Hadoop MapReduce is an open source framework for distributed processing of large datasets across clusters of computers. It allows parallel processing of large datasets by dividing the work across nodes. The framework handles scheduling, fault tolerance, and distribution of work. MapReduce consists of two main phases - the map phase where the data is processed key-value pairs and the reduce phase where the outputs of the map phase are aggregated together. It provides an easy programming model for developers to write distributed applications for large scale processing of structured and unstructured data.
Overview of Hadoop as an open-source Java project used for large-scale data processing. It's widely utilized by major tech companies.
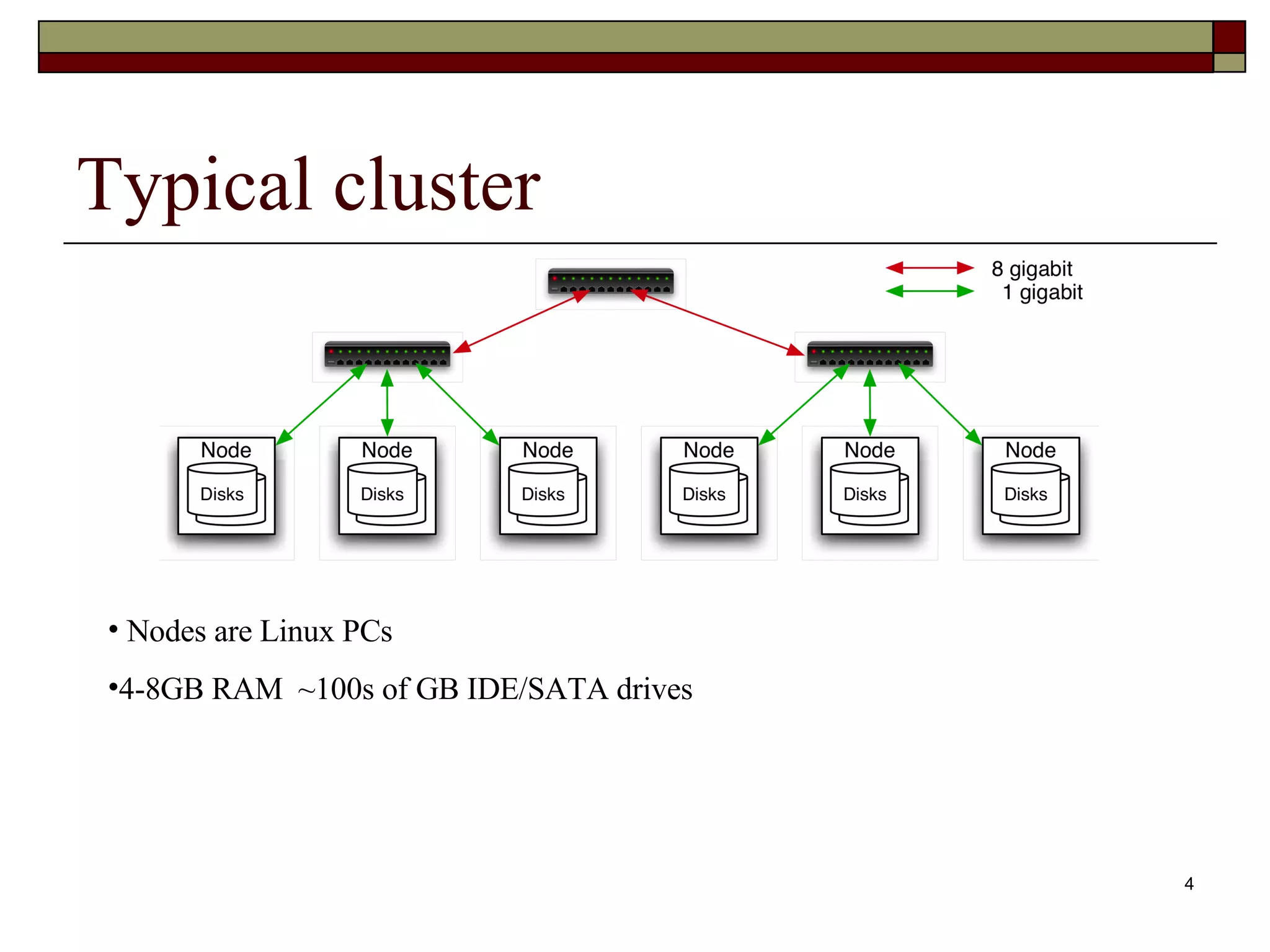
Introduction to Hadoop core components: HDFS for data storage and MapReduce for processing data across clusters. Description of a typical Hadoop cluster with specs and HDFS architecture components: Namenodes and Datanodes.
