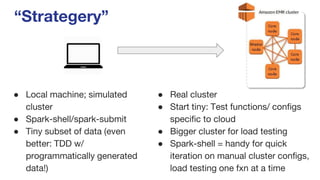
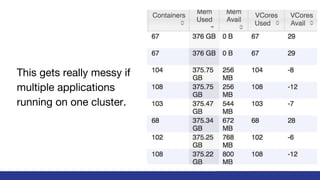
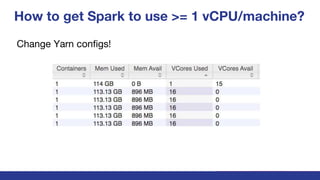
The document discusses key insights and challenges when working with Apache Spark, including effective development strategies, utilizing built-in features, and managing resources efficiently. It emphasizes the importance of avoiding excessive data shuffling and configuring cluster resources properly to maximize performance. Additionally, it highlights the relevance of the Spark UI and history server for monitoring and optimizing job execution.























![[4DEV][Łódź] Ivan Vaskevych - InfluxDB and Grafana fighting together with IoT...](https://cdn.slidesharecdn.com/ss_thumbnails/influxdb-171113135140-thumbnail.jpg?width=640&height=640&fit=bounds)




























































