Downloaded 55 times




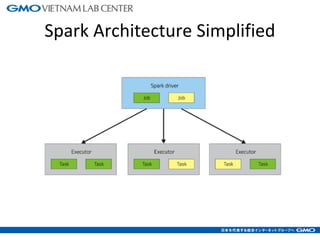


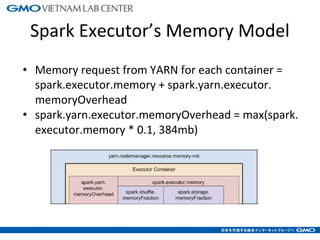
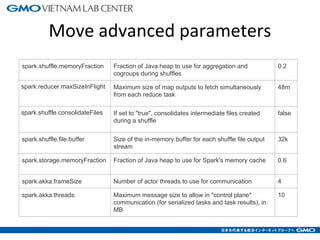
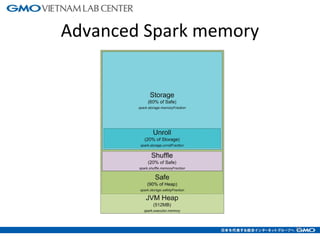
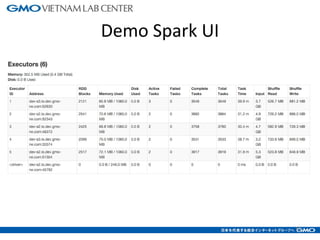

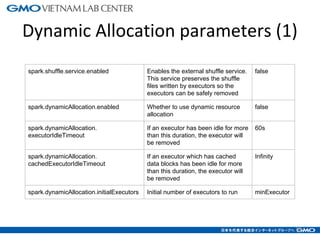
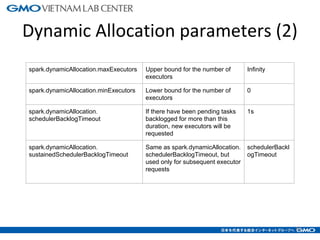






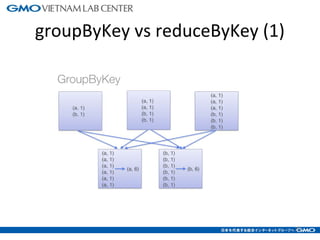






The document discusses tuning Spark parameters to optimize performance. It describes how to control Spark's resource usage through parameters like num-executors, executor-cores, and executor-memory. Advanced parameters like spark.shuffle.memoryFraction and spark.reducer.maxSizeInFlight are also covered. Dynamic allocation allows scaling resources up and down based on workload. Tips provided include tuning memory usage, choosing serialization and storage levels, setting parallelism, and avoiding operations like groupByKey. An example recommends tuning the collaborative filtering algorithm in the RW project, reducing runtime from 27 minutes to under 7 minutes.





























































