Explanation of the MapReduce concept, its architecture, and how it enables efficient processing of large data by parallelism.
Details of MapReduce programming with input/output key-value pairs, mapper, and reducer functionalities.
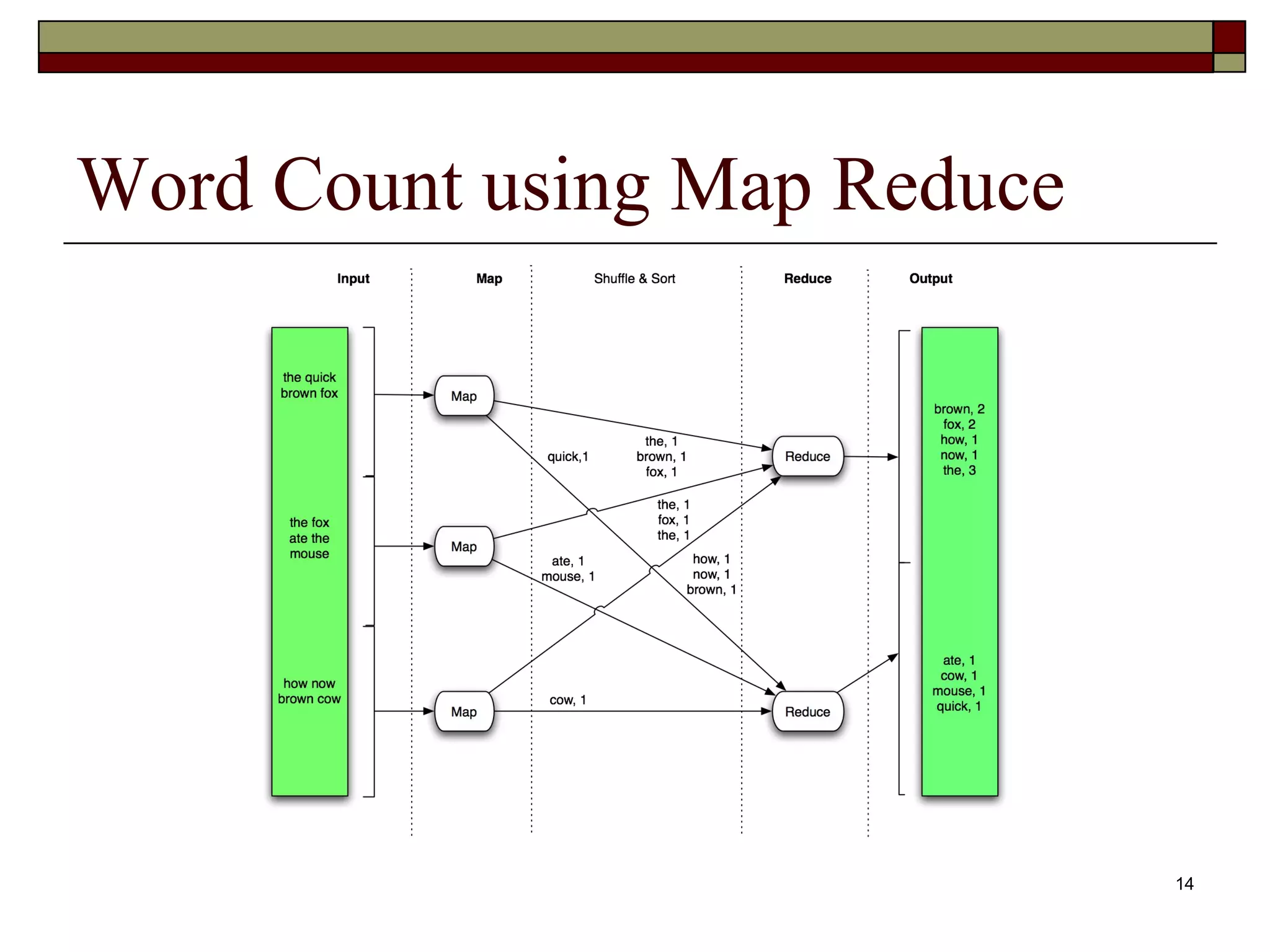
Illustration of the Word Count problem using MapReduce, showing how to count word frequencies and execution phases.Description of the Map and Reduce phases, task assignment, fault tolerance, and advantages of using MapReduce.Summary of MapReduce's benefits in simplifying large-scale distributed applications and its use in various data-driven industries.
