




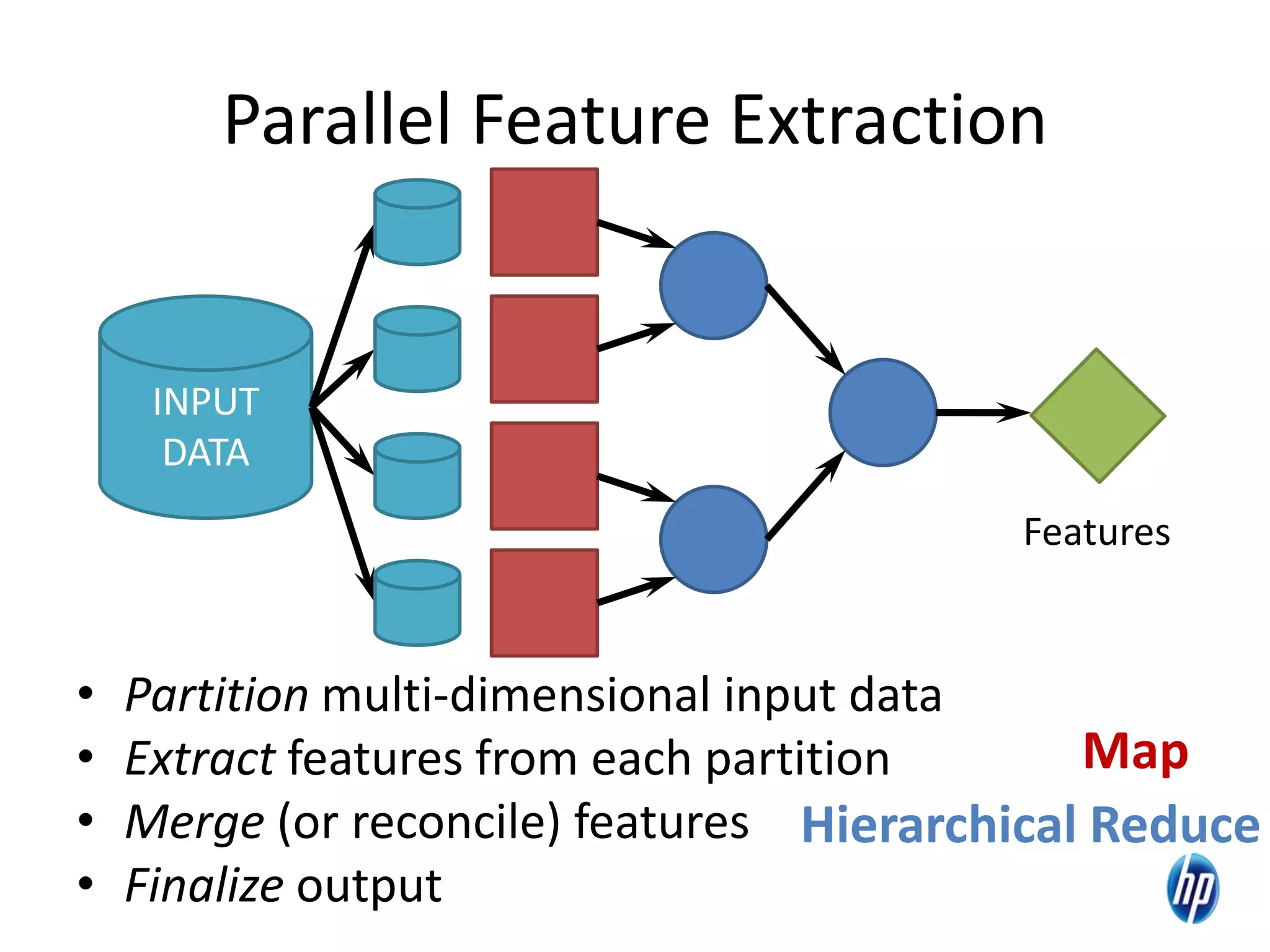

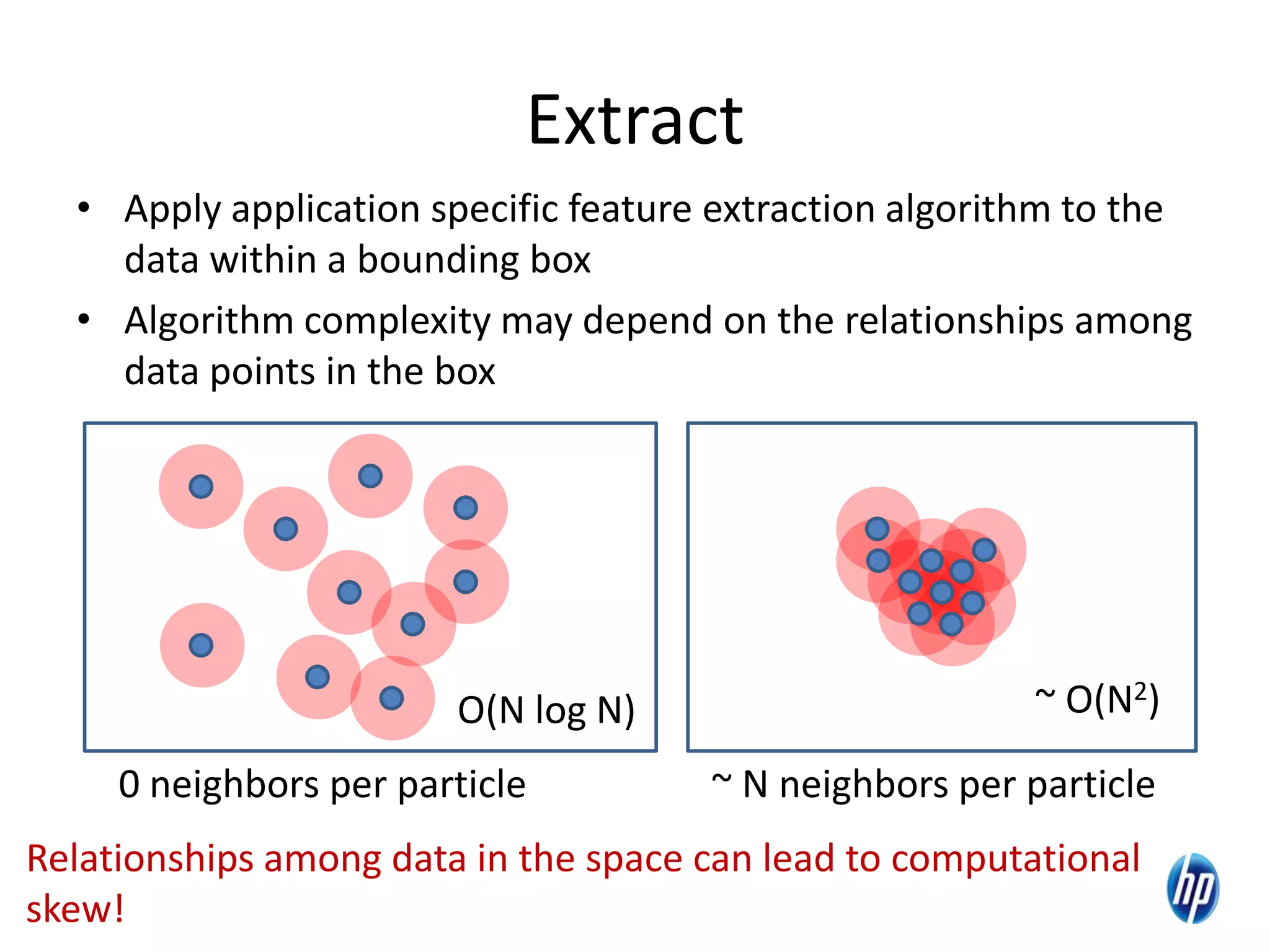
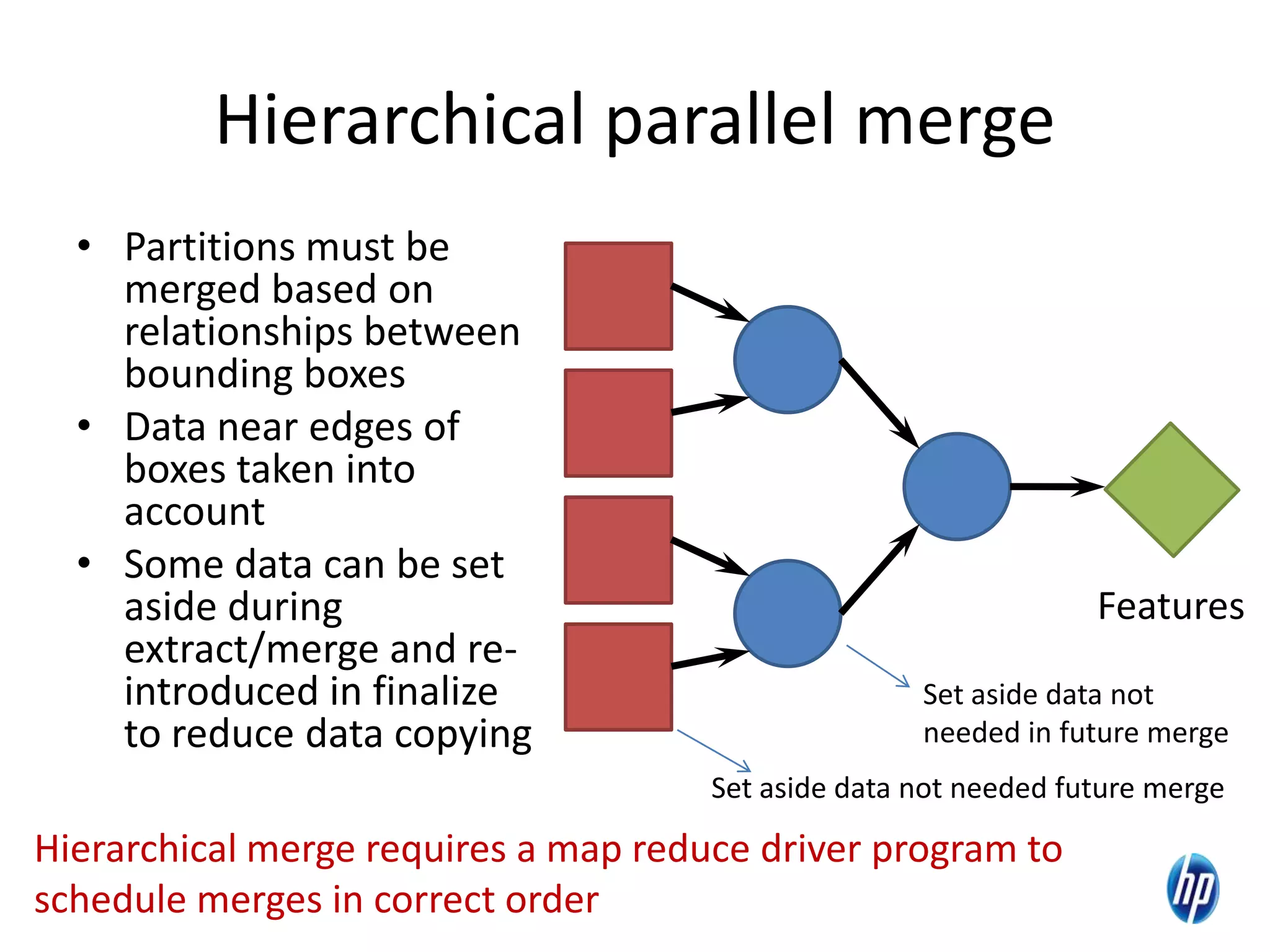

