Downloaded 918 times


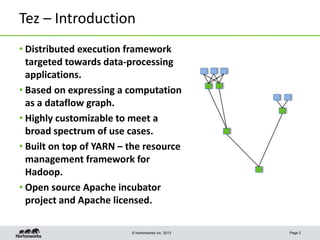


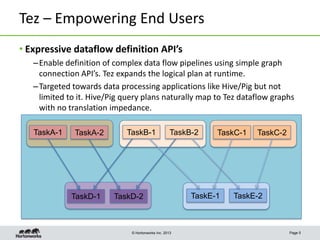
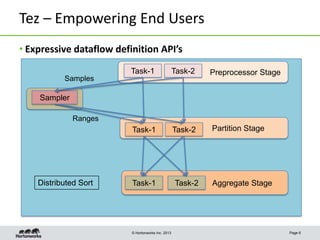
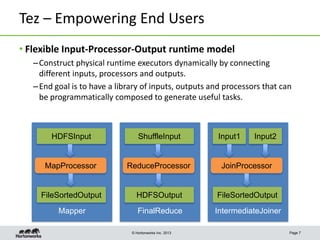
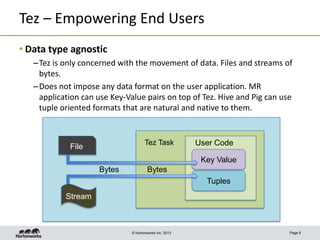
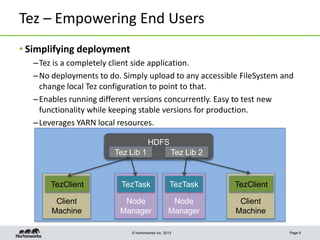


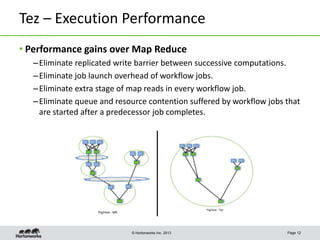
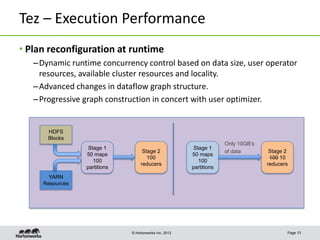
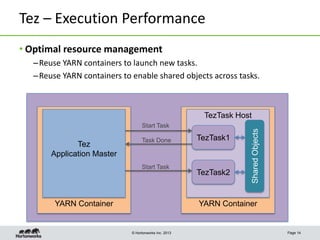
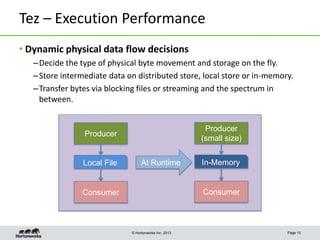