Hadoop Map ReduceApurva Jadhav Senior Software Engineer TheFind Inc. (diagrams borrowed from various sources)
2.
Introduction Open sourceproject written in Java Large scale distributed data processing Based on Google’s Map Reduce framework and Google file system Works on commodity hardware Used by a Google, Yahoo, Facebook, Amazon, and many other startups http://wiki.apache.org/hadoop/PoweredBy
3.
Hadoop Core Hadoop Distributed File System (HDFS) Distributes and stores data across a cluster (brief intro only) Hadoop Map Reduce (MR) Provides a parallel programming model Moves computation to where the data is Handles scheduling, fault tolerance Status reporting and monitoring
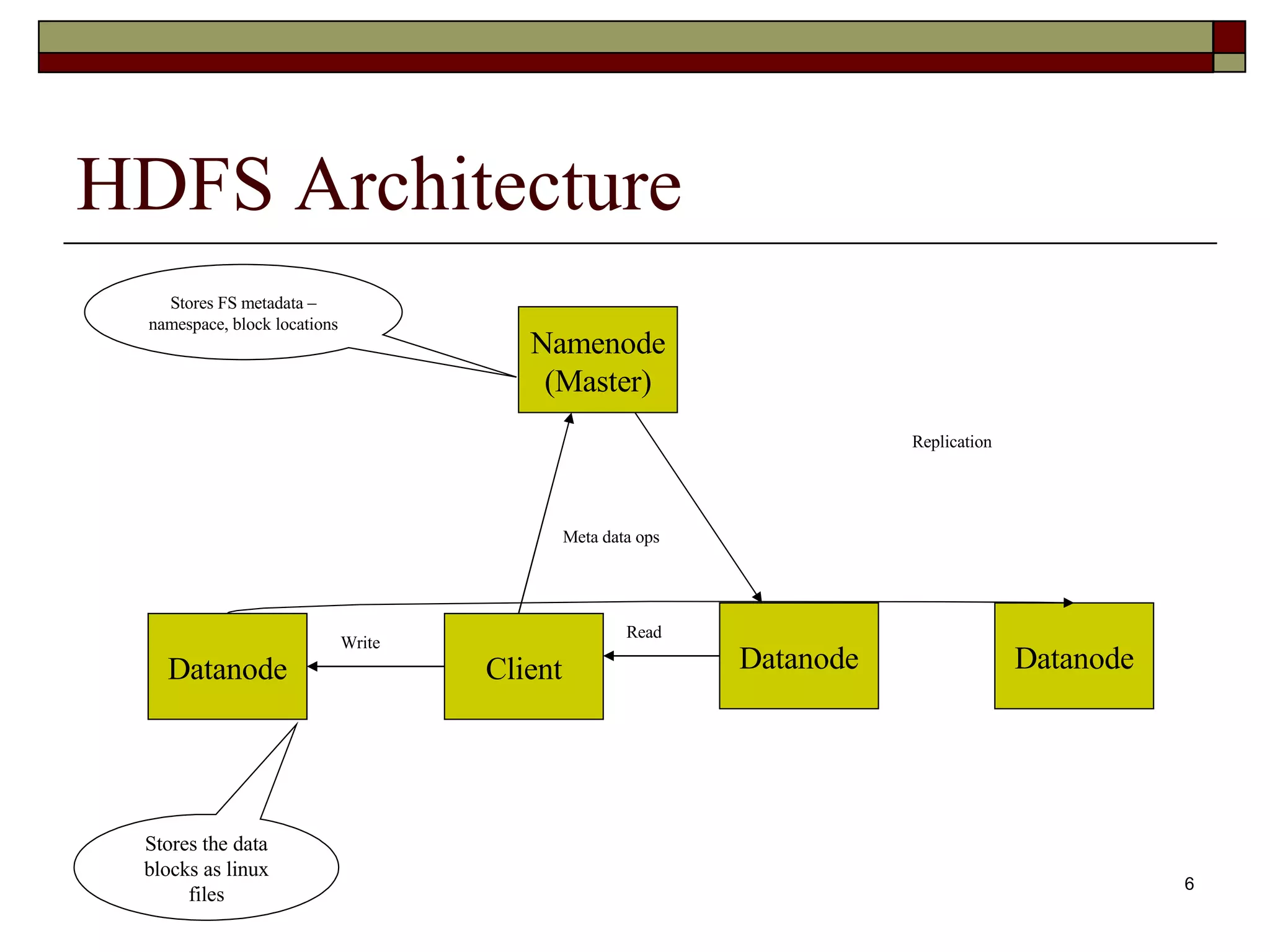
Hadoop Distributed FileSystem Scale to Petabytes across 1000s of nodes Single namespace for entire cluster Files broken into 128MB blocks Block level replication handles node failure Optimized for single write multiple reads Writes are append only
6.
