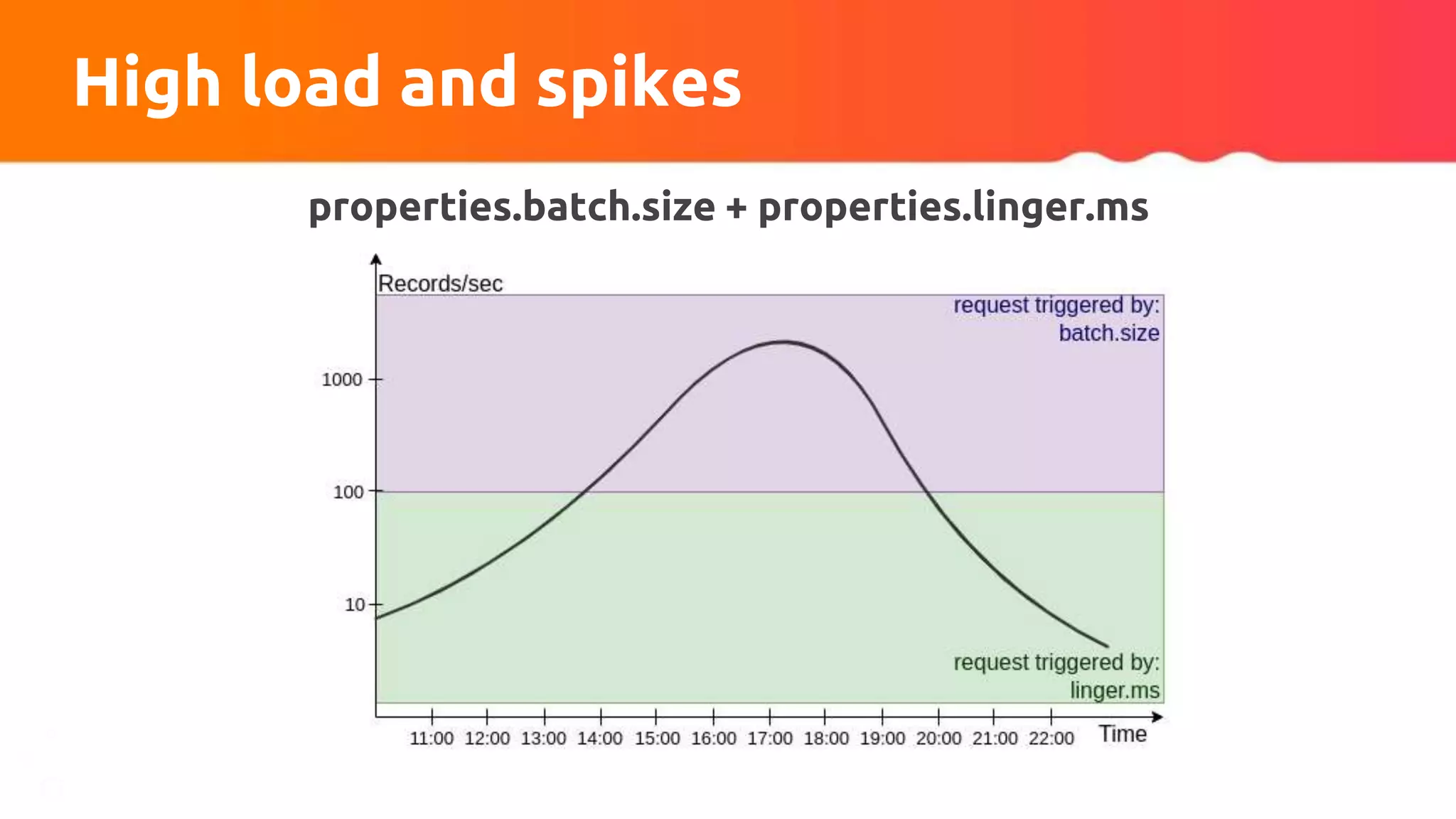
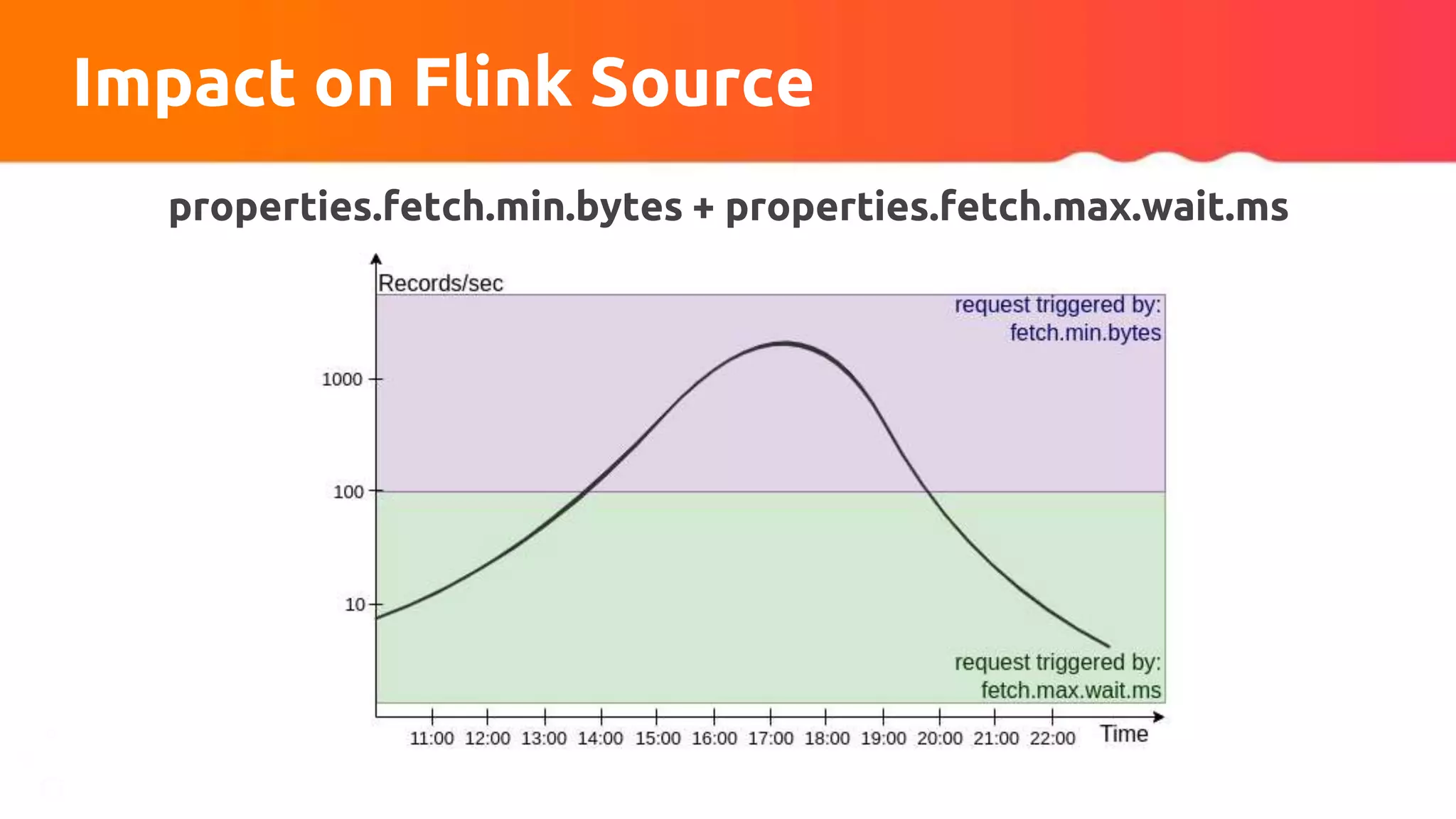
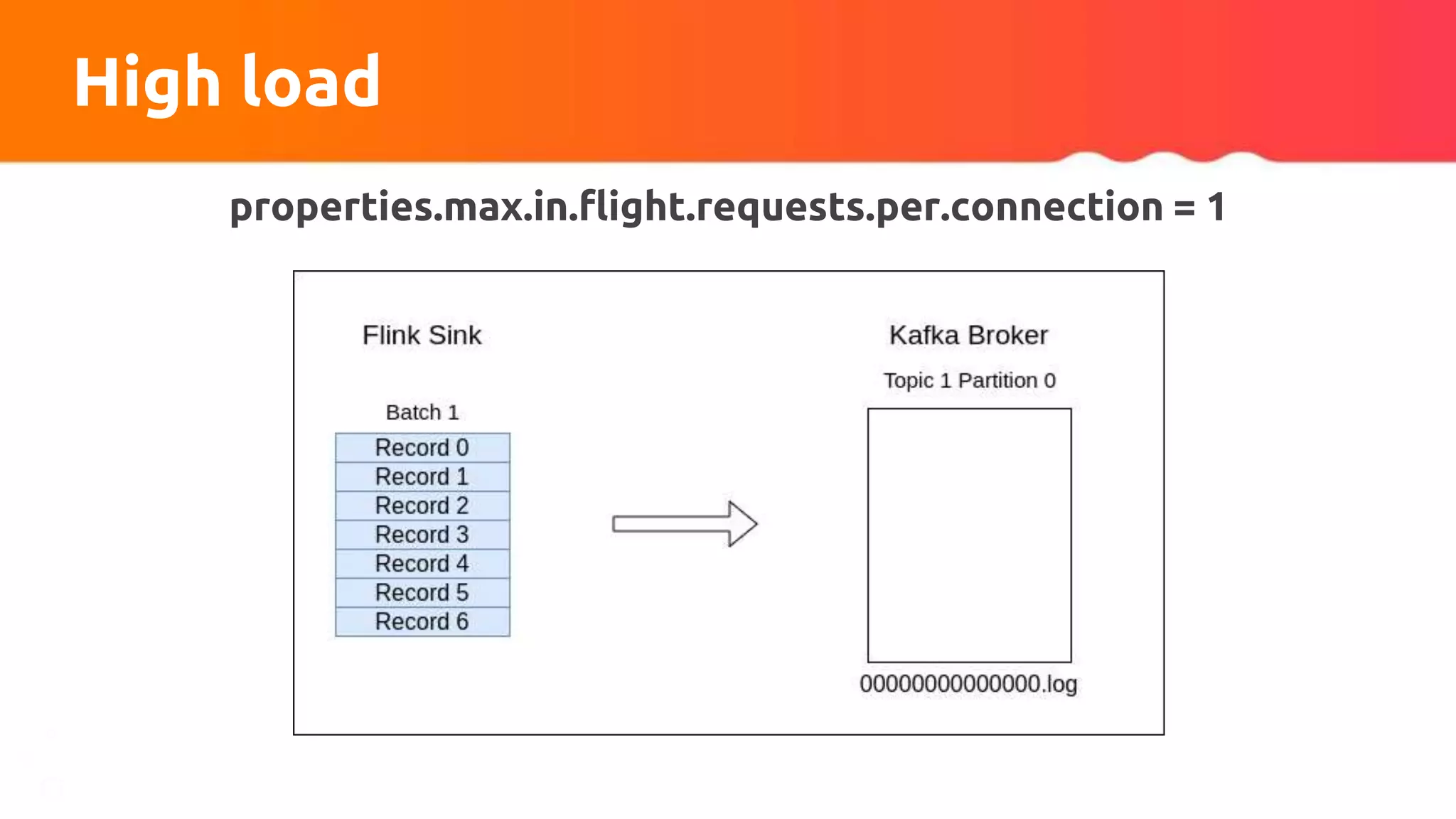
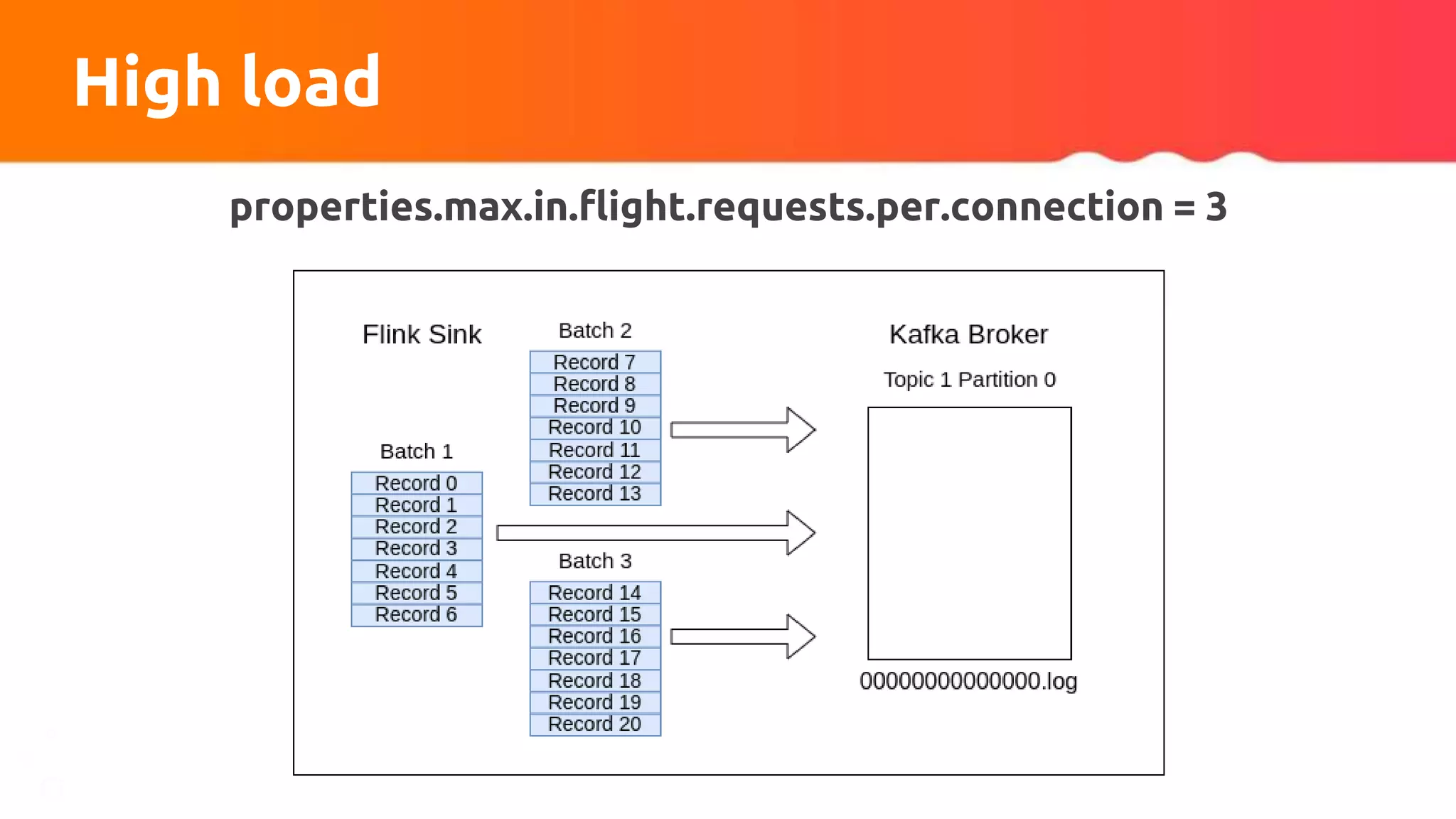
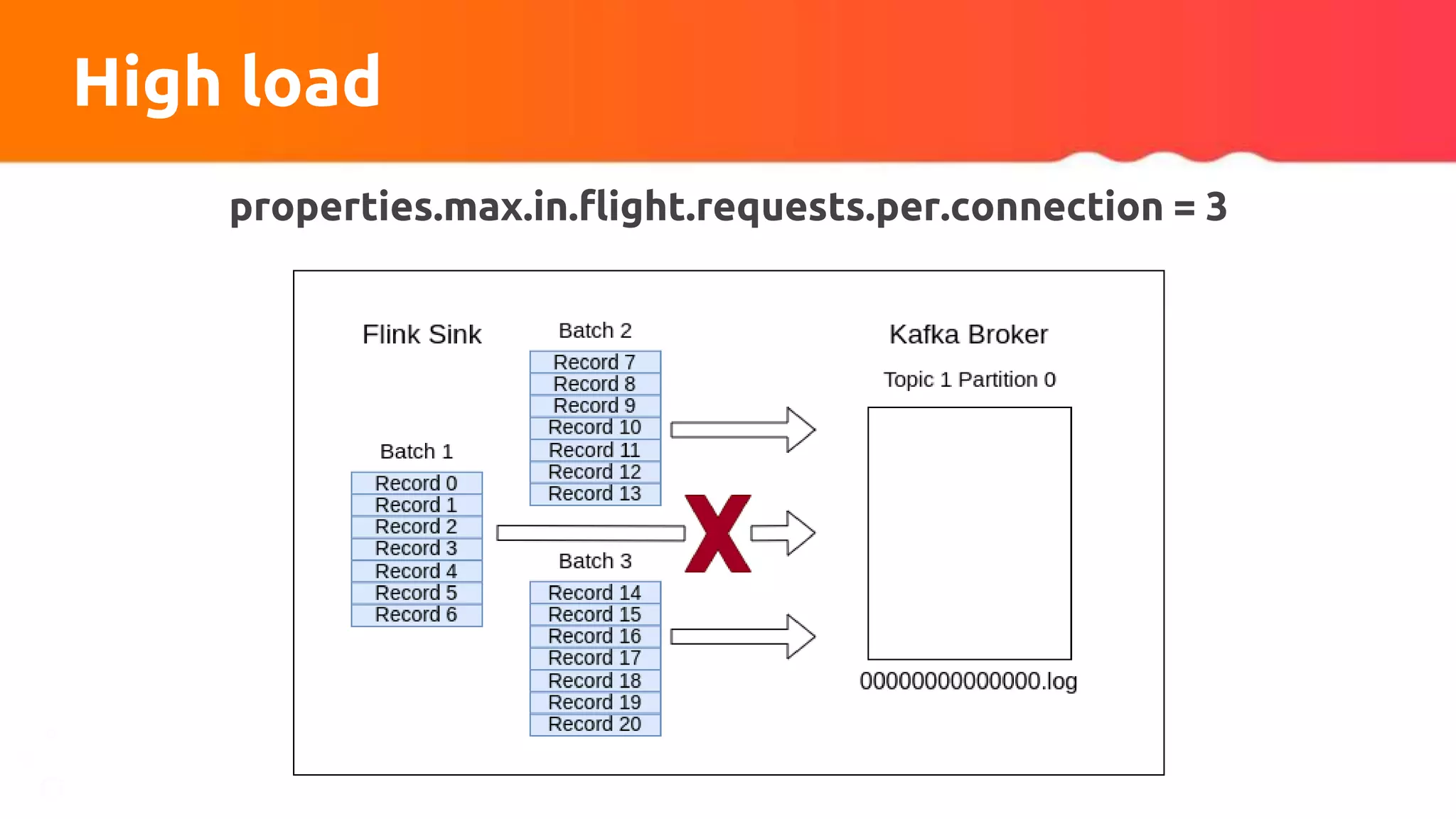
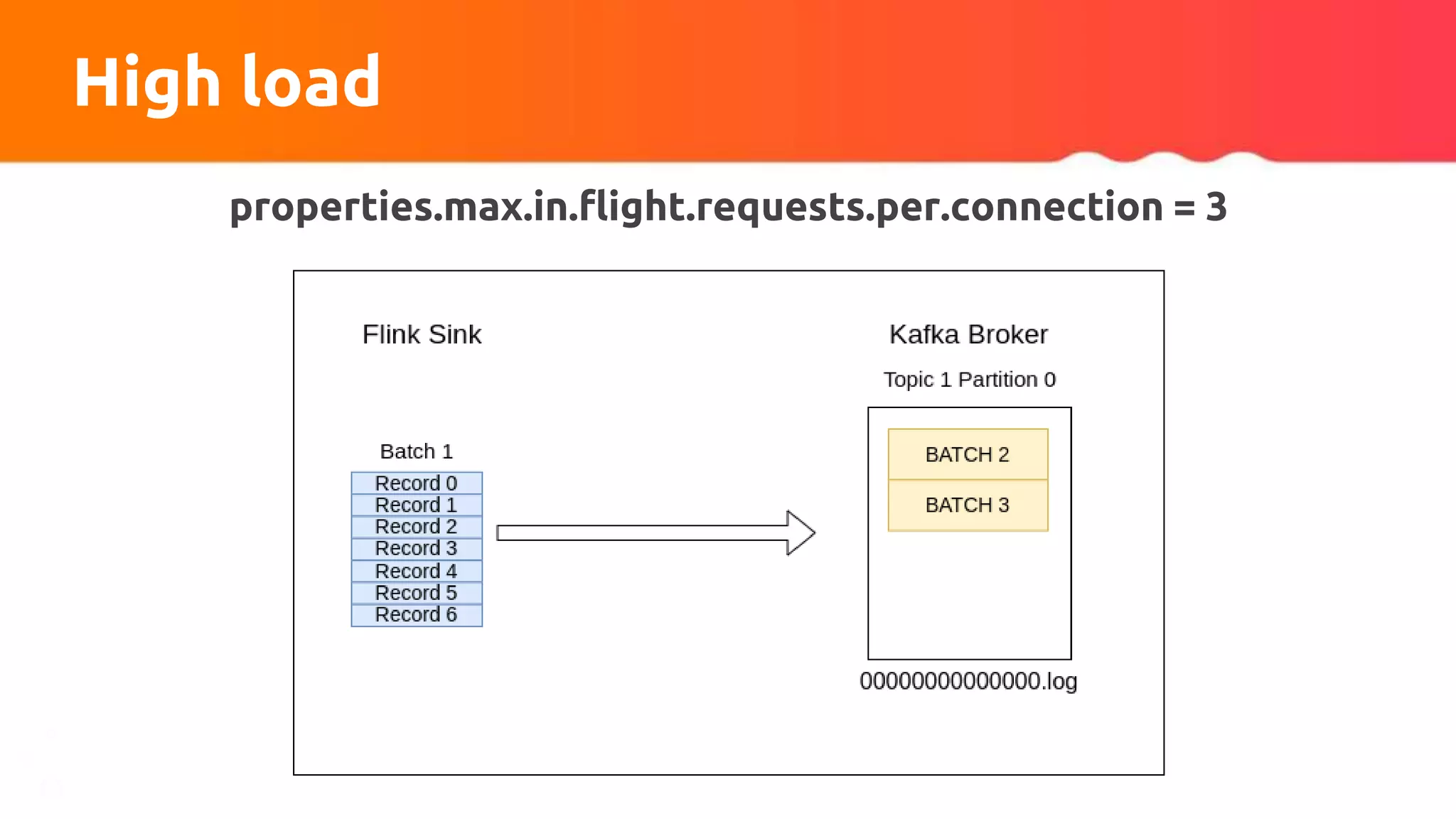



