Downloaded 1,697 times





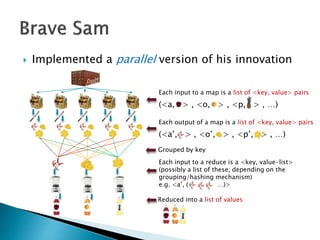
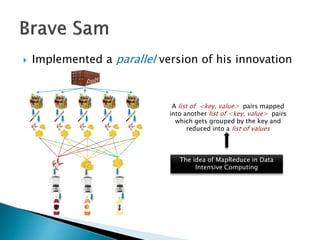



Sam believed an apple a day keeps the doctor away. He cut an apple and used a blender to make juice, applying this process to other fruits. Sam got a job at JuiceRUs for his talent in making juice. He later implemented a parallel version of juice making that involved mapping key-value pairs to other key-value pairs, then grouping and reducing them into a list of values, like the classical MapReduce model. Sam realized he could use a combiner after reducers to create mixed fruit juices more efficiently in a side effect free way.





















































