Download as PDF, PPTX




















![3.5 Init and run reduce()
2. Build one patricia tree per (reduce) shard
reduce_init(): # called once per reducer before it starts
self.patricia = Patricia()
self.tempkeyvaluestore = TempKeyValueStore
reducer(shard_key, list of key_value pairs):
for (key, value) in list of key_value pairs:
self.tempkeyvaluestore[key] = value](https://image.slidesharecdn.com/mapreducestratapresentation-121001102150-phpapp02/85/Mapreduce-Algorithms-23-320.jpg)


![3.8 Mapreduce Approach - 5
Generated file format below, and
corresponding patricia tree to the
right
00000000038["", {"r": "00000000038"}]
00000000060["", {"om": "00000000098", "ub": "00000000290"}]
00000000062["", {"ulus": "00000000265", "an": "00000000160"}]
00000000059["", {"e": "00000000219", "us": "00000000242"}]
00000000023["one", ""]
00000000023["two", ""]
00000000025["three", ""]
00000000059["", {"ic": "00000000456", "e": "00000000349"}]
00000000059["", {"r": "00000000432", "ns": "00000000408"}]
00000000024["four", ""]
00000000024["five", ""]
00000000063["", {"on": "00000000519", "undus": "00000000542"}]
00000000023["six", ""]
00000000025["seven", ""]](https://image.slidesharecdn.com/mapreducestratapresentation-121001102150-phpapp02/85/Mapreduce-Algorithms-26-320.jpg)











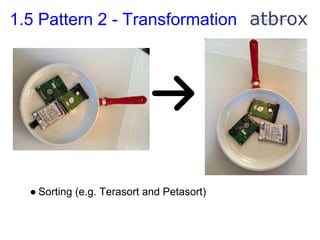
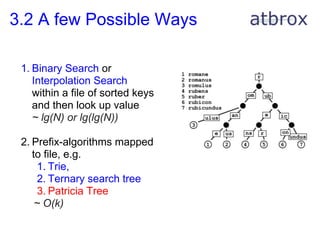
This document provides a summary of MapReduce algorithms. It begins with background on the author's experience blogging about MapReduce algorithms in academic papers. It then provides an overview of MapReduce concepts including the mapper and reducer functions. Several examples of recently published MapReduce algorithms are described for tasks like machine learning, finance, and software engineering. One algorithm is examined in depth for building a low-latency key-value store. Finally, recommendations are provided for designing MapReduce algorithms including patterns, performance, and cost/maintainability considerations. An appendix lists additional MapReduce algorithms from academic papers in areas such as AI, biology, machine learning, and mathematics.











































