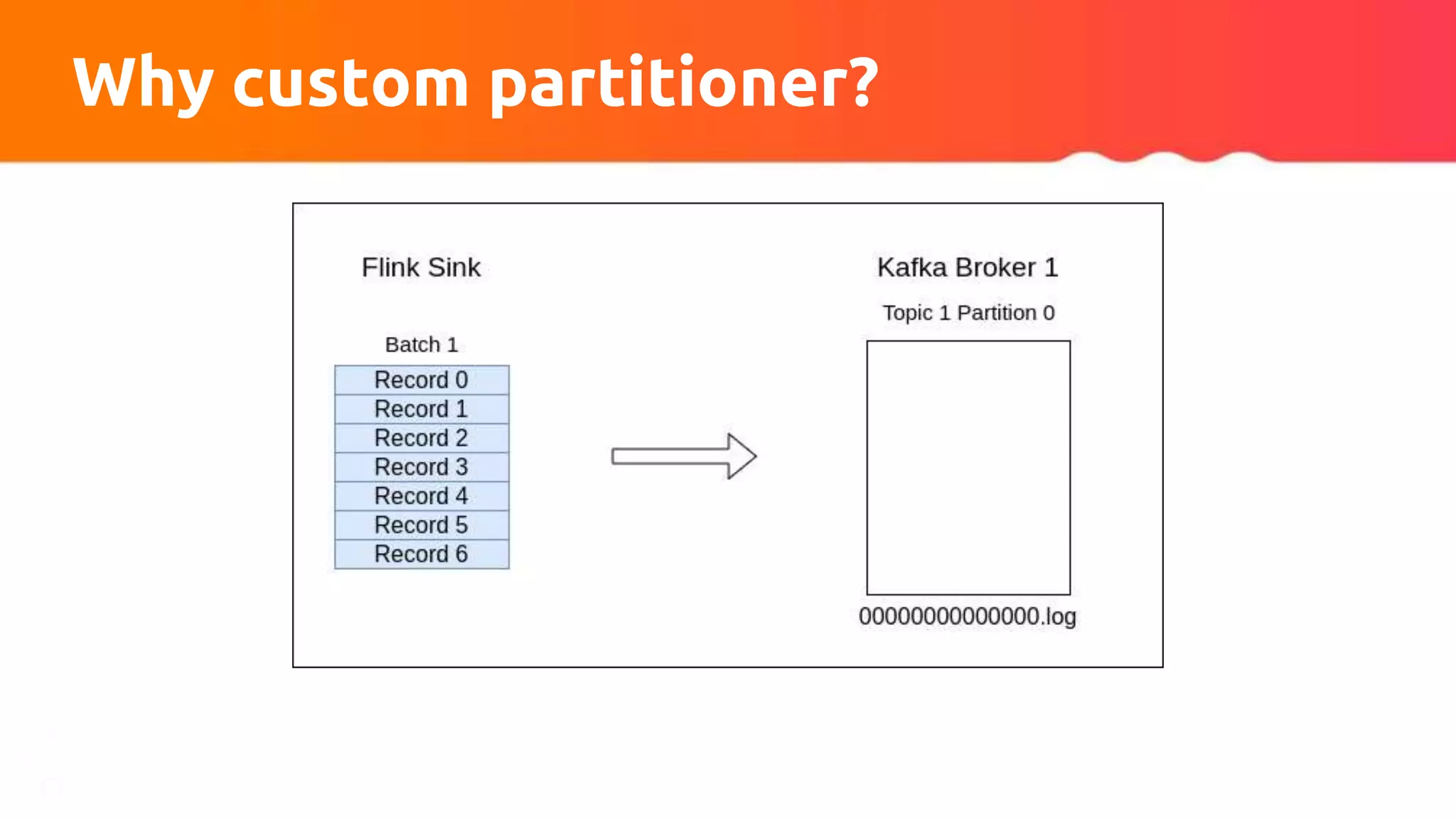
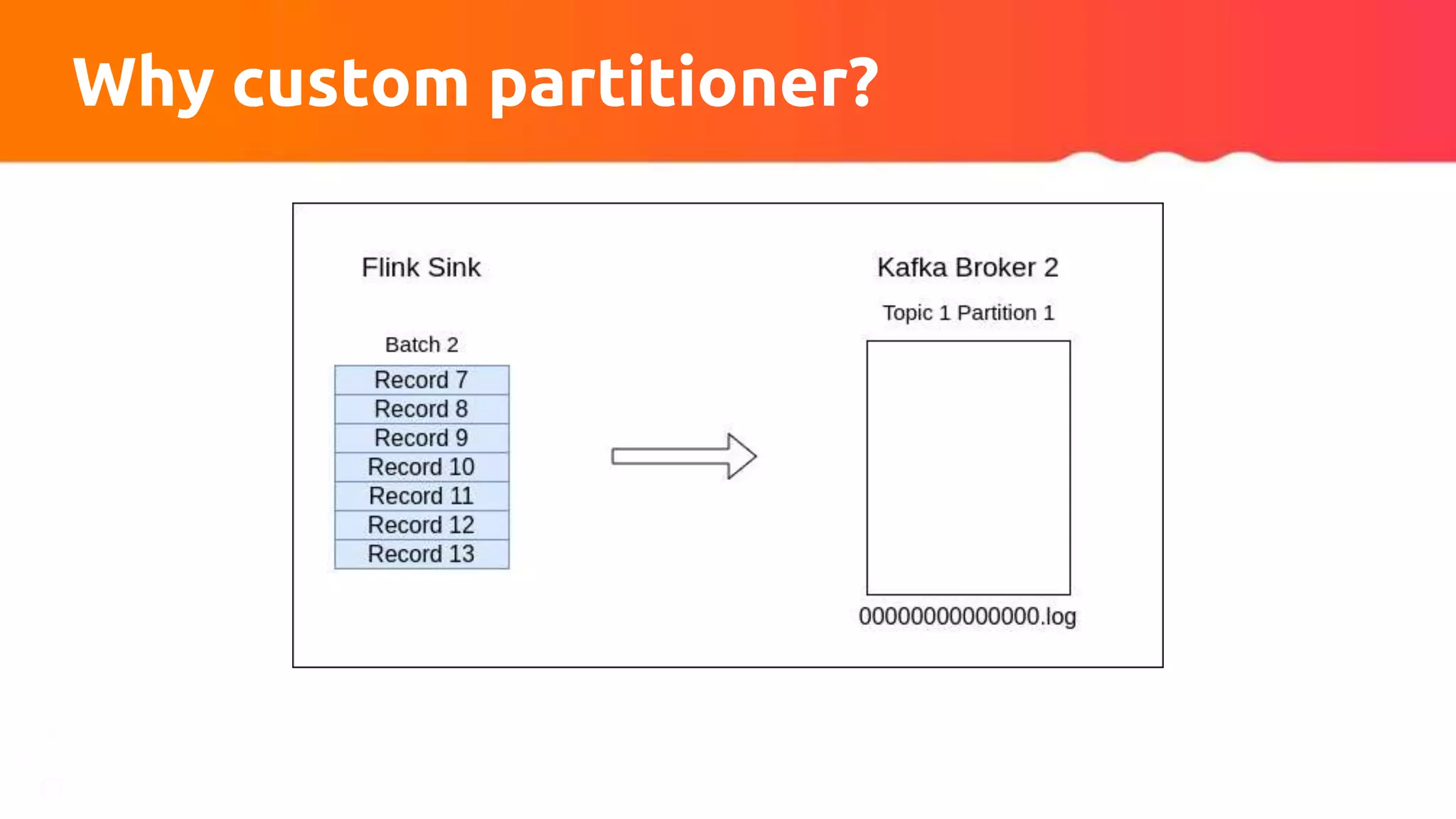

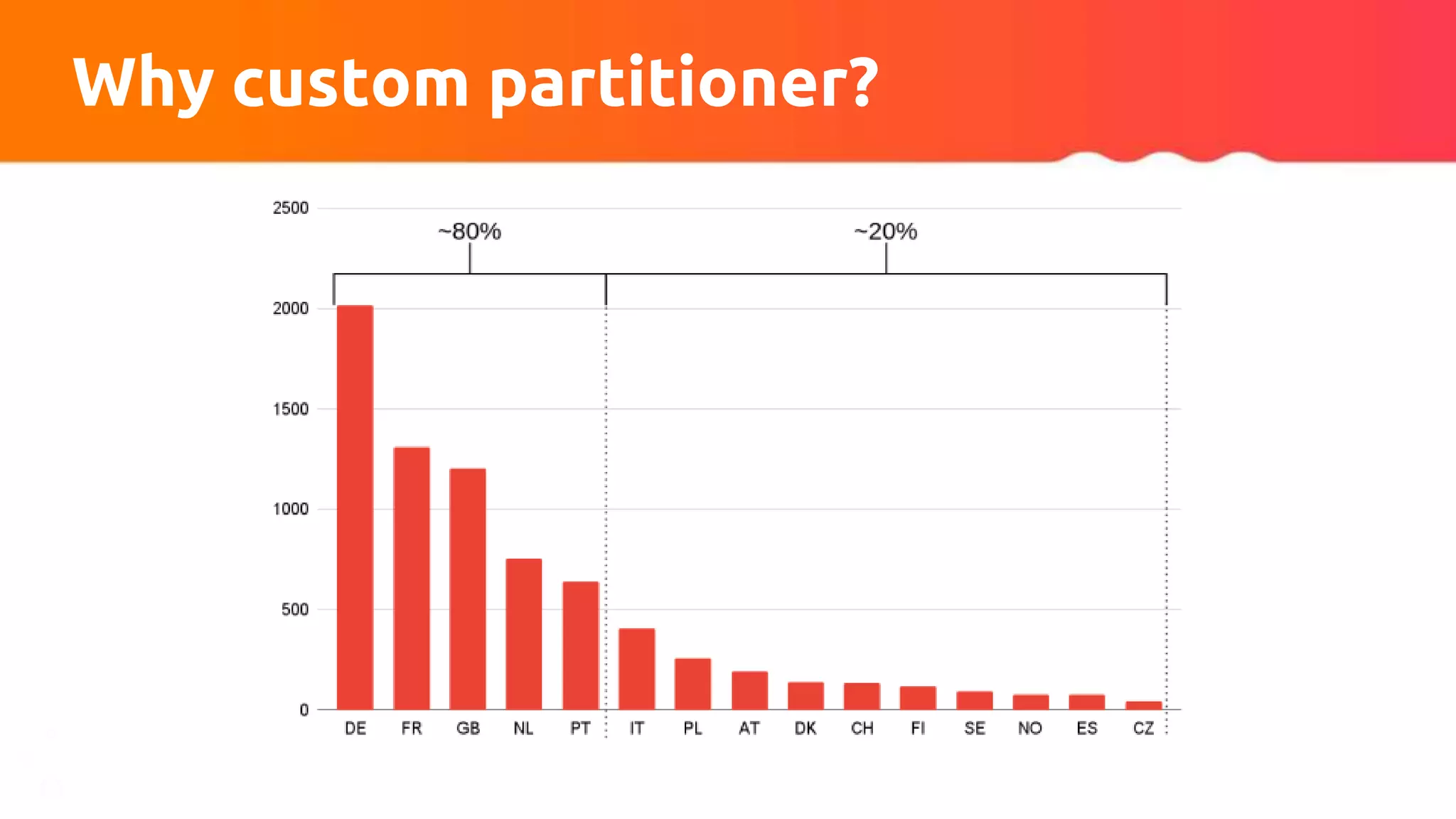
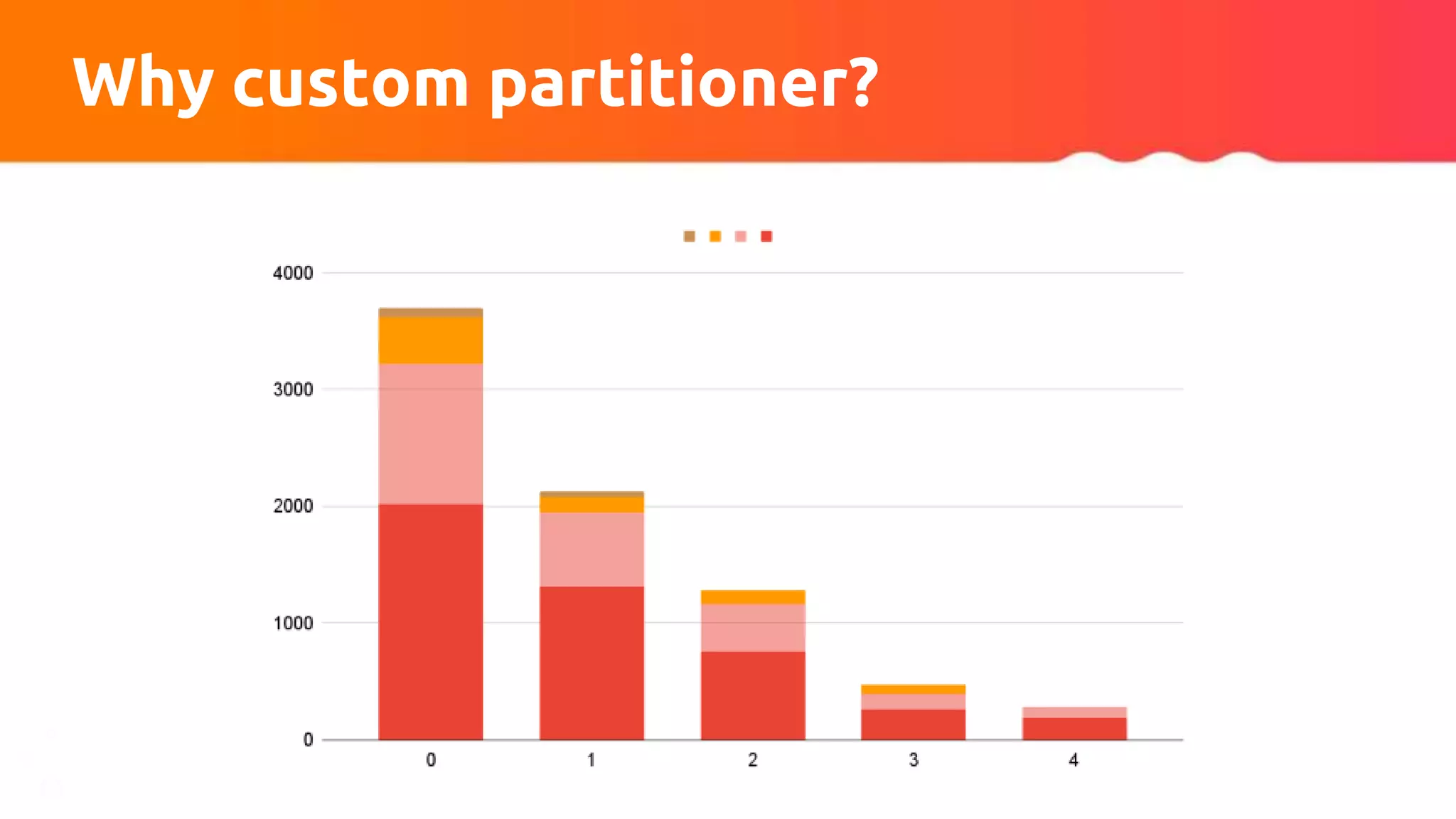
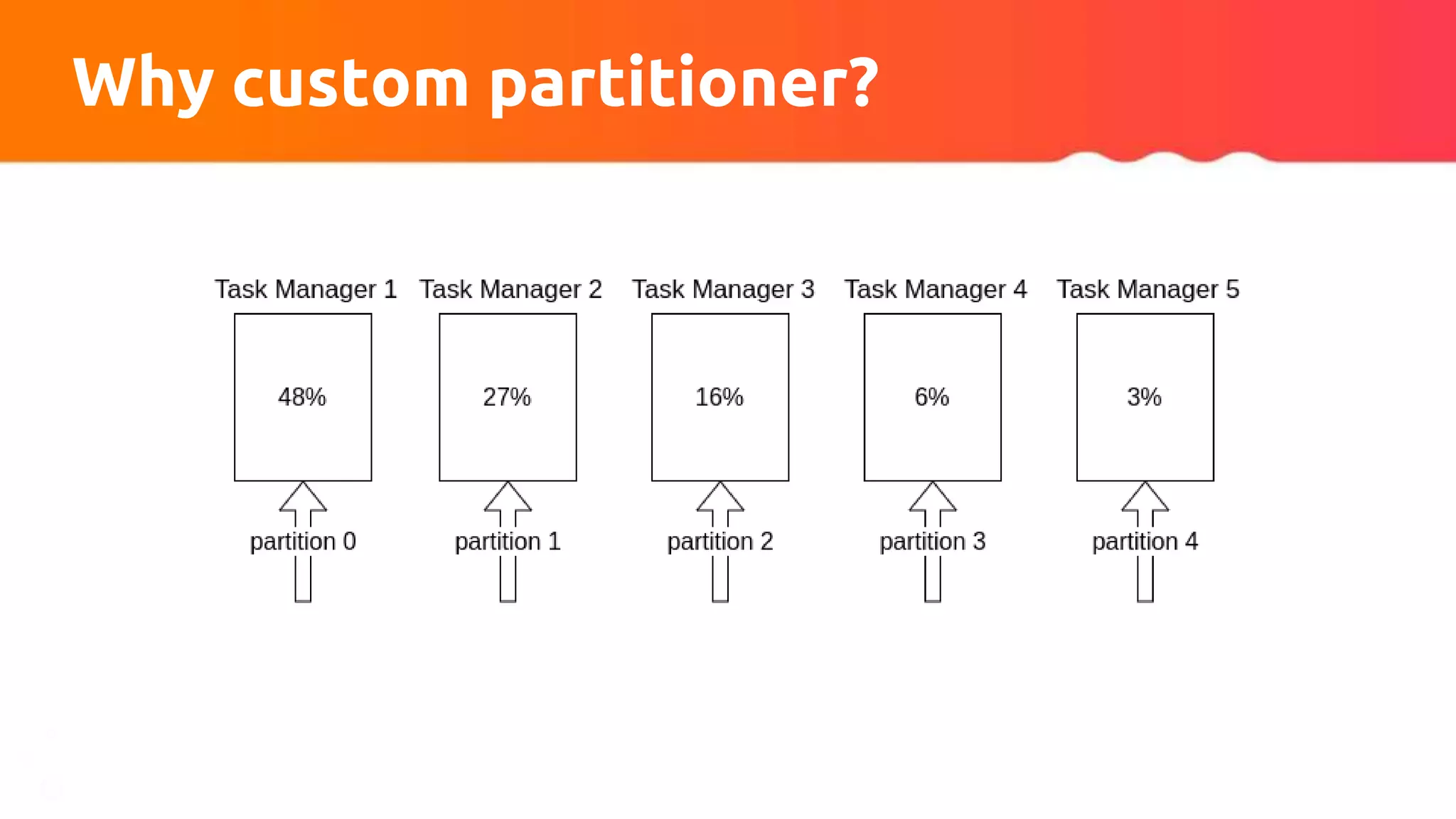
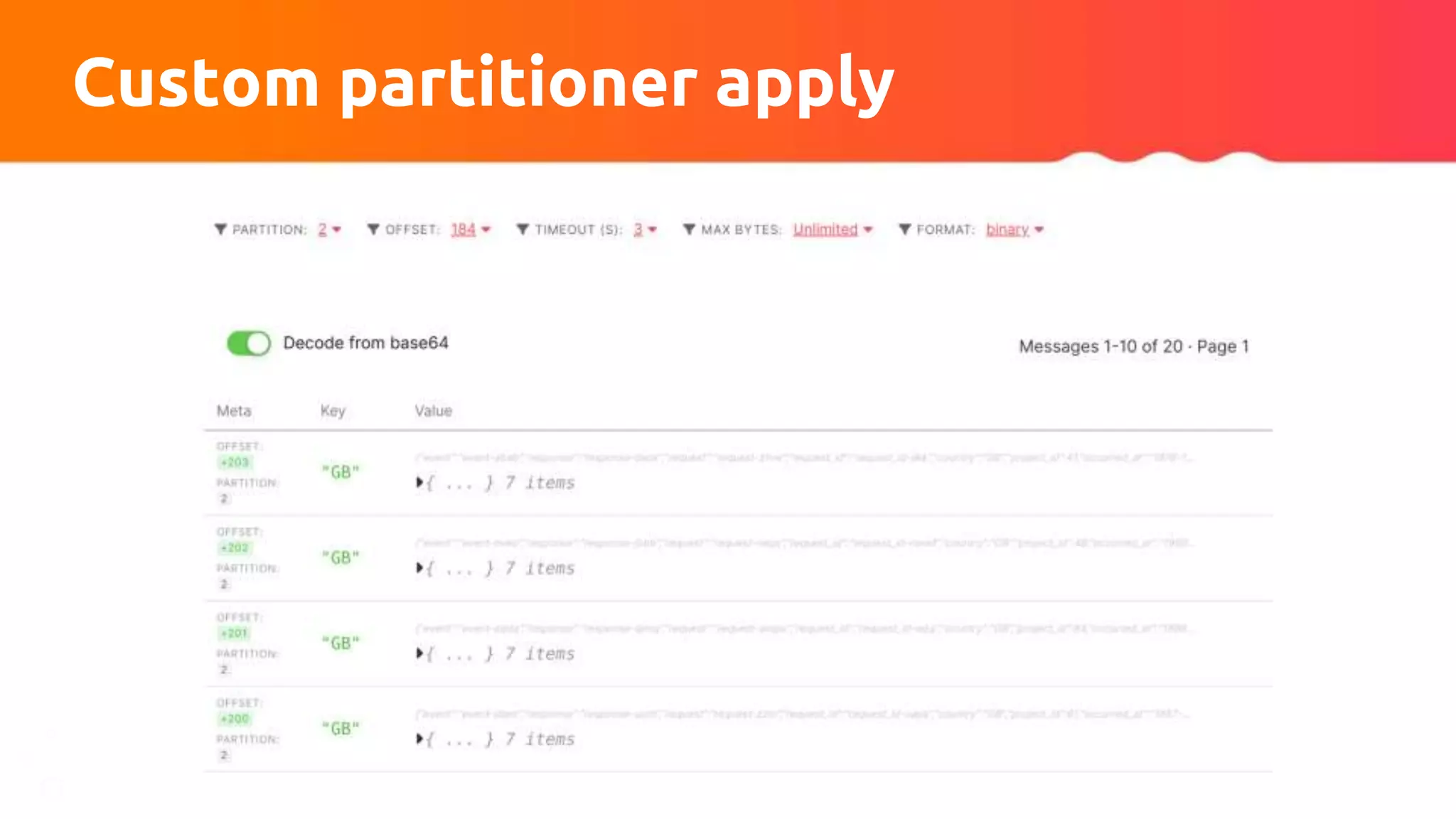
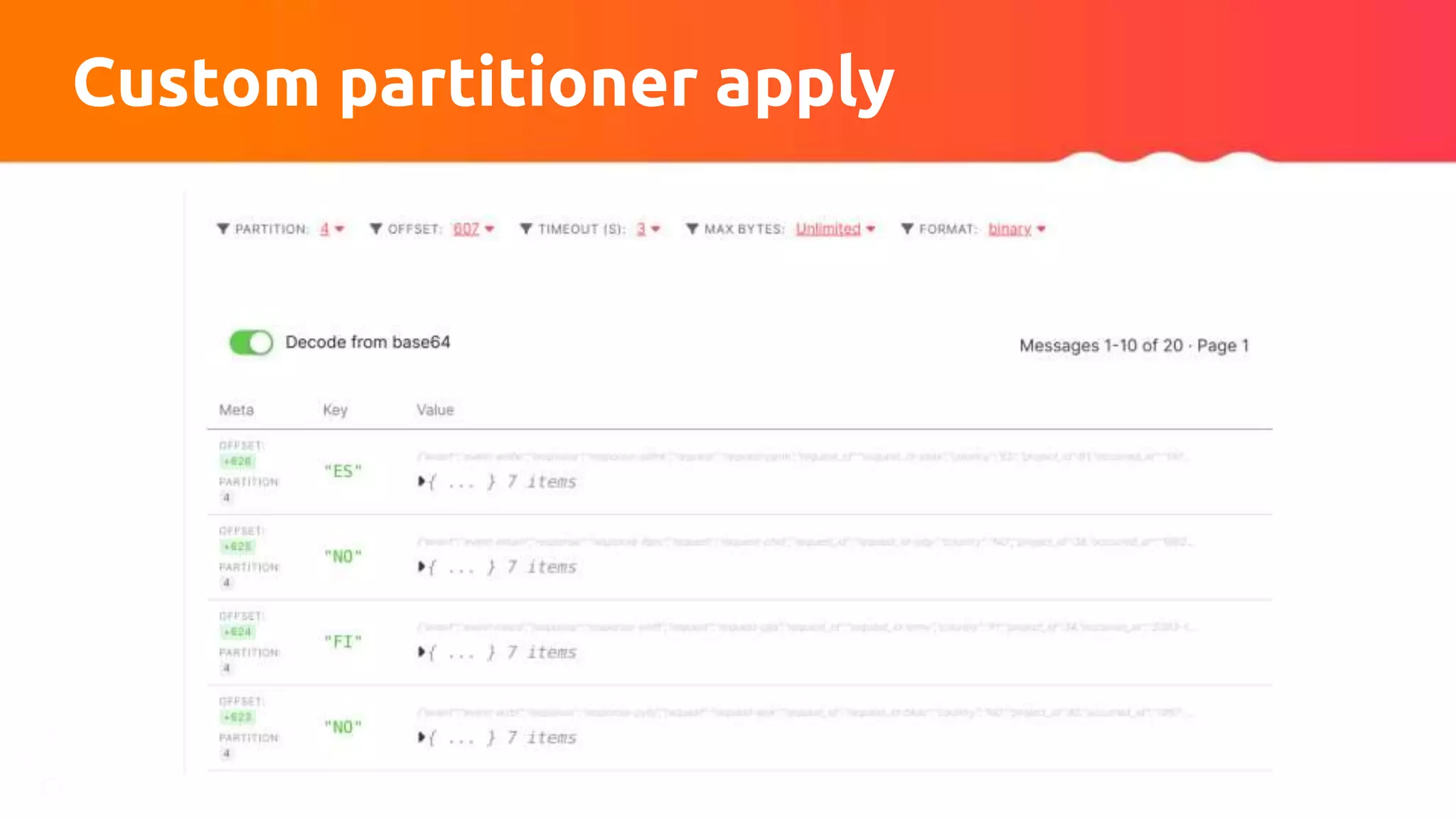
