Downloaded 19 times







![Skew Hint
Union
Scan table_A Scan table_B
Filter
[skewed keys]
BroadcastHashJoin
Filter
[skewed keys]
Scan table_A Scan table_B
SortMergeJoin
Filter
[non-skewed keys]
Filter
[non-skewed keys]
Exchange Exchange
Skewed dataNon-skewed data](https://image.slidesharecdn.com/147dewakarxu-201129185214/75/Skew-Mitigation-For-Facebook-PetabyteScale-Joins-9-2048.jpg)








![table_A (petabye) table_B
Left Outer Join
table_C
Left Outer Join
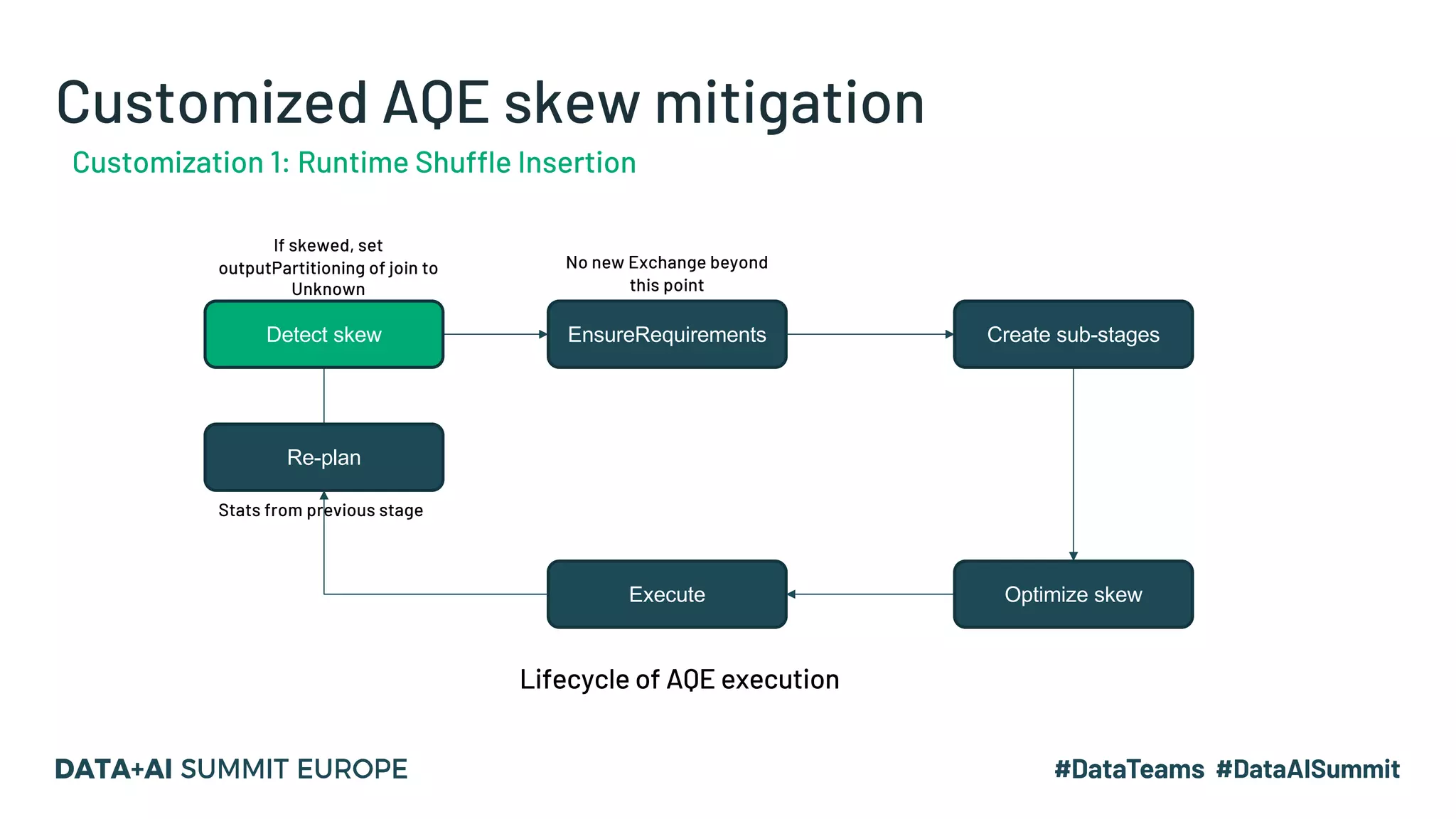
Customized AQE skew mitigation
[Limitation] Customization 1: Runtime Shuffle Insertion
table_D
Left Outer Join](https://image.slidesharecdn.com/147dewakarxu-201129185214/75/Skew-Mitigation-For-Facebook-PetabyteScale-Joins-20-2048.jpg)
![table_A (petabye) table_B
Left Outer Join
table_C
Left Outer Join
Customized AQE skew mitigation
[Limitation] Customization 1: Runtime Shuffle Insertion
table_D
Left Outer Join
Exchange
Exchange
Shuffles PB sized
data
Shuffles PB sized
data](https://image.slidesharecdn.com/147dewakarxu-201129185214/75/Skew-Mitigation-For-Facebook-PetabyteScale-Joins-21-2048.jpg)























The document discusses strategies for mitigating data skew in large-scale joins within Facebook's data processing framework, focusing on techniques such as skew hints, runtime skew mitigation, and the customized Adaptive Query Execution (AQE) framework. It compares varying join strategies in Spark, explaining how skewed partitions can significantly impact task latency and system performance. Additionally, it highlights the functions of Cosco, an efficient shuffle service designed to improve I/O efficiency and reduce data redundancy during processing.








![[Hadoop Meetup] Yarn at Microsoft - The challenges of scale](https://cdn.slidesharecdn.com/ss_thumbnails/yarnatmicrosoft-171222065628-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Hadoop Meetup] Apache Hadoop 3 community update - Rohith Sharma](https://cdn.slidesharecdn.com/ss_thumbnails/apachehadoop3communityupdate-rohith-171222071357-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Hadoop Meetup] Tensorflow on Apache Hadoop YARN - Sunil Govindan](https://cdn.slidesharecdn.com/ss_thumbnails/tensorflowonapachehadoopyarn-sunil-171222071922-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
