Downloaded 156 times













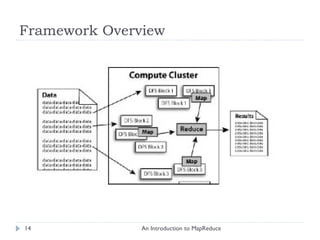
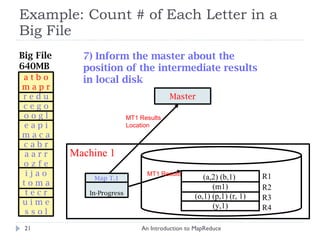
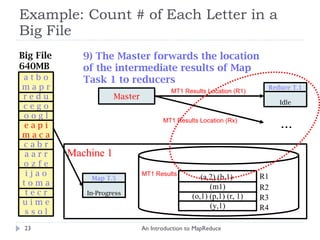
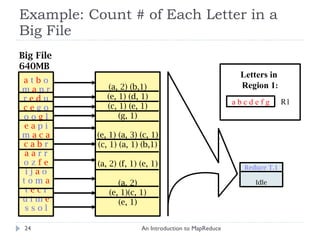
![Example: Count # of Each Letter in a Big File An Introduction to MapReduce Big File 640MB Master 1) Split File into 10 pieces of 64MB R = 4 output files (Set by the user) a t b o m a p r r e d u c e g o o o g l e a p i m a c a c a b r a a r r o z f e i j a o t o m a t e c r u i m e s s o l Worker Idle Worker Idle Worker Idle (There are 26 different keys letters in the range [a..z]) Worker Idle Worker Idle Worker Idle Worker Idle Worker Idle 1 2 3 4 5 6 7 8 9 10](https://image.slidesharecdn.com/anintroductiontomapreduce-1317730182495-phpapp02-111004071248-phpapp02/85/An-Introduction-To-Map-Reduce-15-320.jpg)
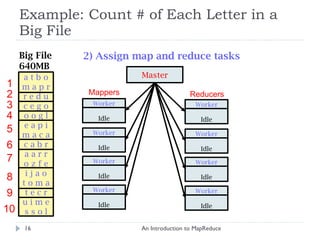

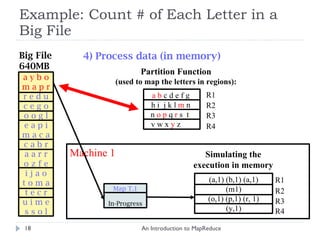
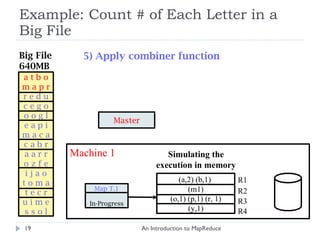















![Hadoop: Word Count Example An Introduction to MapReduce public class WordCount extends Configured implements Tool { ... public static class MapClass extends MapReduceBase implements Mapper < LongWritable , Text , Text , IntWritable > { ... // Map Task Definition } public static class Reduce extends MapReduceBase implements Reducer < Text , IntWritable , Text , IntWritable > { ... // Reduce Task Definition } public int run ( String [] args ) throws Exception { ... // Job Configuration } public static void main ( String [] args ) throws Exception { int res = ToolRunner . run (new Configuration (), new WordCount (), args ); System . exit ( res ); } }](https://image.slidesharecdn.com/anintroductiontomapreduce-1317730182495-phpapp02-111004071248-phpapp02/85/An-Introduction-To-Map-Reduce-41-320.jpg)
![Hadoop: Job Configuration An Introduction to MapReduce public int run ( String [] args ) throws Exception { JobConf conf = new JobConf ( getConf (), WordCount .class); conf . setJobName ( "wordcount"); // the keys are words (strings) conf . setOutputKeyClass ( Text . class); // the values are counts (ints) conf . setOutputValueClass ( IntWritable . class); conf . setMapperClass ( MapClass .class); conf . setCombinerClass ( Reduce .class); conf . setReducerClass ( Reduce .class); conf . setInputPath ( new Path ( args . get (0))); conf . setOutputPath (new Path ( args . get (1))); JobClient . runJob ( conf ); return 0; }](https://image.slidesharecdn.com/anintroductiontomapreduce-1317730182495-phpapp02-111004071248-phpapp02/85/An-Introduction-To-Map-Reduce-42-320.jpg)





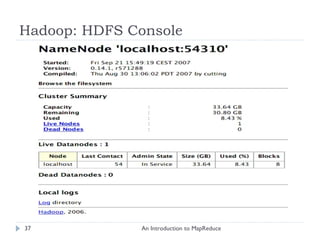
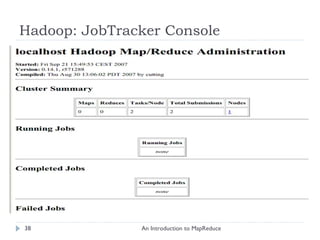
The document provides an introduction to MapReduce, describing its motivation as a framework for simplifying large-scale data processing across distributed systems. It outlines MapReduce's programming model and main features, including automatic parallelization, fault tolerance, and locality. The document also provides a detailed example of counting letter frequencies in a large file to illustrate how MapReduce works.















































