





















![Spark “Word count” continue…
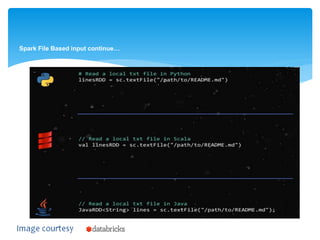
Create an RDD from a file
RDDs can be created from Hadoop InputFormats (such as
HDFS files) or by transforming other RDDs. The following
code uses the SparkContext to define a base RDD from the
file inputFile
Parallelized collections are created by calling
JavaSparkContext’s parallelize method on an existing
Collection in your driver program
// Create a Java Spark Context.
String inputFile = args[0];
JavaRDD input = sc.textFile(inputFile);](https://image.slidesharecdn.com/sparkintroduction-151112150341-lva1-app6892/85/Apache-Spark-Introduction-25-320.jpg)



![Spark “Word count” continue…
Output with RDD action saveAsTextFile
Finally, the RDD action saveAsTextFile(path) writes the
elements of the dataset as a text file (or set of text files) in
the outputFile directory
String outputFile = args[1];
// Save the word count back out to a text file, causing evaluation.
counts.saveAsTextFile(outputFile);](https://image.slidesharecdn.com/sparkintroduction-151112150341-lva1-app6892/85/Apache-Spark-Introduction-29-320.jpg)
![Spark “Word count” continue…
Running Your Application
You use the bin/spark-submit script to launch your application.
This script takes care of setting up the classpath with Spark
and its dependencies. Here is the spark-submit format:
$./bin/spark-submit --class <main-class> --master <master-url>
<application-jar> [application-arguments]
$bin/spark-submit --class example.wordcount.JavaWordCount --master yarn sparkwordcount-1.0.jar
/user/user01/input/alice.txt /user/user01/output
//Here is the spark-submit command to run the scala SparkWordCount:
$bin/spark-submit --class SparkWordCount --master yarn sparkwordcount-1.0.jar /user/user01/input/alice.txt
/user/user01/output](https://image.slidesharecdn.com/sparkintroduction-151112150341-lva1-app6892/85/Apache-Spark-Introduction-30-320.jpg)













Spark is an open source cluster computing framework for large-scale data processing. It provides high-level APIs and runs on Hadoop clusters. Spark components include Spark Core for execution, Spark SQL for SQL queries, Spark Streaming for real-time data, and MLlib for machine learning. The core abstraction in Spark is the resilient distributed dataset (RDD), which allows data to be partitioned across nodes for parallel processing. A word count example demonstrates how to use transformations like flatMap and reduceByKey to count word frequencies from an input file in Spark.



































































