Downloaded 485 times




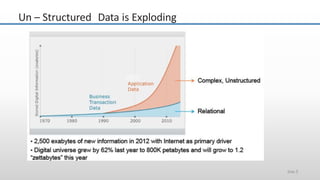
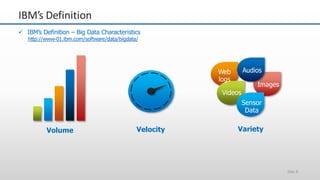



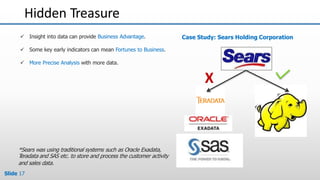
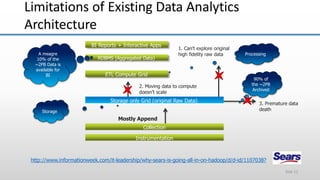
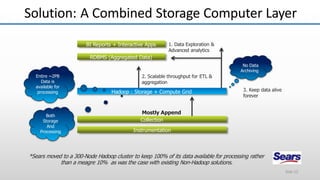
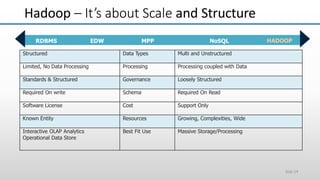
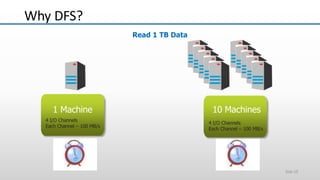
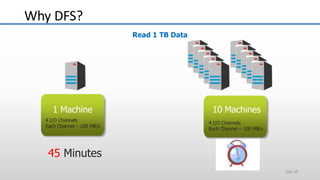
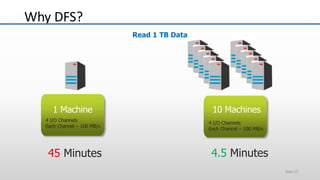

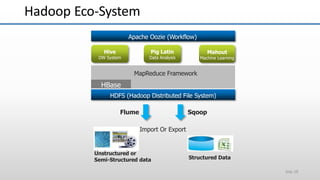
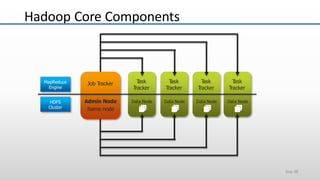







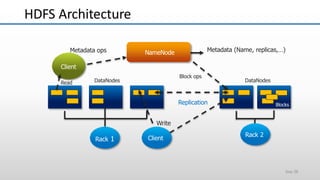
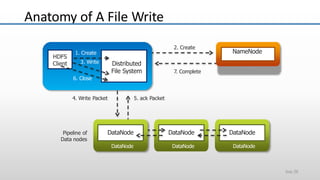
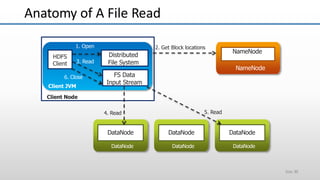
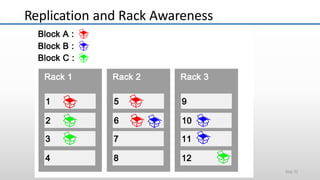
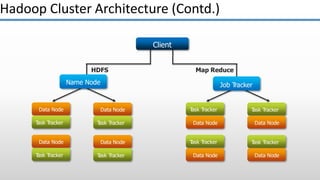
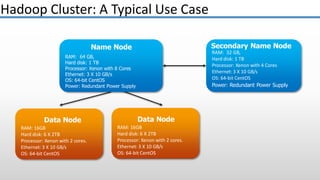

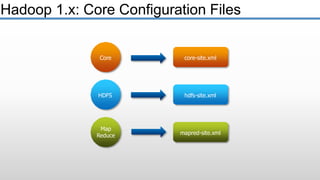

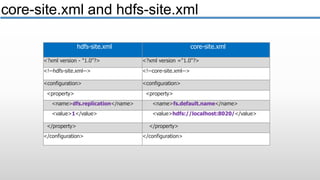

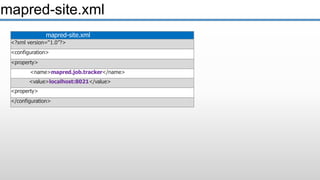
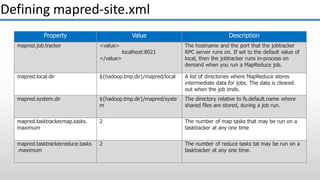
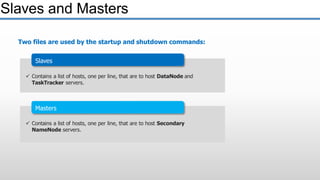

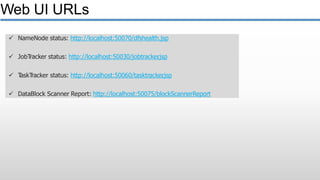










The document provides an overview of big data and its characteristics, explaining its challenges and the limitations of traditional data processing tools. It introduces Hadoop as a solution, detailing its components including HDFS (Hadoop Distributed File System) and MapReduce for large-scale data processing, while also discussing various use cases and customer scenarios across different industries. The architecture of Hadoop, including the role of names nodes and data nodes in managing and storing large datasets, is elaborated upon, showcasing its distributed nature and efficiency.




































































![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)