HDFS Architecture Namenode(Master) Datanode Client Datanode Datanode Read Write Replication Meta data ops Stores FS metadata – namespace, block locations Stores the data blocks as linux files
7.
Hadoop Map ReduceWhy Map Reduce Map Reduce Architecture - 1 Map Reduce Programming Model Word count using Map Reduce Map Reduce Architecture - 2
8.
Word Count ProblemFind the frequency of each word in a given corpus of documents Trivial for small data How to process more than a TB of data Doing it on one machine is very slow – takes days to finish! Good News : It can be parallelized across number of machines
9.
Why Map ReduceHow to scale large data processing applications ? Divide the data and process on many nodes Each such application has to handle Communication between nodes Division and scheduling of work fault tolerance monitoring and reporting Map Reduce handles and hides all these issues Provides a clean abstraction for programmer
10.
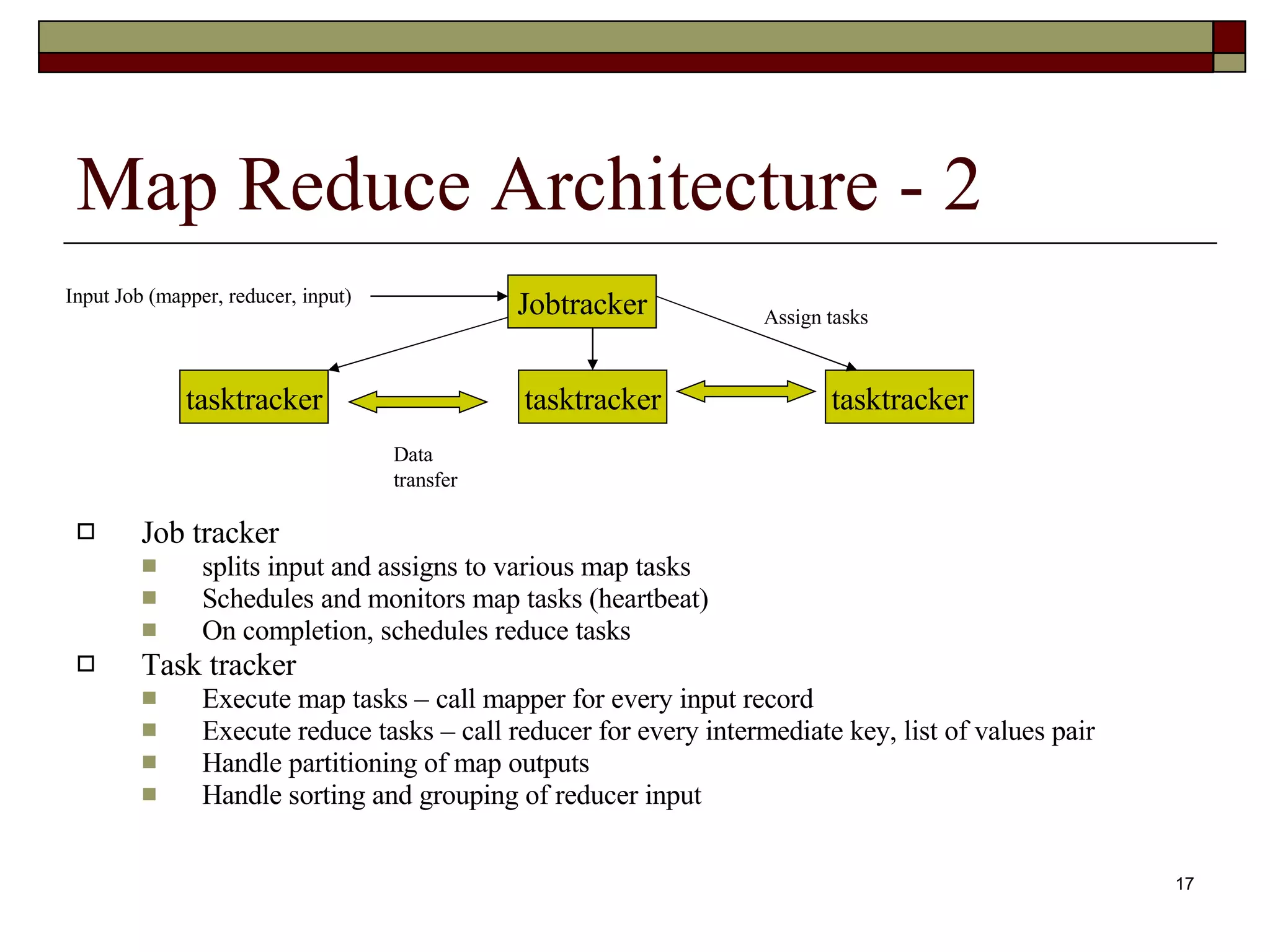
