Downloaded 19 times
















































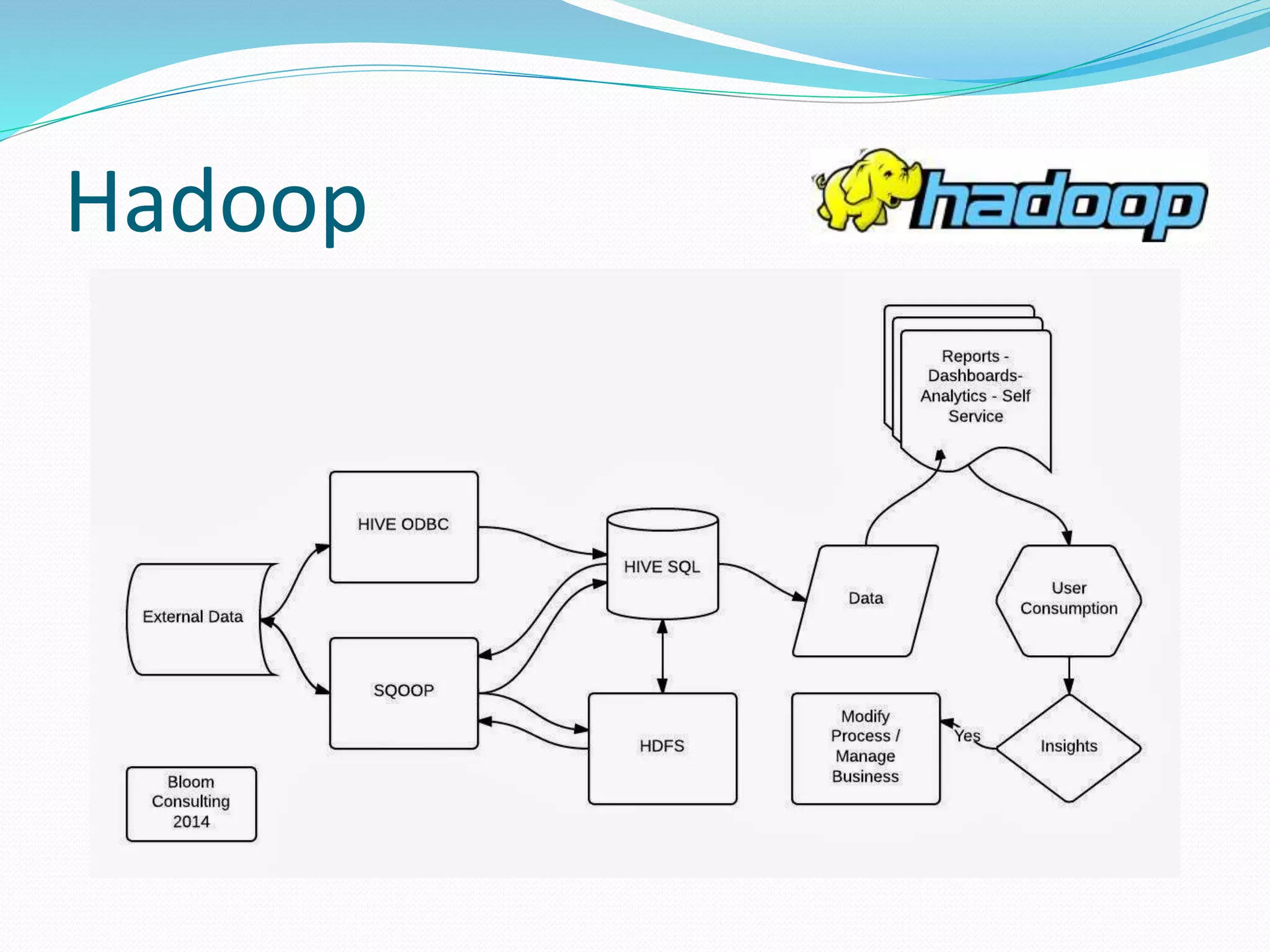




The document presents an overview of Hadoop, detailing its versions, functionalities, and ecosystem components like MapReduce, Hive, and Pig. It emphasizes Hadoop's capability for handling large datasets, its architecture, and tools for data ingestion and processing, such as Sqoop and Flume. The discussion includes advancements in Hadoop 2.0, particularly the introduction of YARN for resource management and improvements in data querying through Impala.
















































