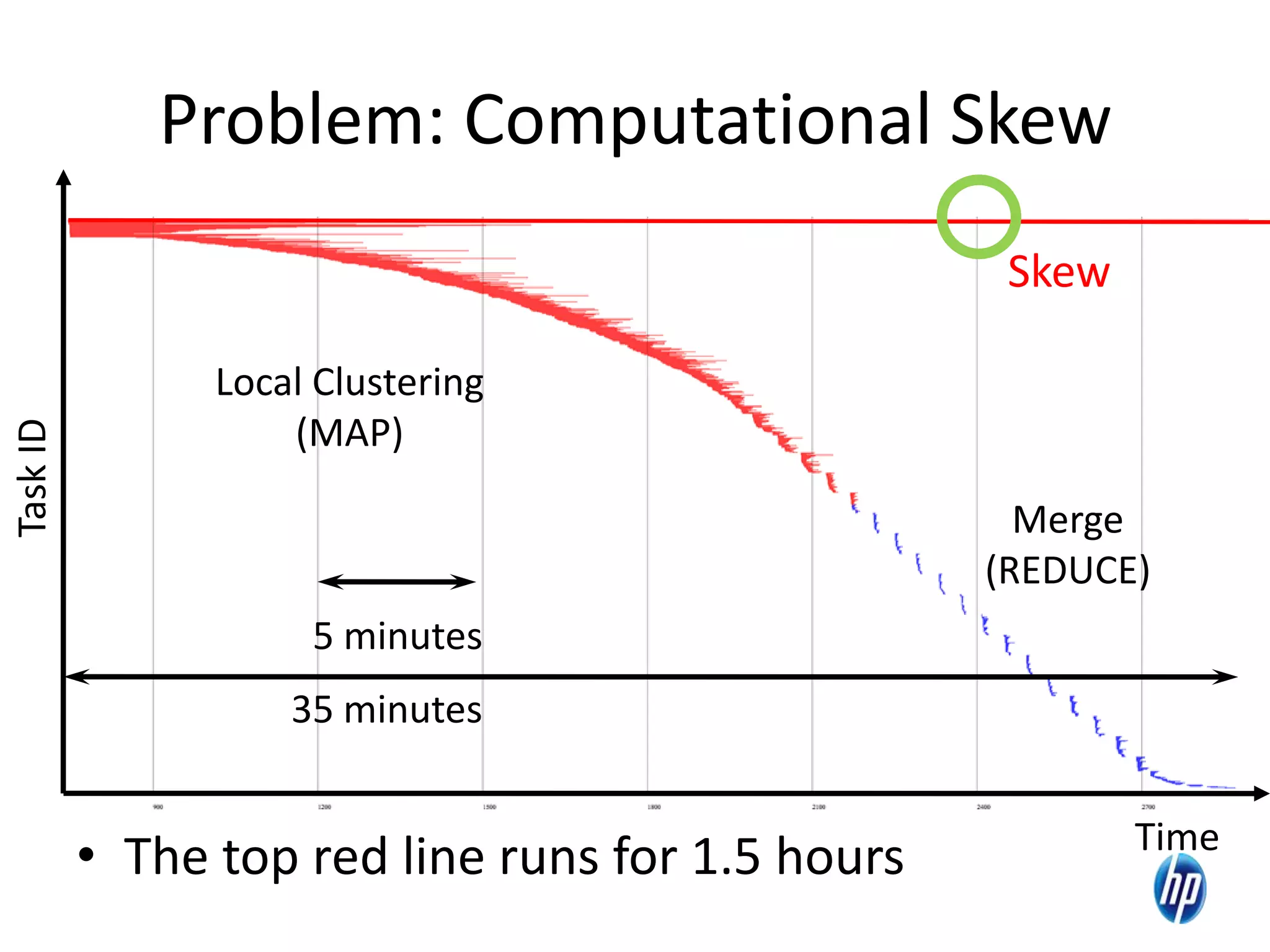
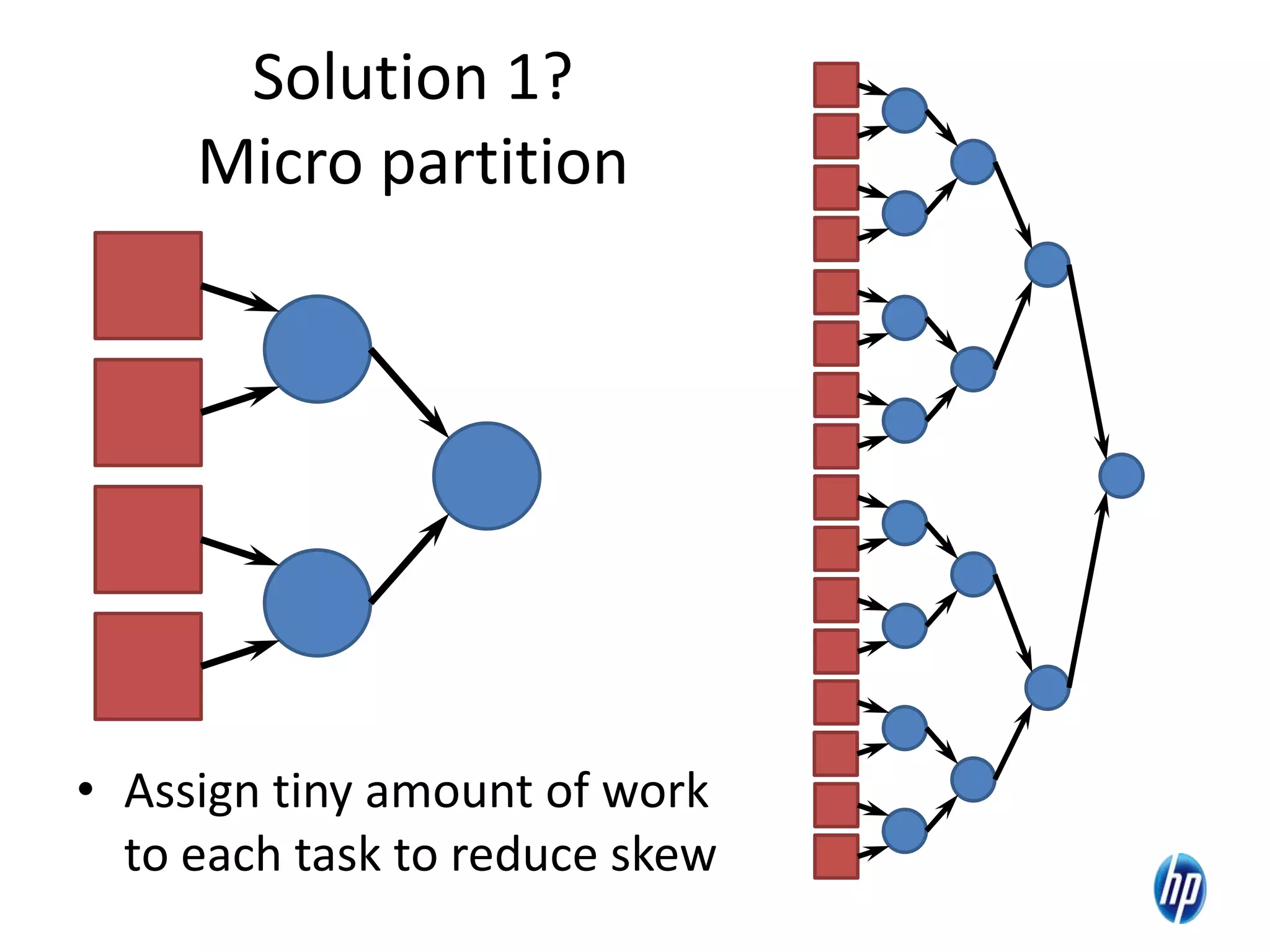
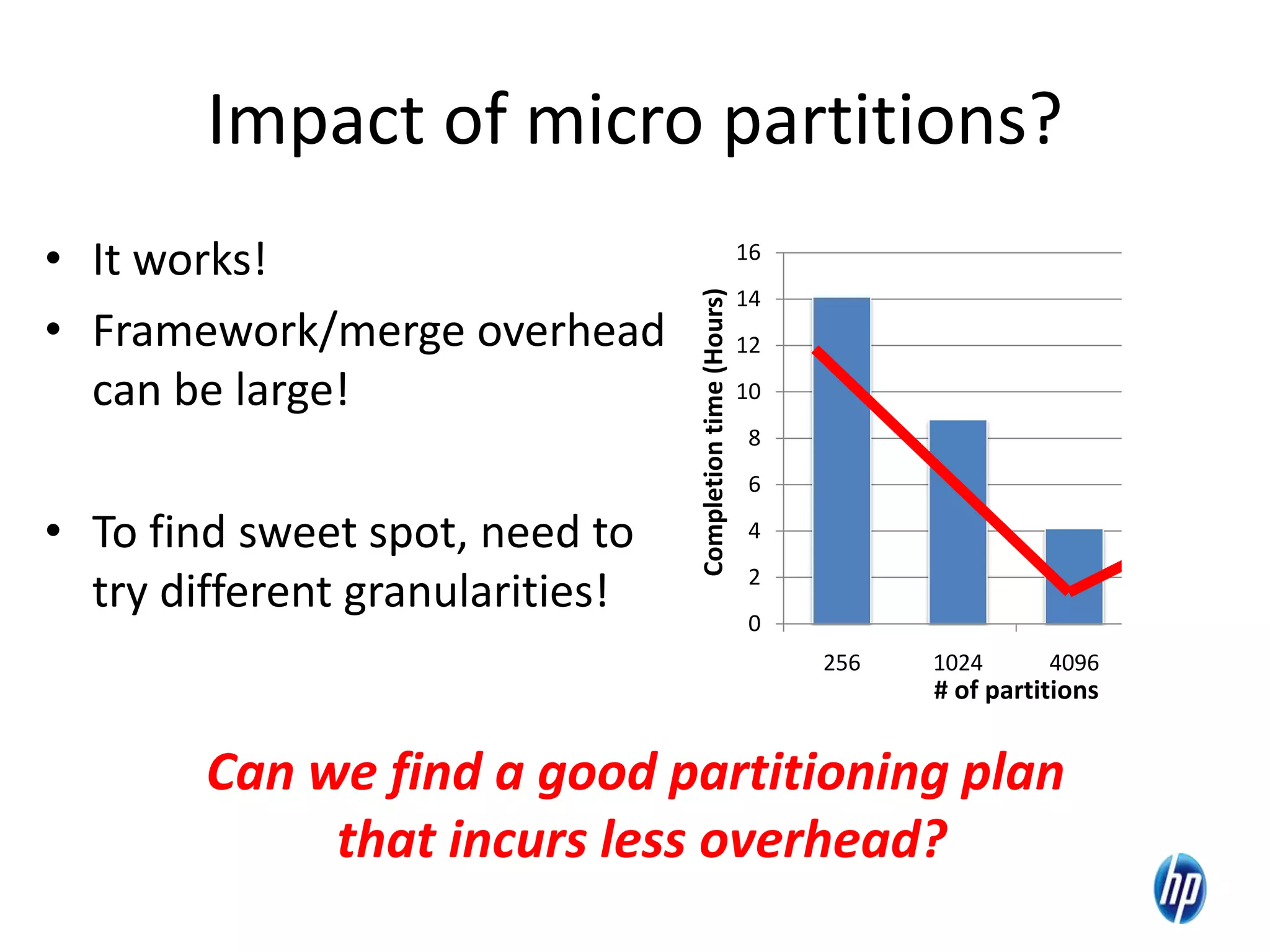
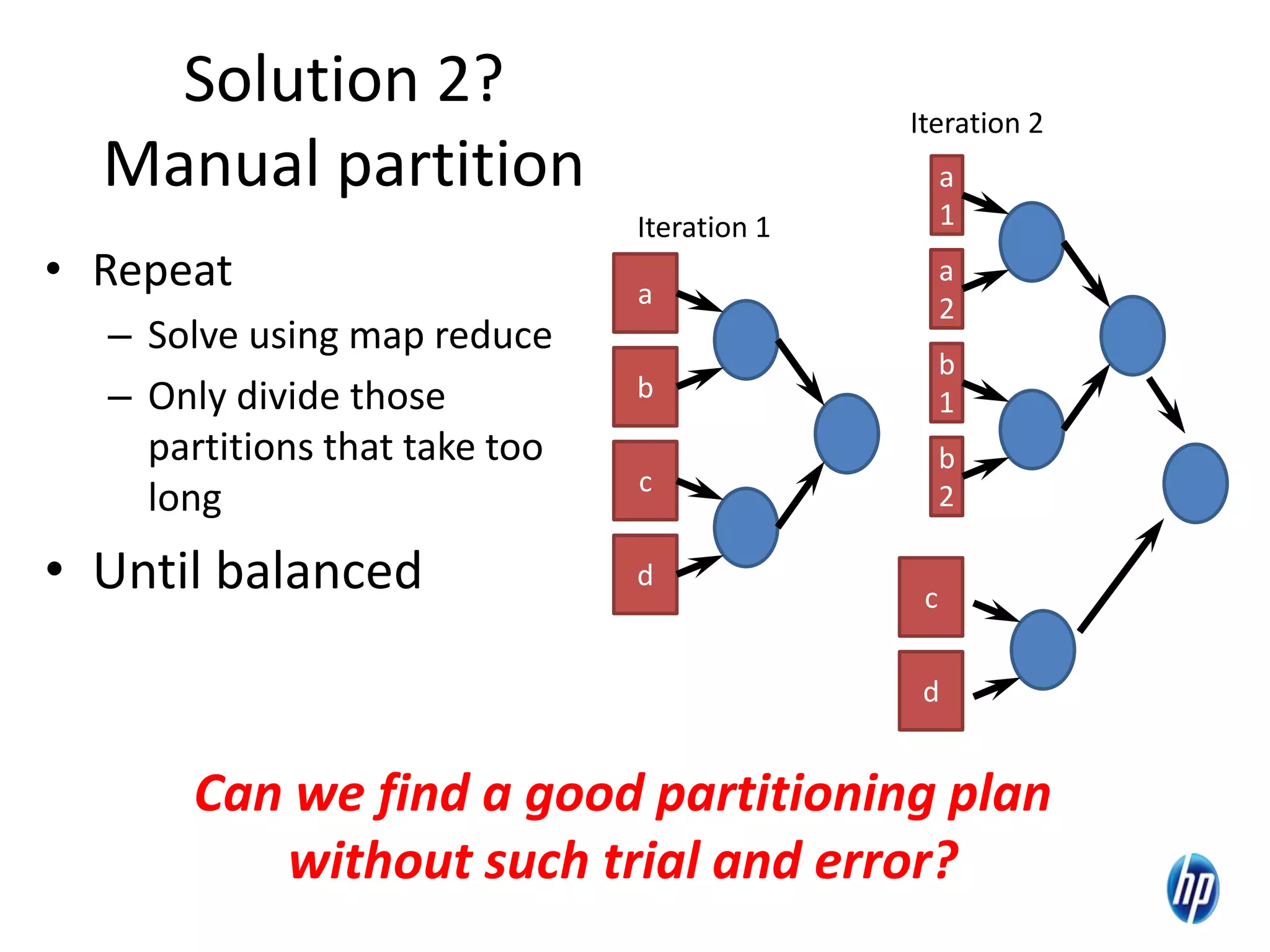
