Downloaded 40 times




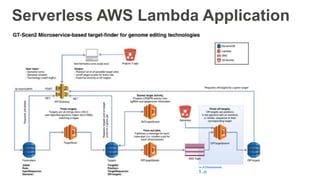


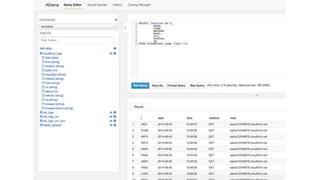





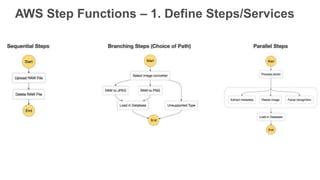
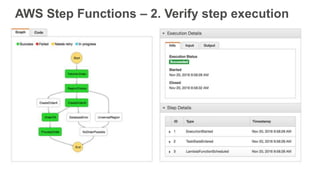

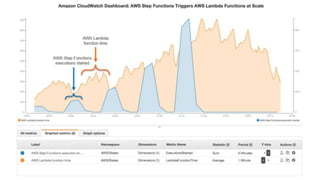

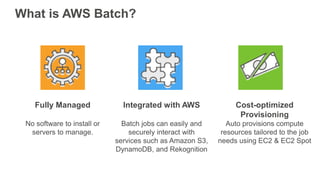


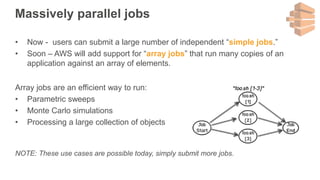
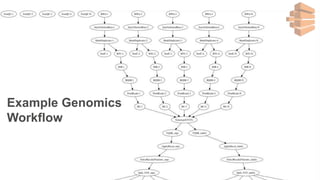





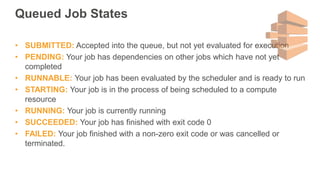
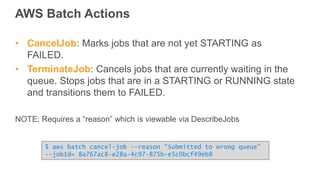




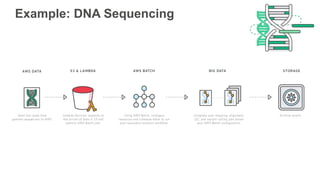
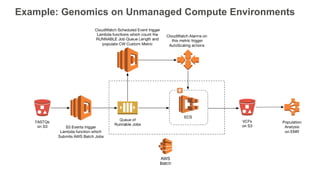



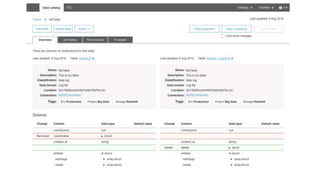
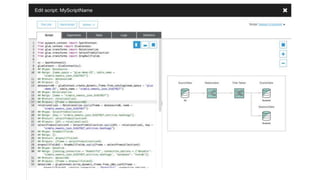
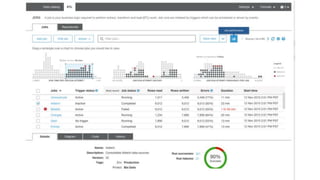


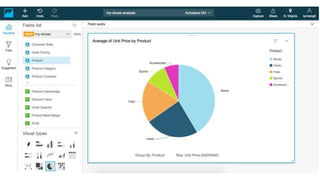


New AWS services were announced at re:Invent 2016 including Athena, Step Functions, Batch, Glue, and QuickSight that could be useful for scaling bioinformatics pipelines. Athena allows SQL queries on data stored in S3, Step Functions allows creating serverless visual workflows using Lambda functions, and Batch provides fully managed batch processing at scale across AWS services. Glue provides serverless ETL capabilities, and QuickSight allows creating quick data dashboards. Examples were shown of using these services for genomics workflows, running jobs on unmanaged compute environments, and processing genomic data.












































































