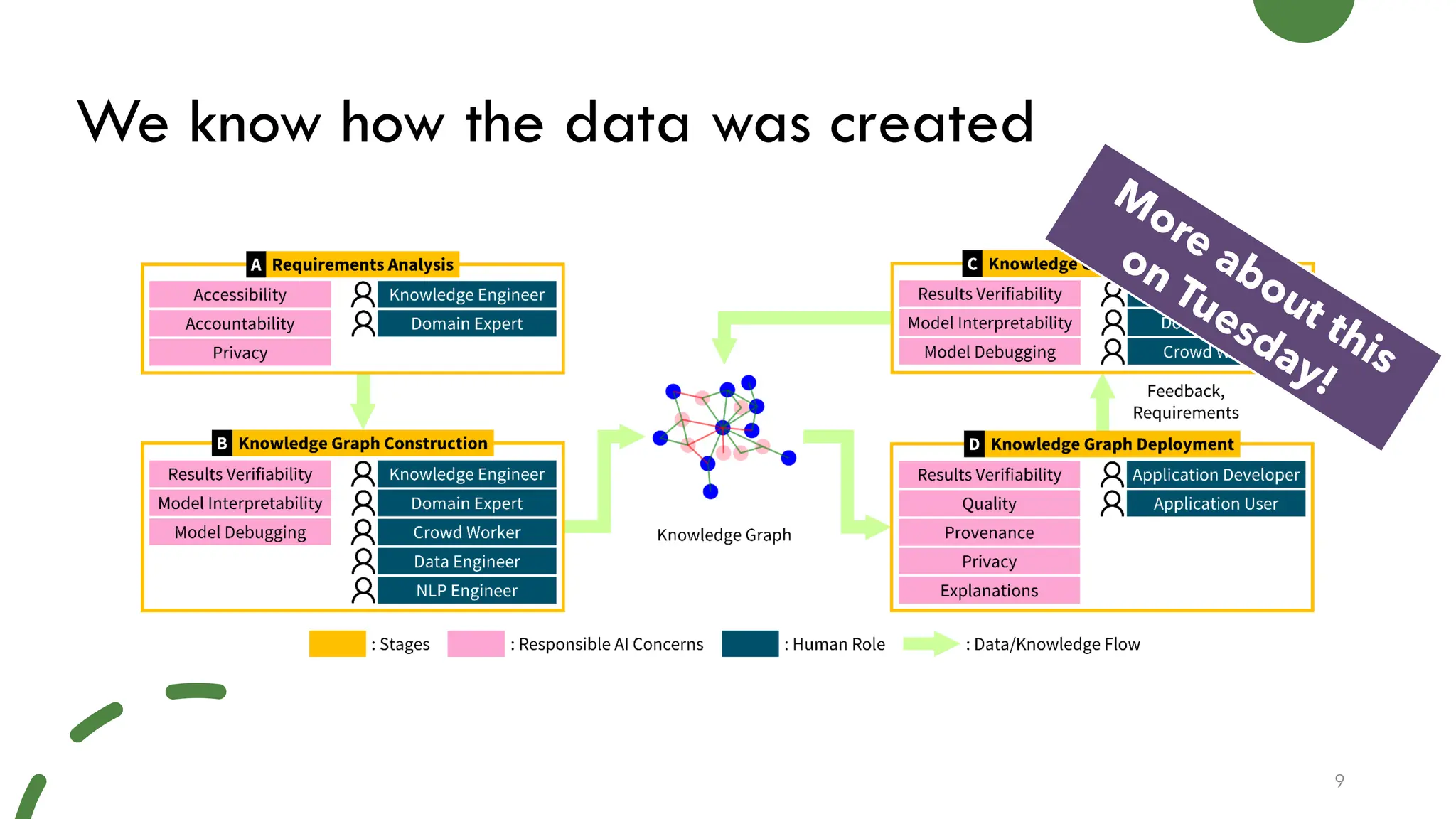
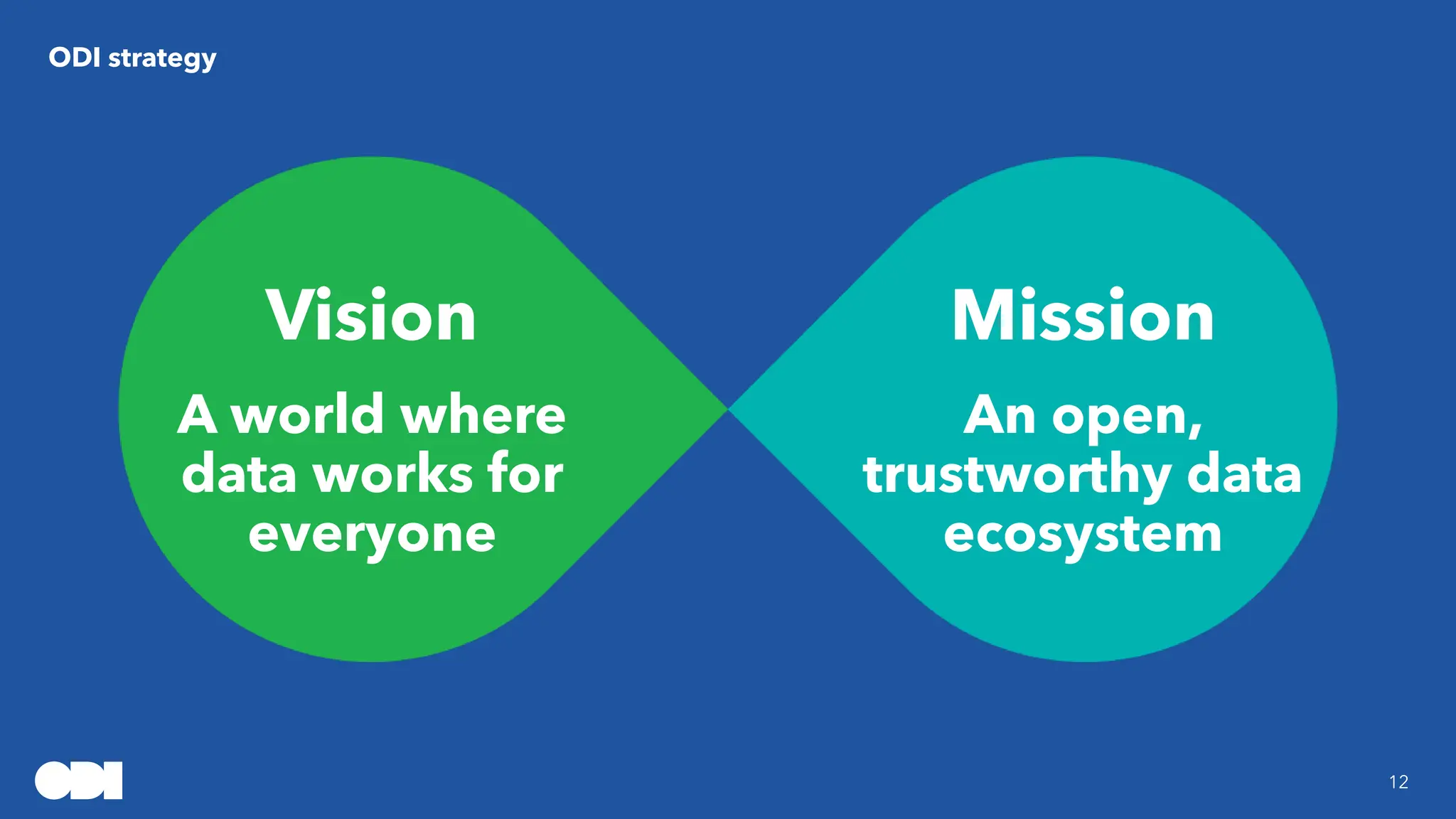
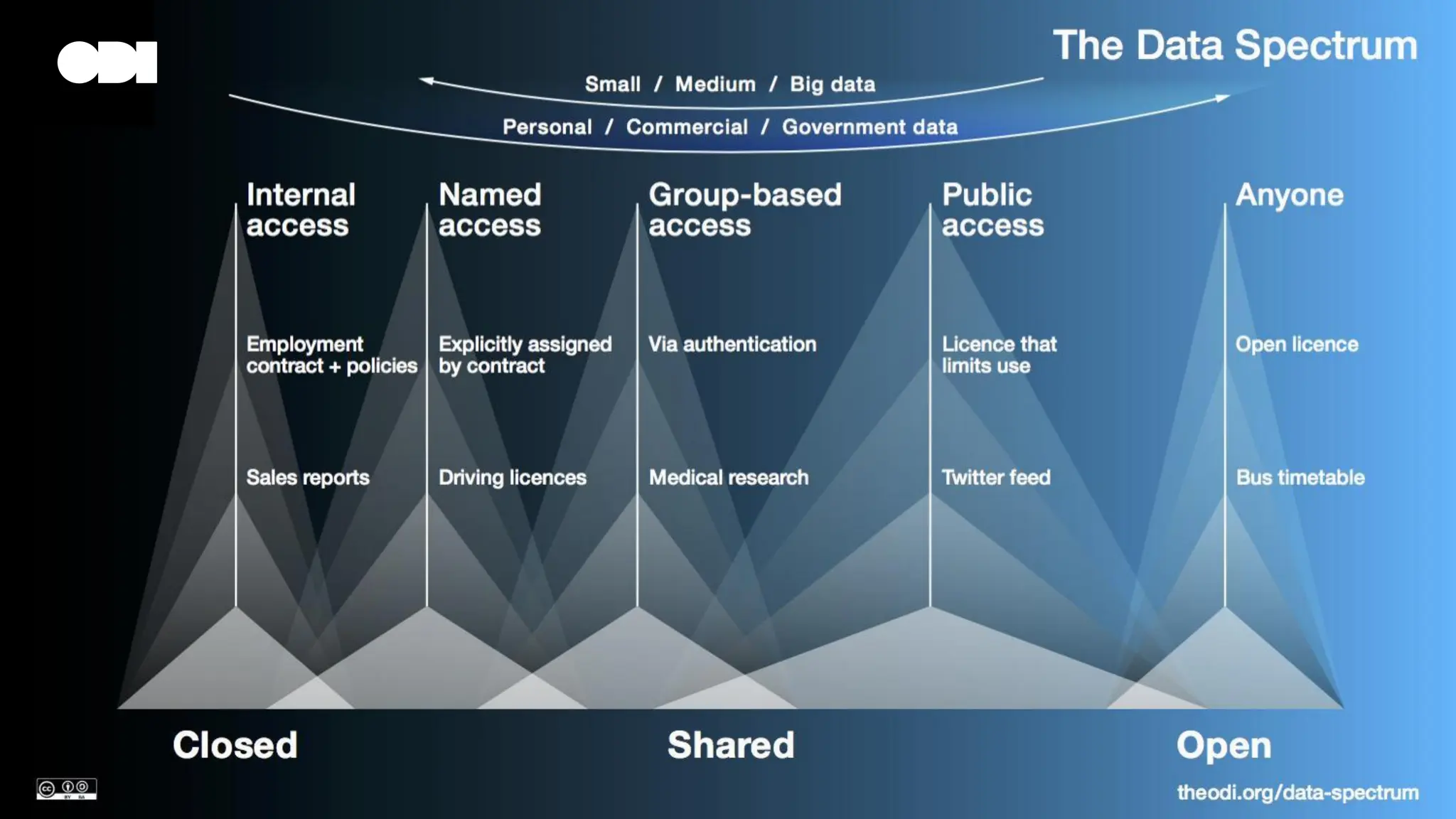
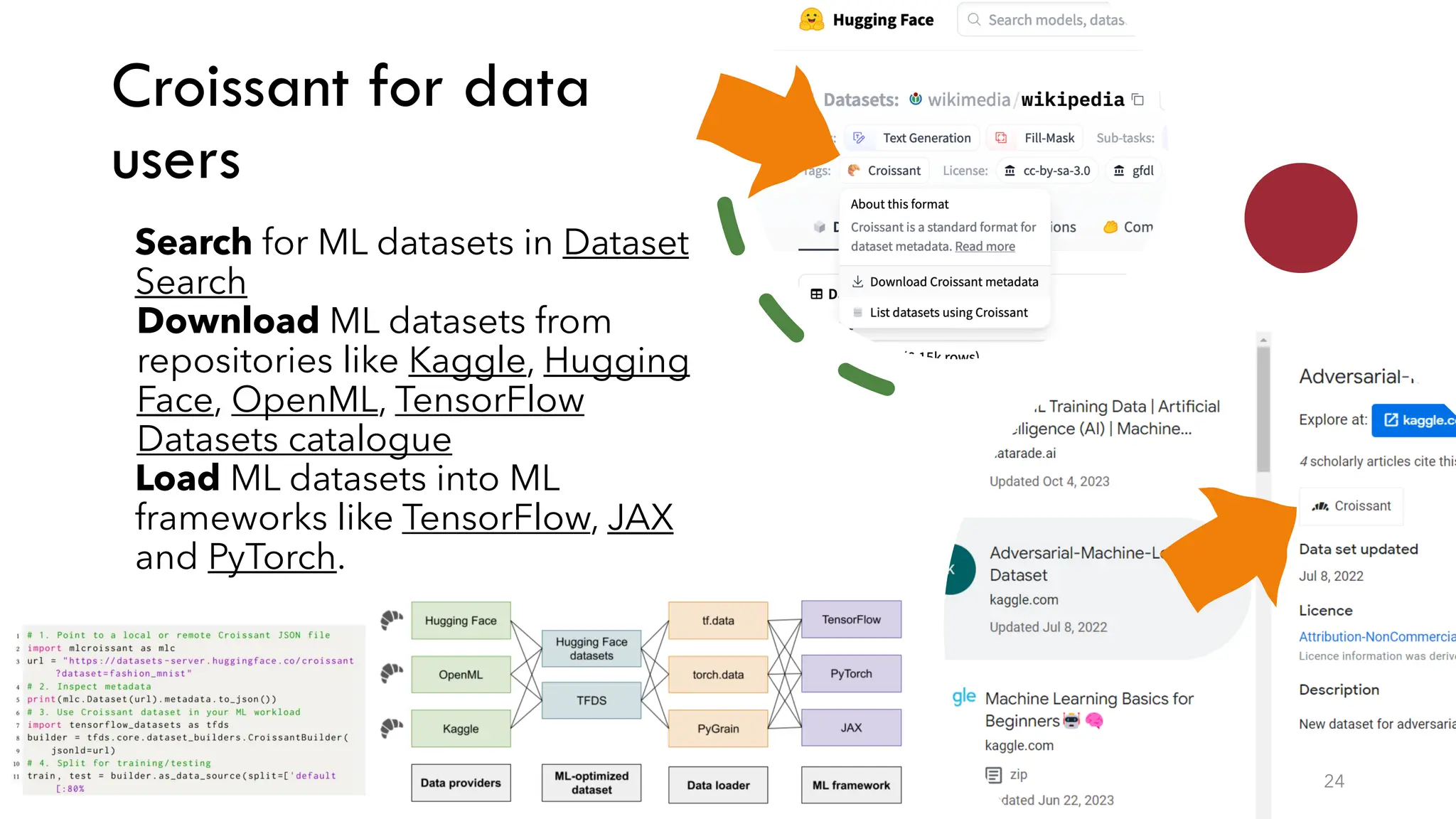
Elena Simperl's workshop discusses the intersection of data quality, knowledge graphs, and machine learning, emphasizing the importance of data in AI systems. The research focuses on improving the quality and trustworthiness of knowledge graphs while exploring methods to minimize biases. Additionally, the ODI's strategies aim to enhance AI data access, establish best practices, and promote responsible data use for innovation across various sectors.











































































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)







![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)








