Downloaded 438 times








![Origin: Functional Programming
Map - Returns a list constructed by applying a function (the first argument) to all
items in a list passed as the second argument
map f [a, b, c] = [f(a), f(b), f(c)]
map sq [1, 2, 3] = [sq(1), sq(2), sq(3)] = [1,4,9]
Reduce - Returns a list constructed by applying a function (the first argument) on
the list passed as the second argument. Can be identity (do nothing).
reduce f [a, b, c] = f(a, b, c)
reduce sum [1, 4, 9] = sum(1, sum(4,sum(9,sum(NULL)))) = 14](https://image.slidesharecdn.com/1-3-161004223421/85/Introduction-to-Map-Reduce-8-320.jpg)
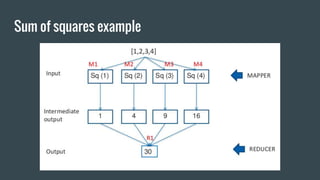
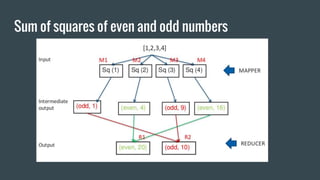

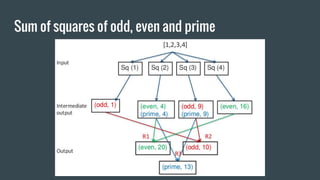
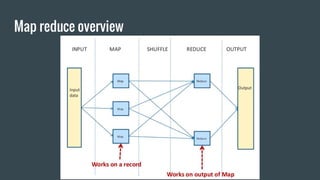
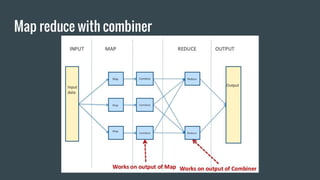
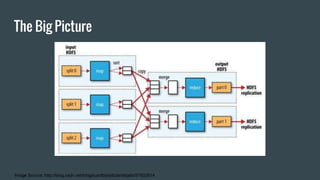
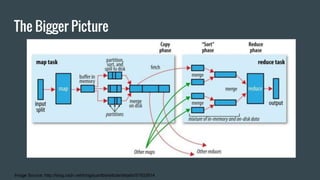













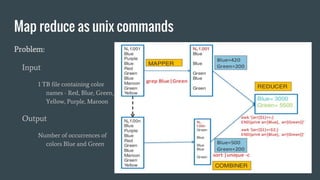

Here is how you can solve this problem using MapReduce and Unix commands: Map step: grep -o 'Blue\|Green' input.txt | wc -l > output This uses grep to search the input file for the strings "Blue" or "Green" and print only the matches. The matches are piped to wc which counts the lines (matches). Reduce step: cat output This isn't really needed as there is only one mapper. Cat prints the contents of the output file which has the count of Blue and Green. So MapReduce has been simulated using grep for the map and cat for the reduce functionality. The key aspects are - grep extracts the relevant data (map























































