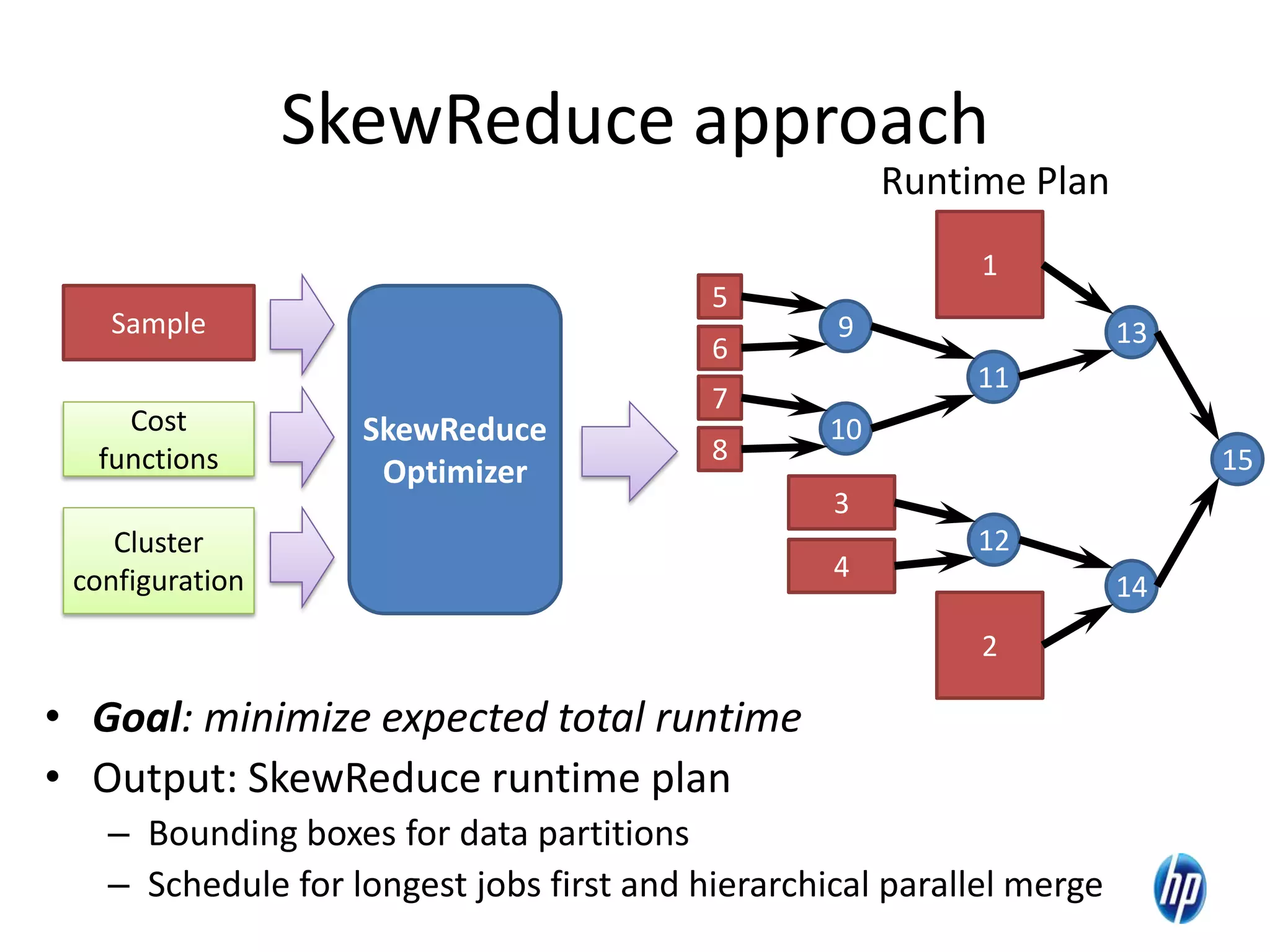


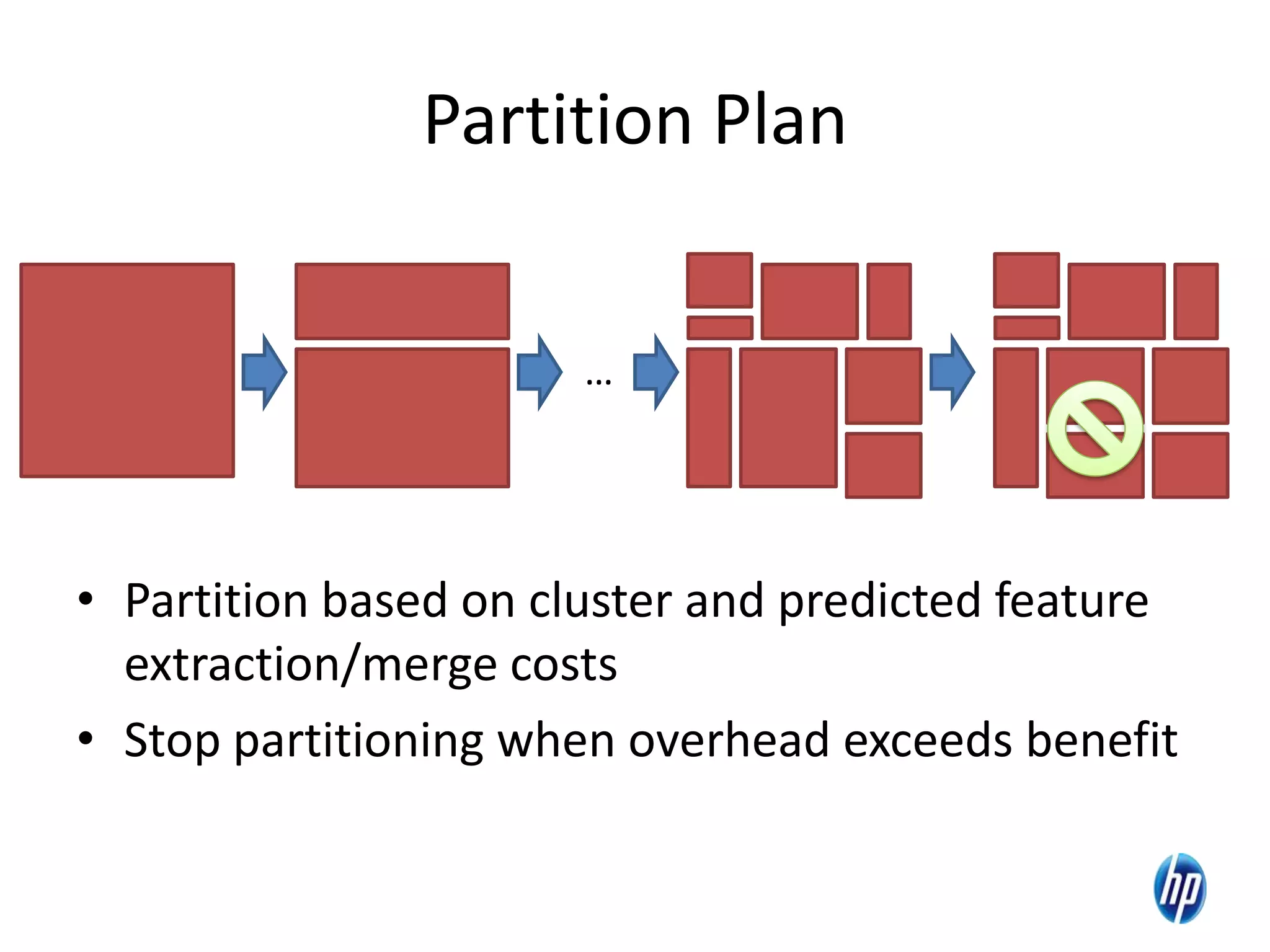

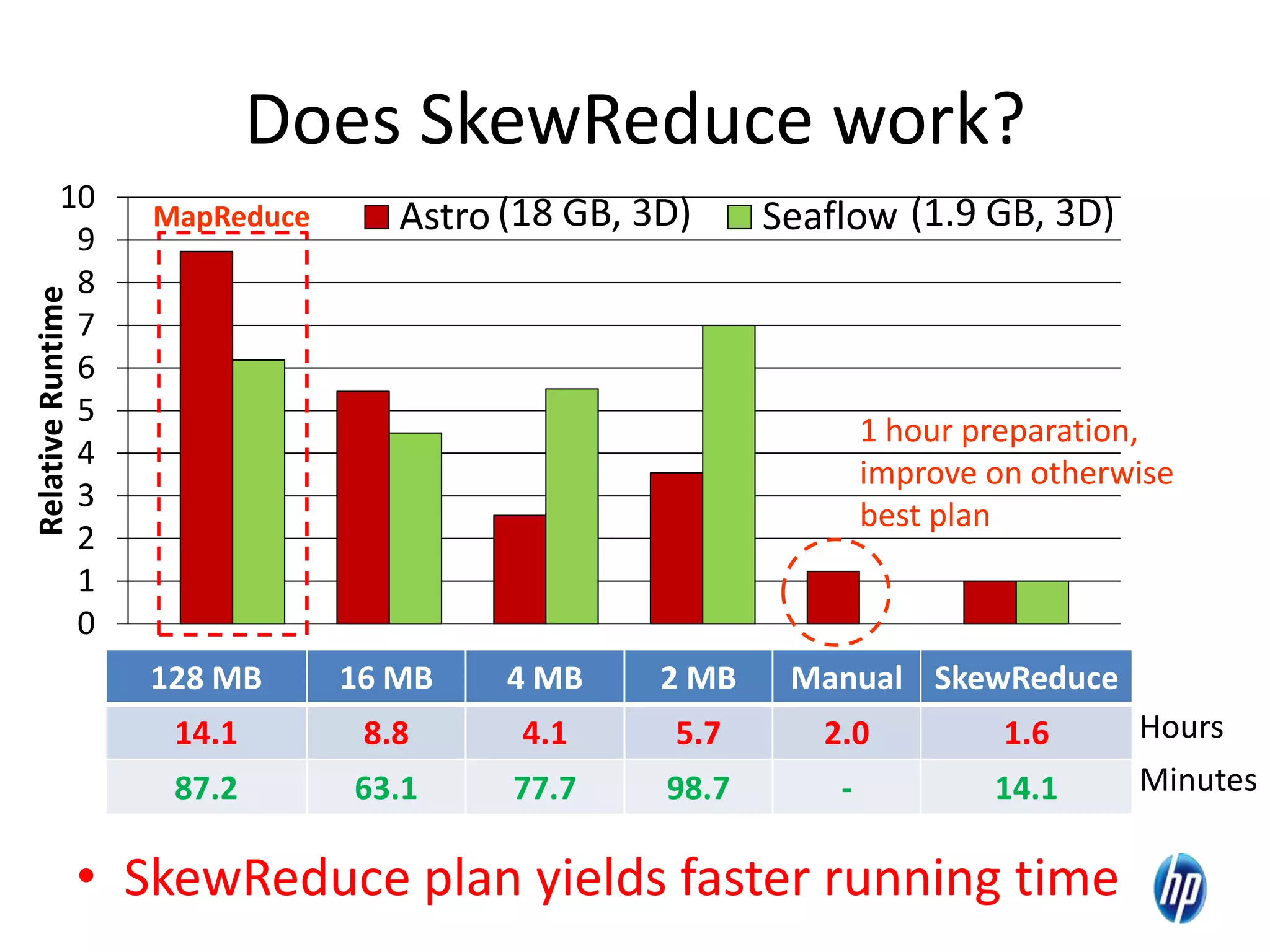
