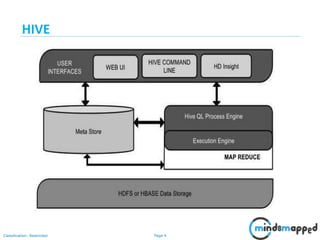
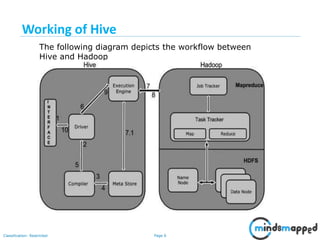
The document provides a comprehensive overview of Hive, a data warehouse infrastructure tool for processing structured data in Hadoop. It covers topics such as HiveQL queries, metadata management, data types, table creation, views, and different types of joins used in data analysis. The document emphasizes Hive's features, such as its SQL-like querying language and integration with Hadoop for analytical processing.














![Page 18Classification: Restricted
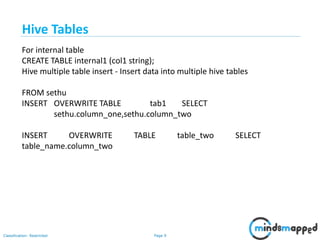
You can save any result set data as a view. The usage of view in Hive is same as
that of the view in SQL.
A view is nothing more than a statement that is stored in the database with an
associated name.
Summarize data from various tables which can be used to generate reports.
Creating Views:
Database views are created using the CREATE VIEW statement.
The basic CREATE VIEW syntax is as follows:
CREATE VIEW view_name AS
SELECT column1, column2.....
FROM table_name
WHERE [condition];
Example:
Hive Database](https://image.slidesharecdn.com/session14-hive-180609010920/85/Session-14-Hive-18-320.jpg)


![Page 21Classification: Restricted
JOIN is a clause that is used for combining specific fields from two tables by using
values common to each one. It is used to combine records from two or more tables in
the database. It is more or less similar to SQL JOIN.
Syntax
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference
join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition]
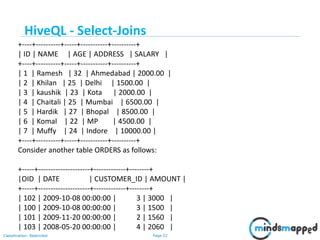
Example
We will use the following two tables in this chapter. Consider the following table
named CUSTOMERS..
HiveQL - Select-Joins](https://image.slidesharecdn.com/session14-hive-180609010920/85/Session-14-Hive-21-320.jpg)