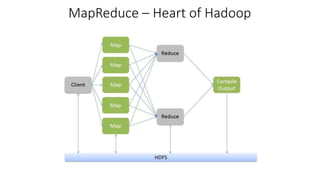
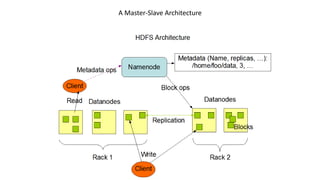
Hadoop DFS consists of HDFS for storage and MapReduce for processing. HDFS provides massive storage, fault tolerance through data replication, and high throughput access to data. It uses a master-slave architecture with a NameNode managing the file system namespace and DataNodes storing file data blocks. The NameNode ensures data reliability through policies that replicate blocks across racks and nodes. HDFS provides scalability, flexibility and low-cost storage of large datasets.