![Custom partitioner apply
// Input: sortedWeights = {'DE': 20, 'FR': 11, 'DK': 2, 'CZ': 1}, nPartitions = 3
totalSum = sum(sortedWeights.values()); accSum = 0;
keysSumWeights = sortedWeights.forEach((k, v) ->
{ accSum += v; return (k, accSum /totalSum) }
// {"DE":0.588, 'FR': 0.912, 'DK': 0.97, 'CZ': 1}
fraction = 1.0 / nPartitions; partition = 1; partitionsDistribution = {}
for k, v in keysSumWeights
partitionDistribution[k] = min(partition, nPartitions) - 1
if v >= partition * fraction
partition += 1
return partitionsDistribution](https://image.slidesharecdn.com/315pmtuningapachekafkaconnectorsforflinkobabenko-220809121057-9b32c89f/75/Tuning-Apache-Kafka-Connectors-for-Flink-pptx-44-2048.jpg)
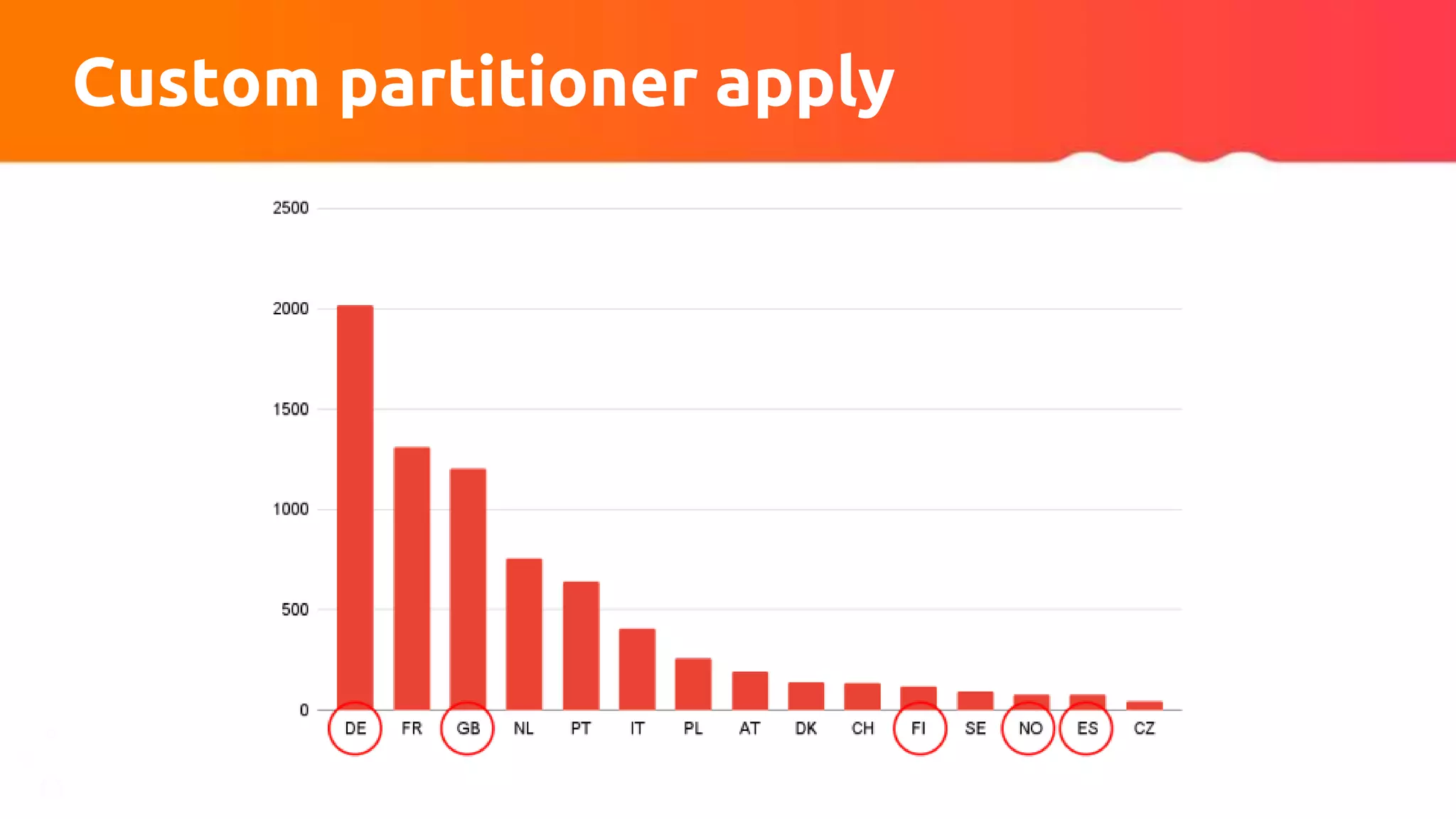

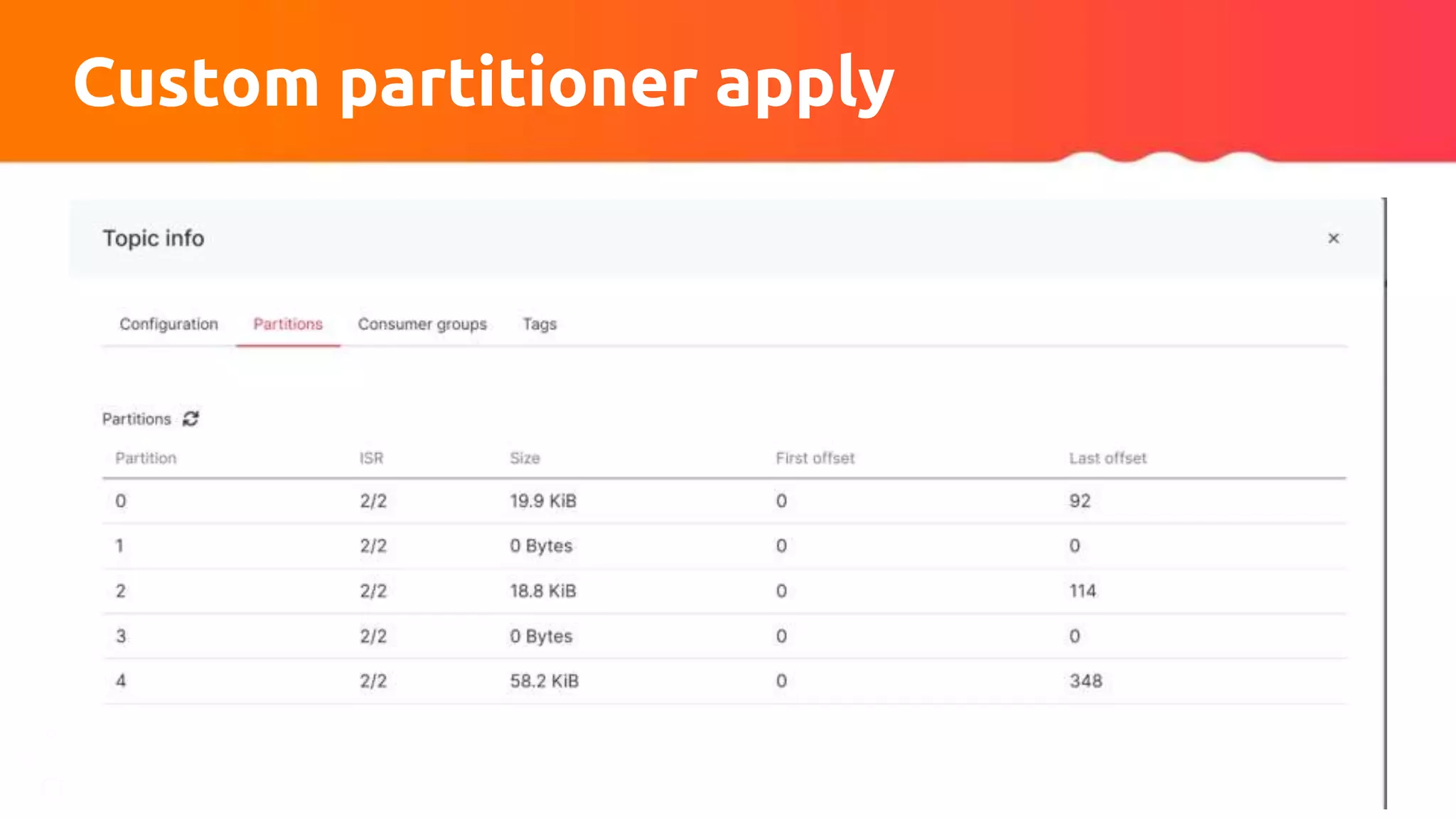
