Downloaded 251 times








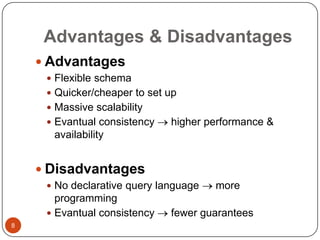


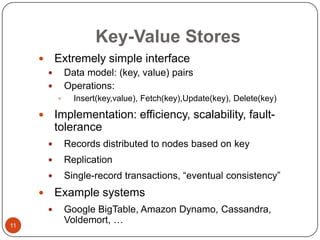




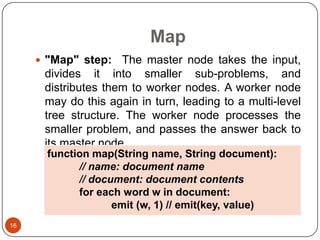

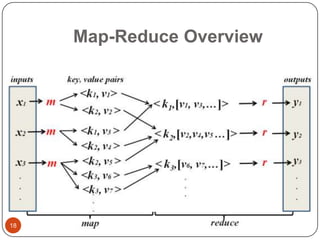

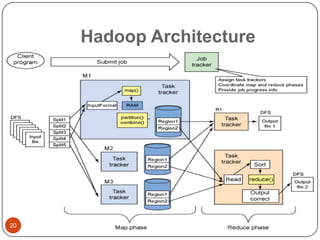

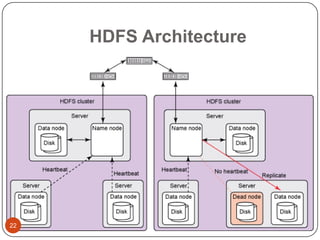



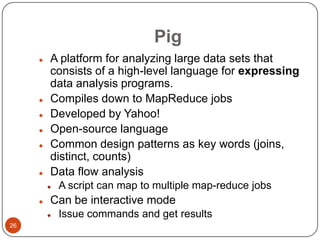
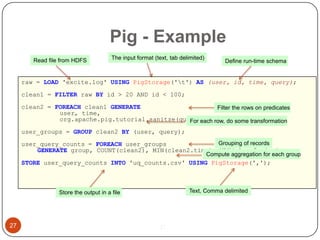


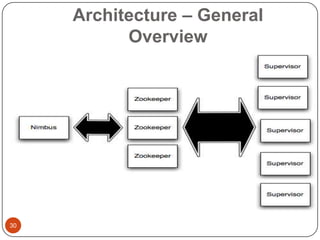

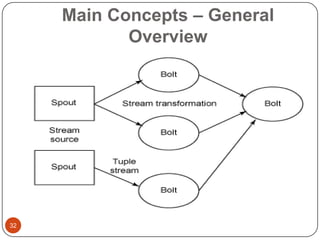



This document provides an overview of big data concepts, including NoSQL databases, batch and real-time data processing frameworks, and analytical querying tools. It discusses scalability challenges with traditional SQL databases and introduces horizontal scaling with NoSQL systems like key-value, document, column, and graph stores. MapReduce and Hadoop are described for batch processing, while Storm is presented for real-time processing. Hive and Pig are summarized as tools for running analytical queries over large datasets.






























































