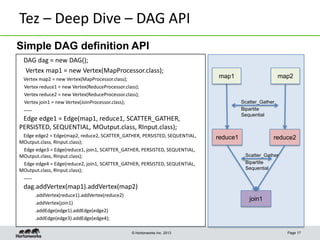
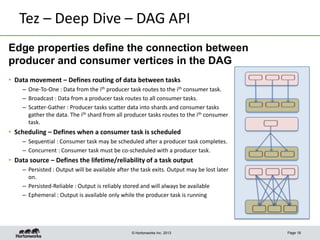
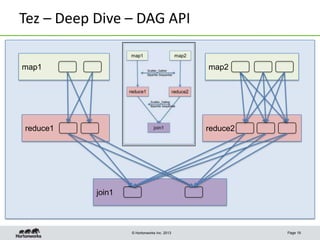
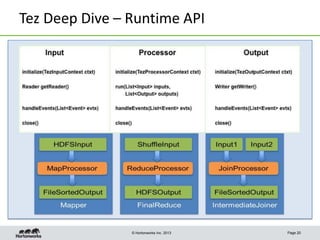
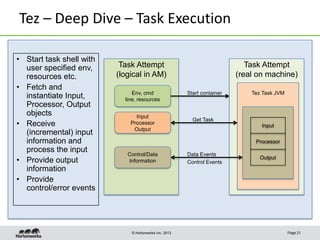
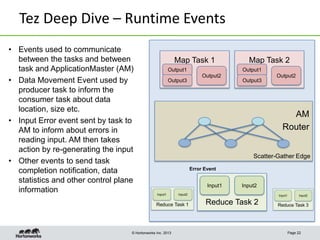
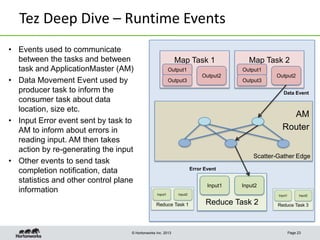
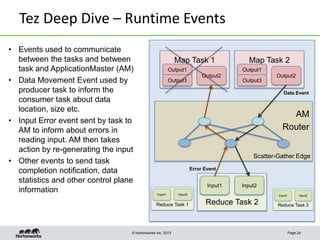
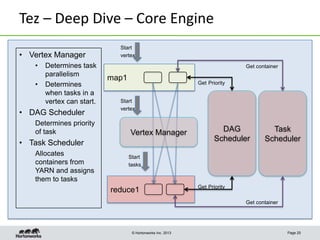
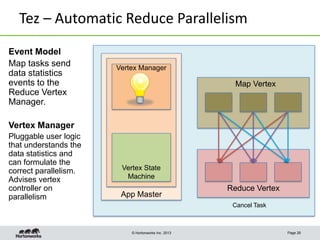
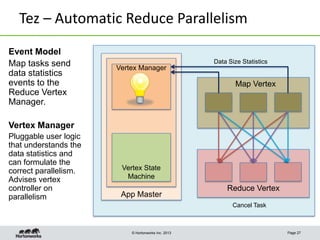
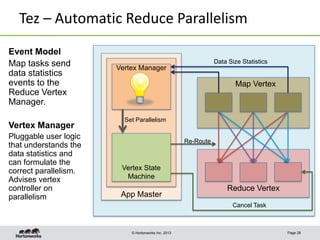
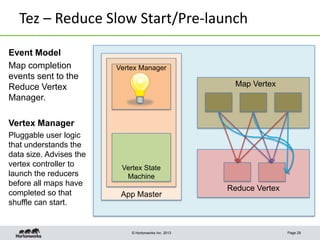
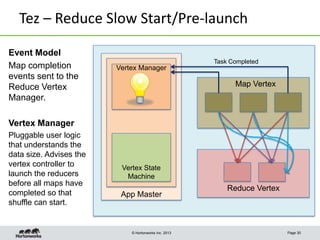
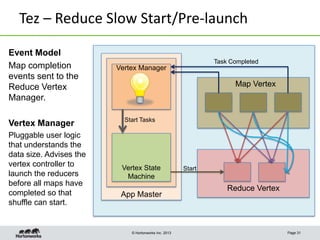
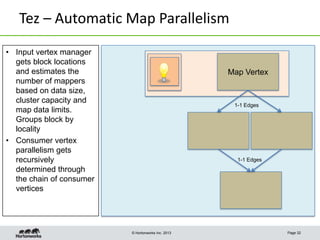
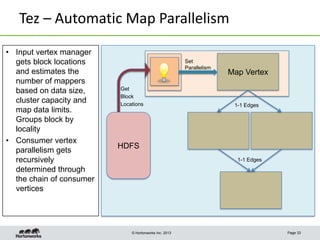
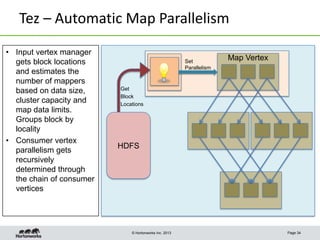
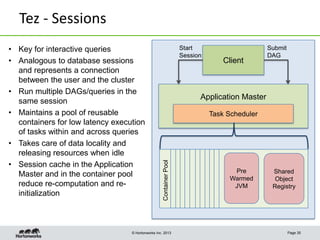

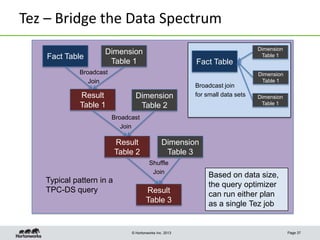
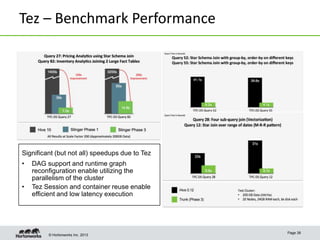
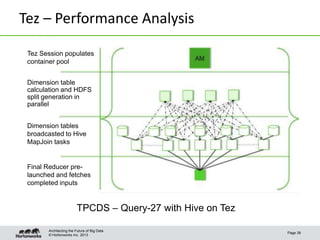




This document discusses Apache Tez, a framework for accelerating Hadoop query processing. Some key points: - Tez is a dataflow framework that expresses computations as directed acyclic graphs (DAGs) of tasks, allowing for optimizations like container reuse and locality-aware scheduling. - It is built on YARN and provides a customizable execution engine as well as APIs for applications like Hive and Pig. - By expressing jobs as DAGs, Tez can reduce overheads, queueing delays, and better utilize cluster resources compared to the traditional MapReduce framework. - The document provides examples of how Tez can improve performance for operations like joins, aggregations, and handling of multiple outputs











































![[2C1] 아파치 피그를 위한 테즈 연산 엔진 개발하기 최종](https://cdn.slidesharecdn.com/ss_thumbnails/2b1-140929191628-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)











