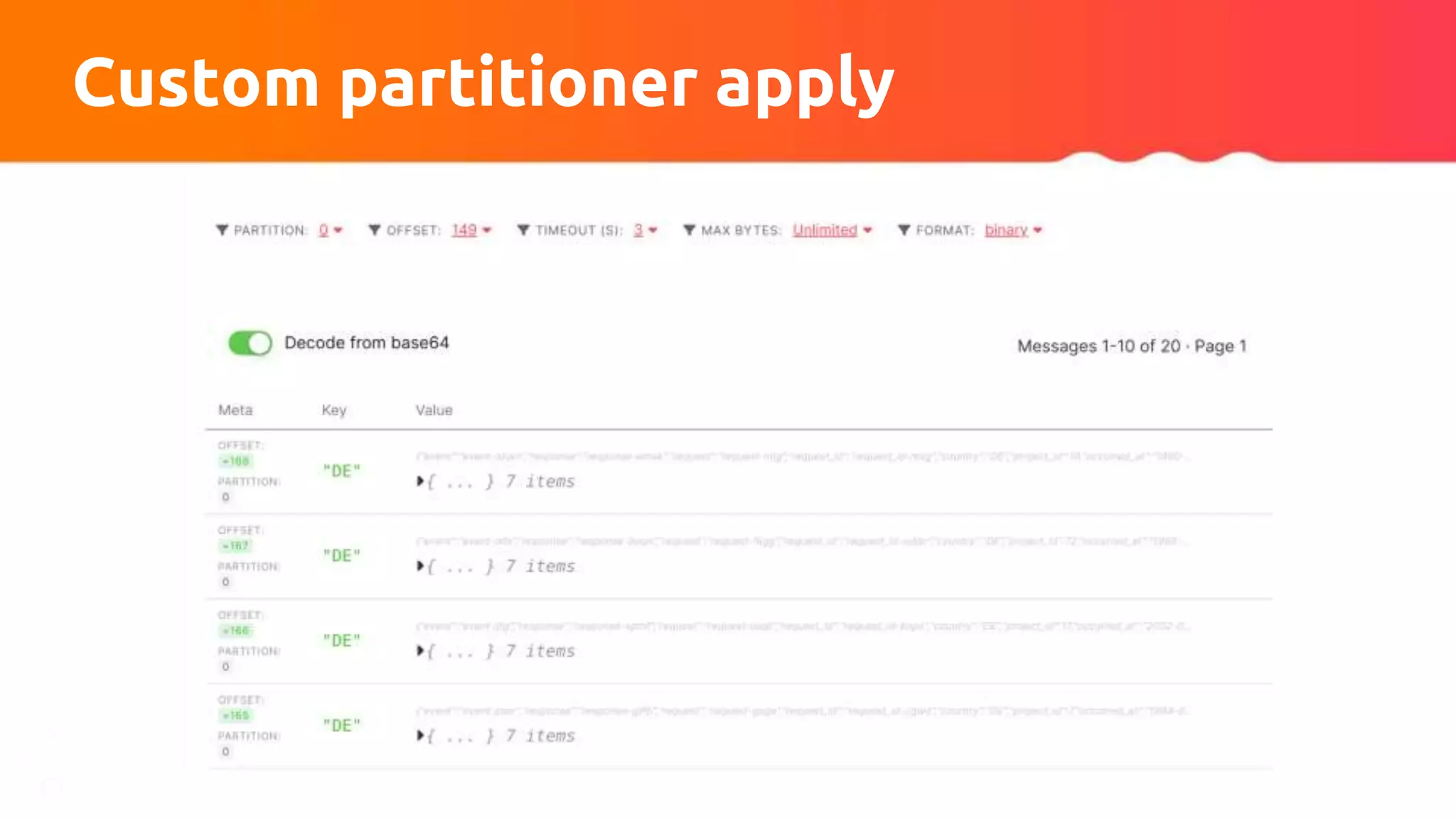





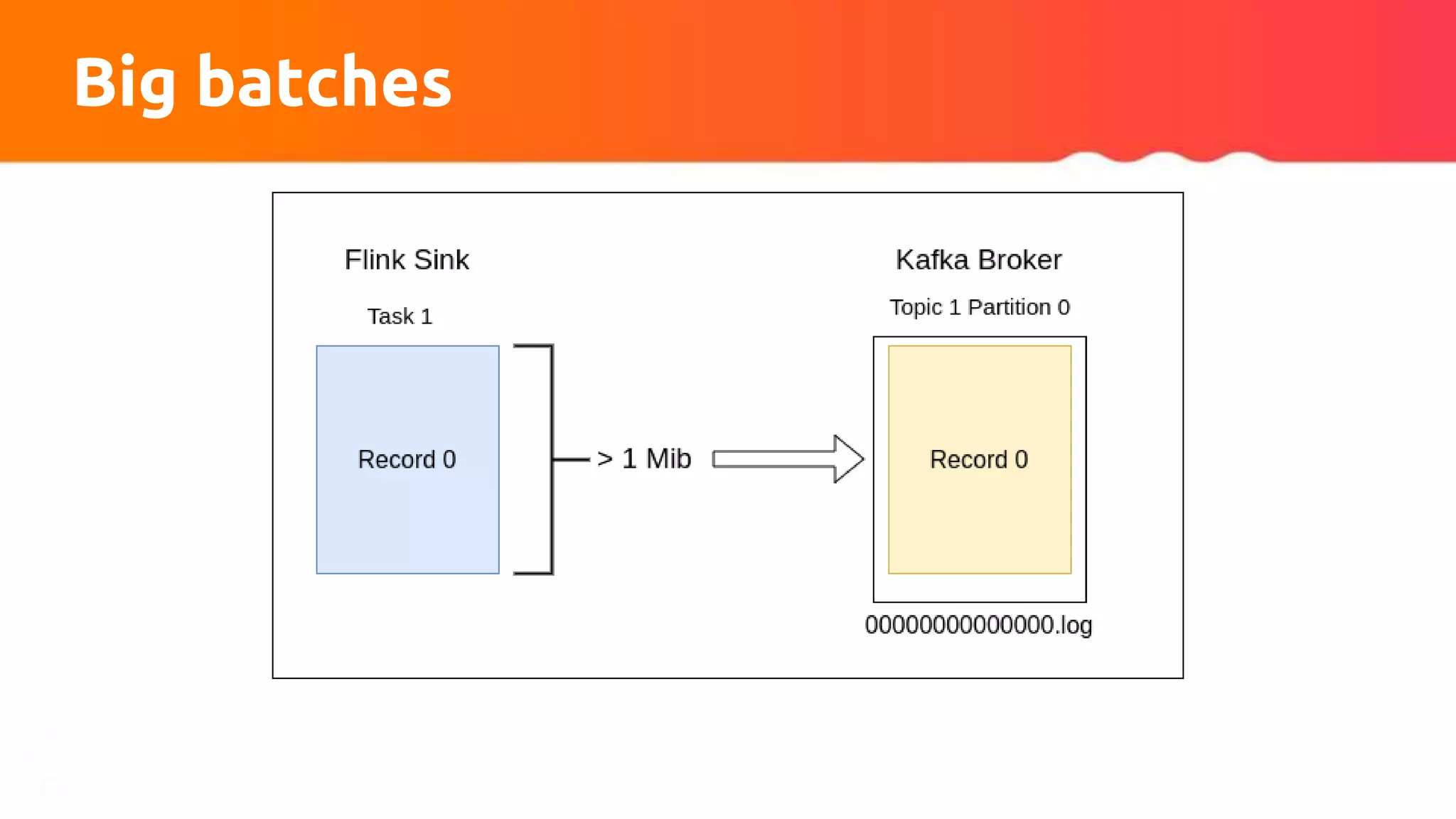
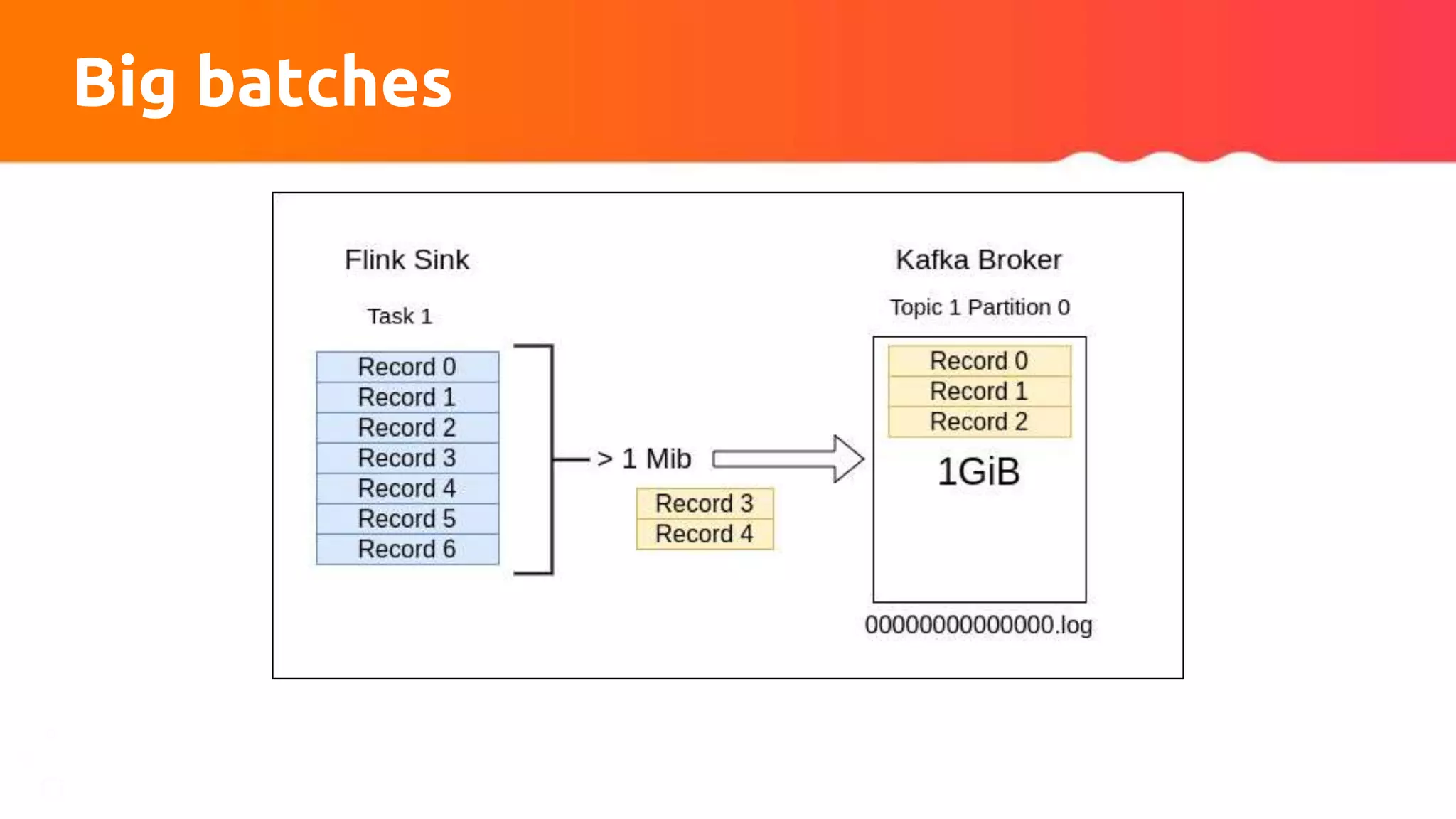
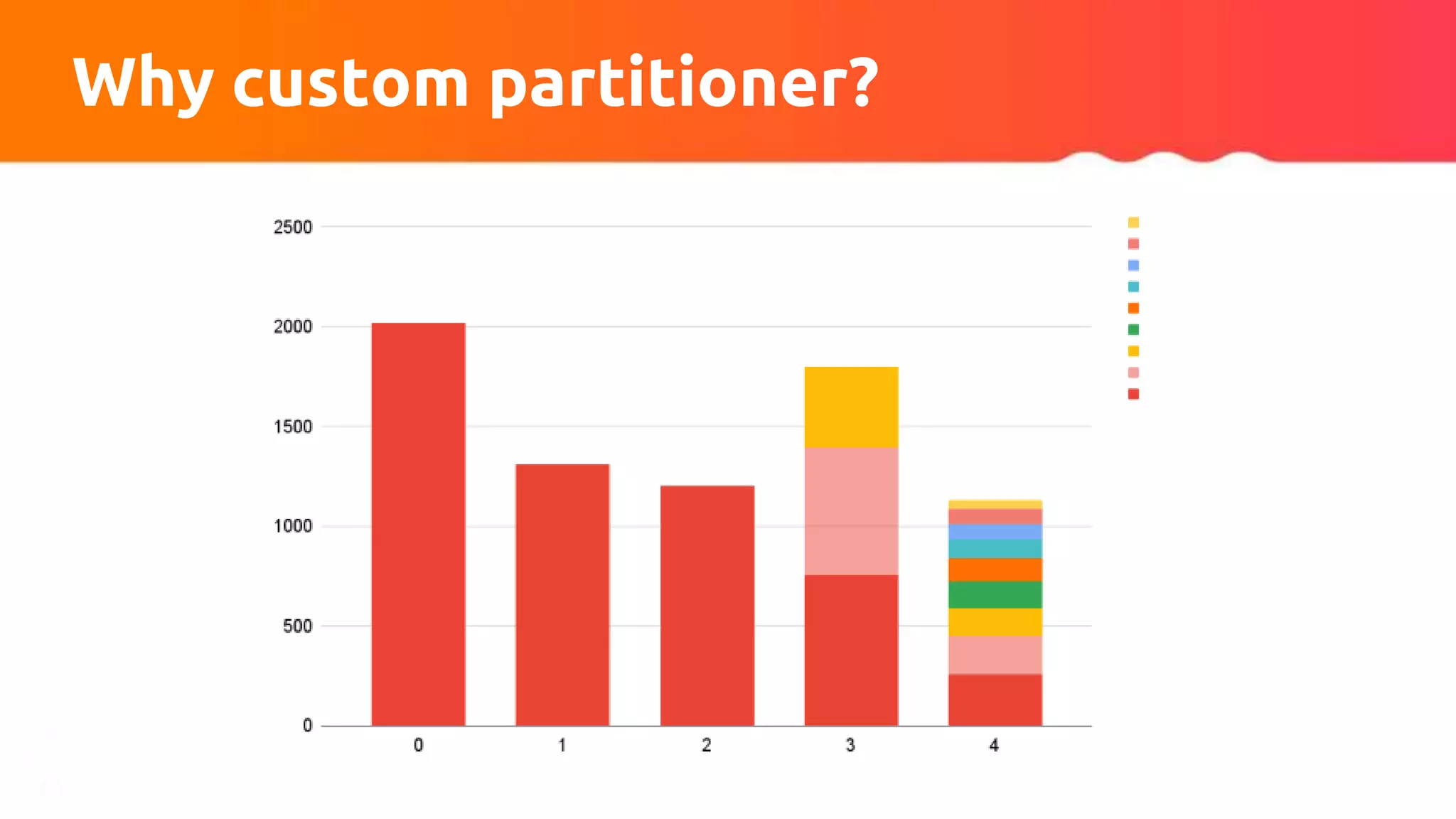
The document discusses tuning Apache Kafka connectors for Flink, focusing on the migration from test to production and addressing issues related to message size and batch processing in Kafka. It outlines steps to resolve common errors, optimize configurations, and improve performance through adjustments in topic settings, batch compression, and custom partitioning strategies. The author emphasizes the necessity of adapting Kafka sink/source configurations based on varying data loads and business requirements.



































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