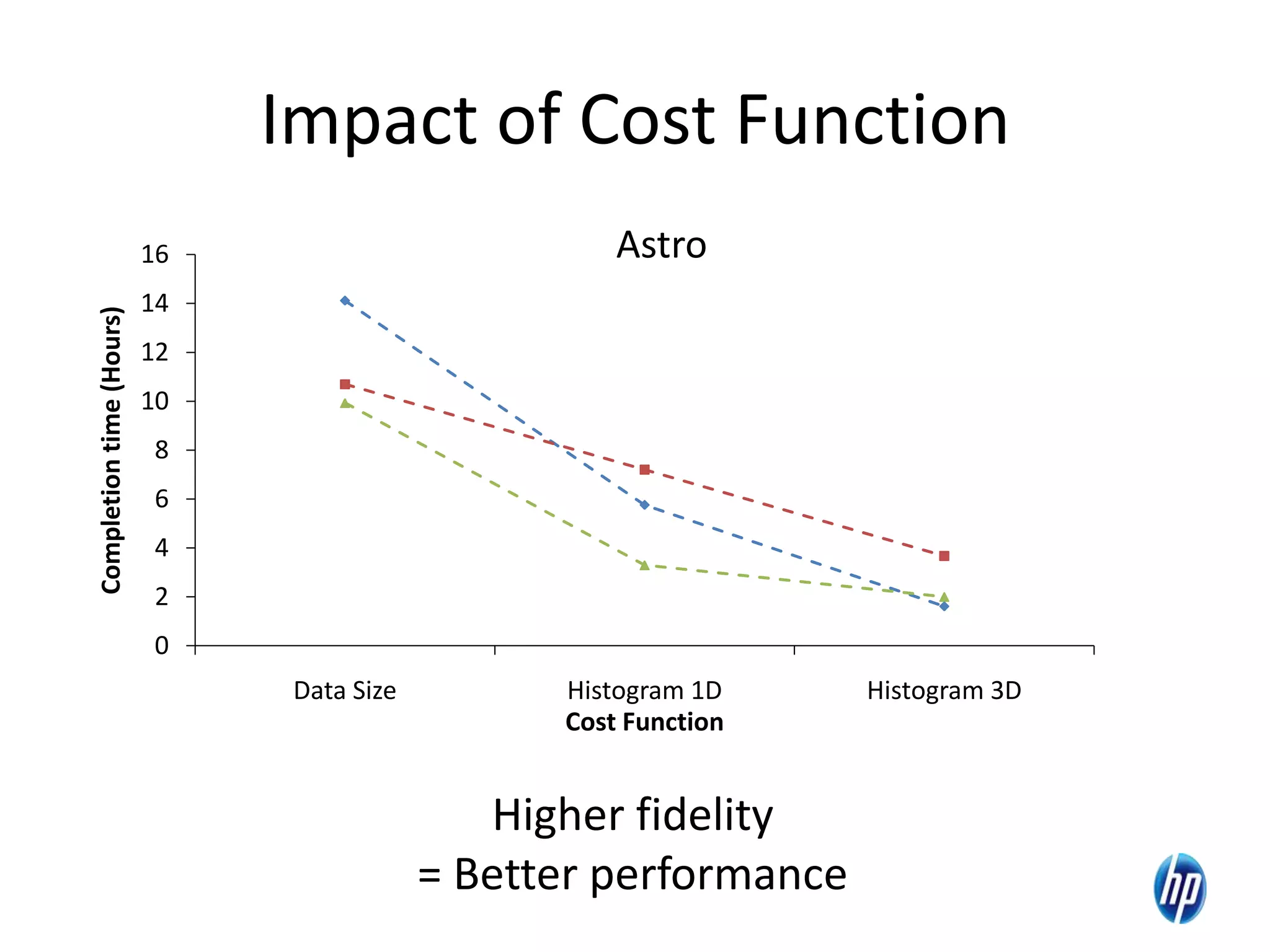



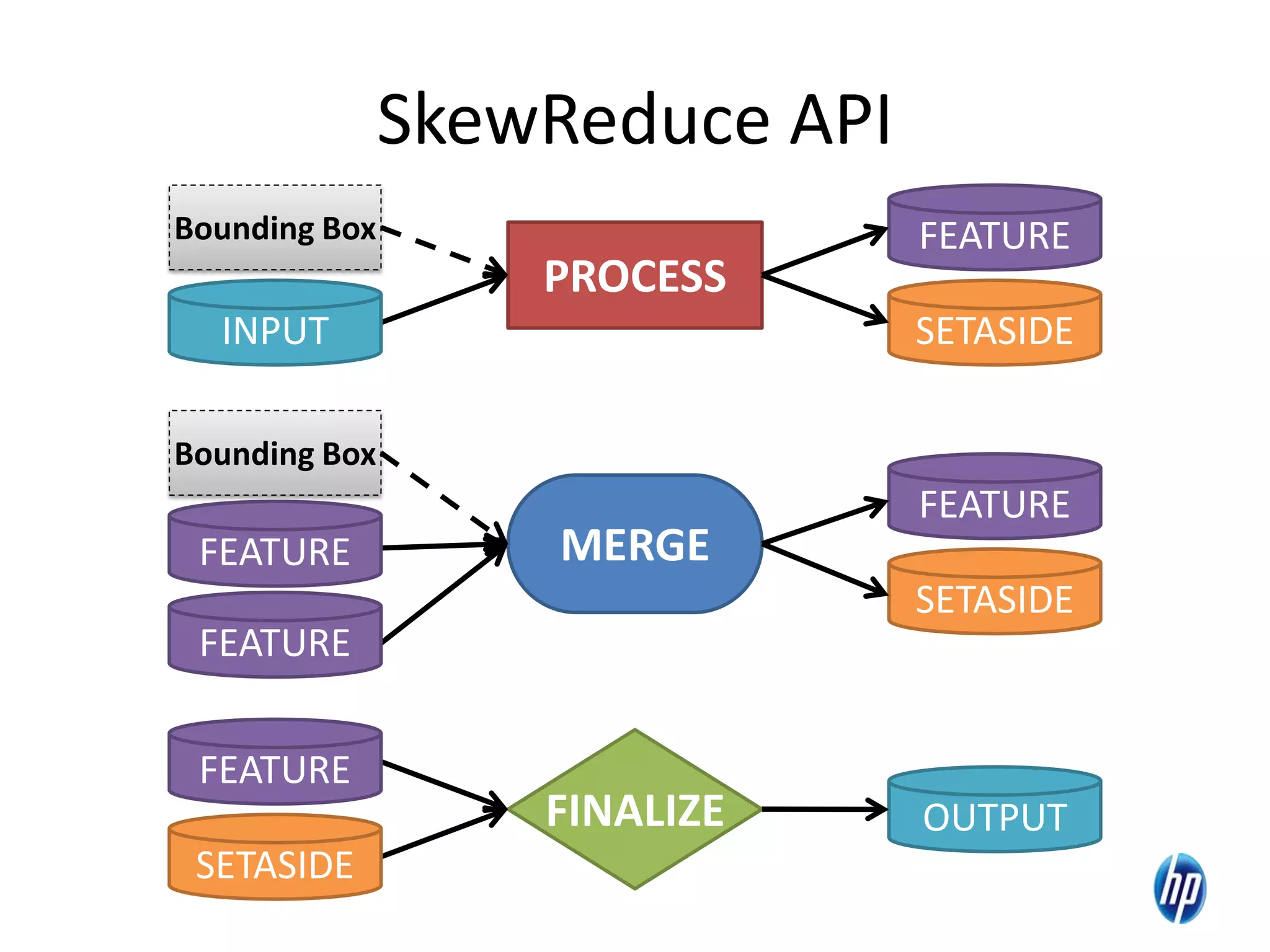
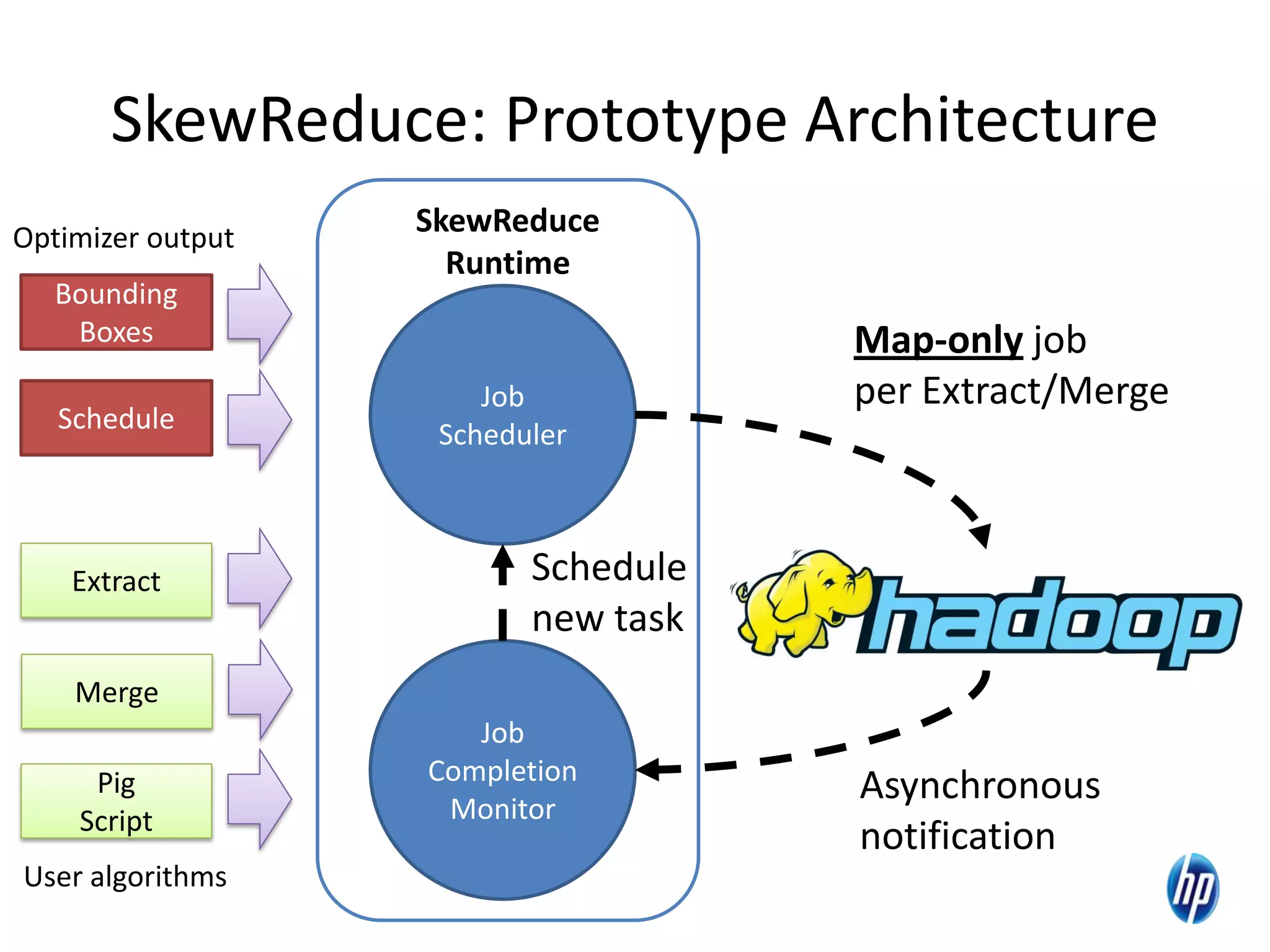



The document discusses the challenges of computational skew in scientific data analysis using Hadoop and MapReduce, highlighting the importance of effective data partitioning for improved performance. It introduces the 'skewreduce' approach, which automates data partitioning and merging plans to optimize processing times across various scientific applications. The evaluation of skewreduce demonstrates significant reductions in runtime, validating its effectiveness in addressing computational skew in large datasets.




































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















