Downloaded 151 times







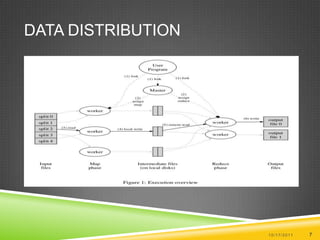









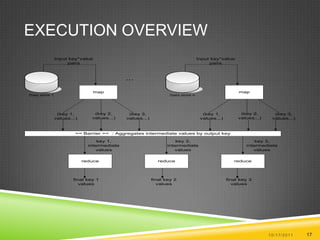





Map Reduce is a parallel and distributed approach developed by Google for processing large data sets. It has two key components - the Map function which processes input data into key-value pairs, and the Reduce function which aggregates the intermediate output of the Map into a final result. Input data is split across multiple machines which apply the Map function in parallel, and the Reduce function is applied to aggregate the outputs.


































