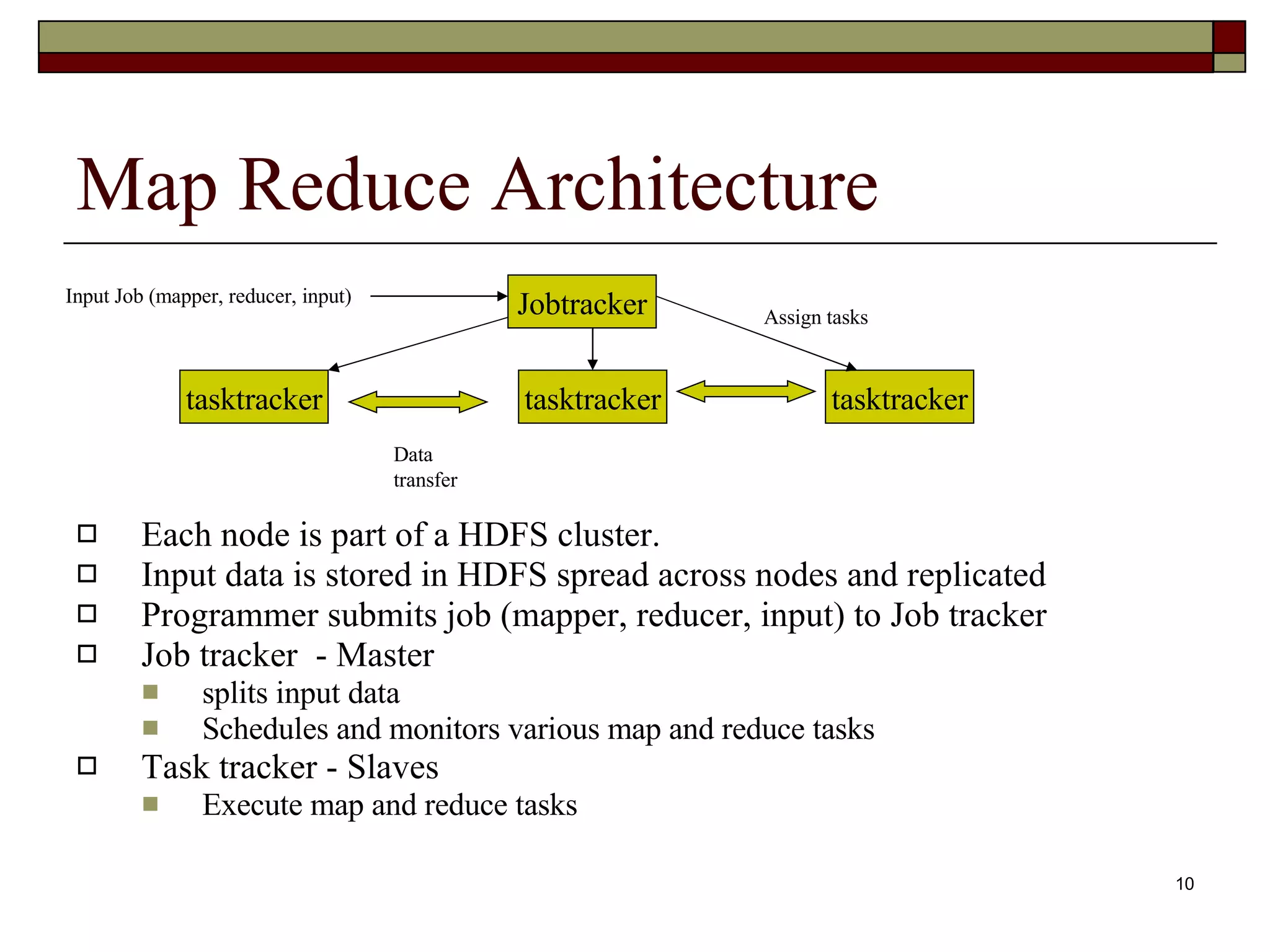
Map Reduce Architecture Each node is part of a HDFS cluster. Input data is stored in HDFS spread across nodes and replicated Programmer submits job (mapper, reducer, input) to Job tracker Job tracker - Master splits input data Schedules and monitors various map and reduce tasks Task tracker - Slaves Execute map and reduce tasks Jobtracker tasktracker tasktracker tasktracker Input Job (mapper, reducer, input) Data transfer Assign tasks
11.
Map Reduce ProgrammingModel Inspired by functional language primitives map f list : applies a given function f to a each element of list and returns a new list map square [1 2 3 4 5] = [1 4 9 16 25] reduce g list : combines elements of list using function g to generate a new value reduce sum [1 2 3 4 5] = [15] Map and reduce do not modify input data. They always create new data A Hadoop Map Reduce job consists of a mapper and a reducer
12.
Map Reduce ProgrammingModel Mapper Records (lines, database rows etc) are input as key/value pairs Mapper outputs one or more intermediate key/value pairs for each input map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter) Reducer After the map phase, all the intermediate values for a given output key are combined together into a list reducer combines those intermediate values into one or more final key/value pairs reduce(K2 key, Iterator<V2> values, OutputCollector<K3, V3> output, Reporter reporter) Input and output key/value types can be different
13.
Word Count MapReduce Job Mapper Input: <key:, offset, value:line of a document> Output: for each word w in input line output<key: w, value:1> Input: (2133, The quick brown fox jumps over the lazy dog.) Output: (the, 1) , (quick, 1), (brown, 1) … (fox,1), (the, 1) Reducer Input: <key: word, value: list<integer>> Output: sum all values from input for the given key input list of values and output <Key:word value:count> Input: (the, [1, 1, 1, 1,1]), (fox, [1, 1, 1]) … Output: (the, 5) (fox, 3)
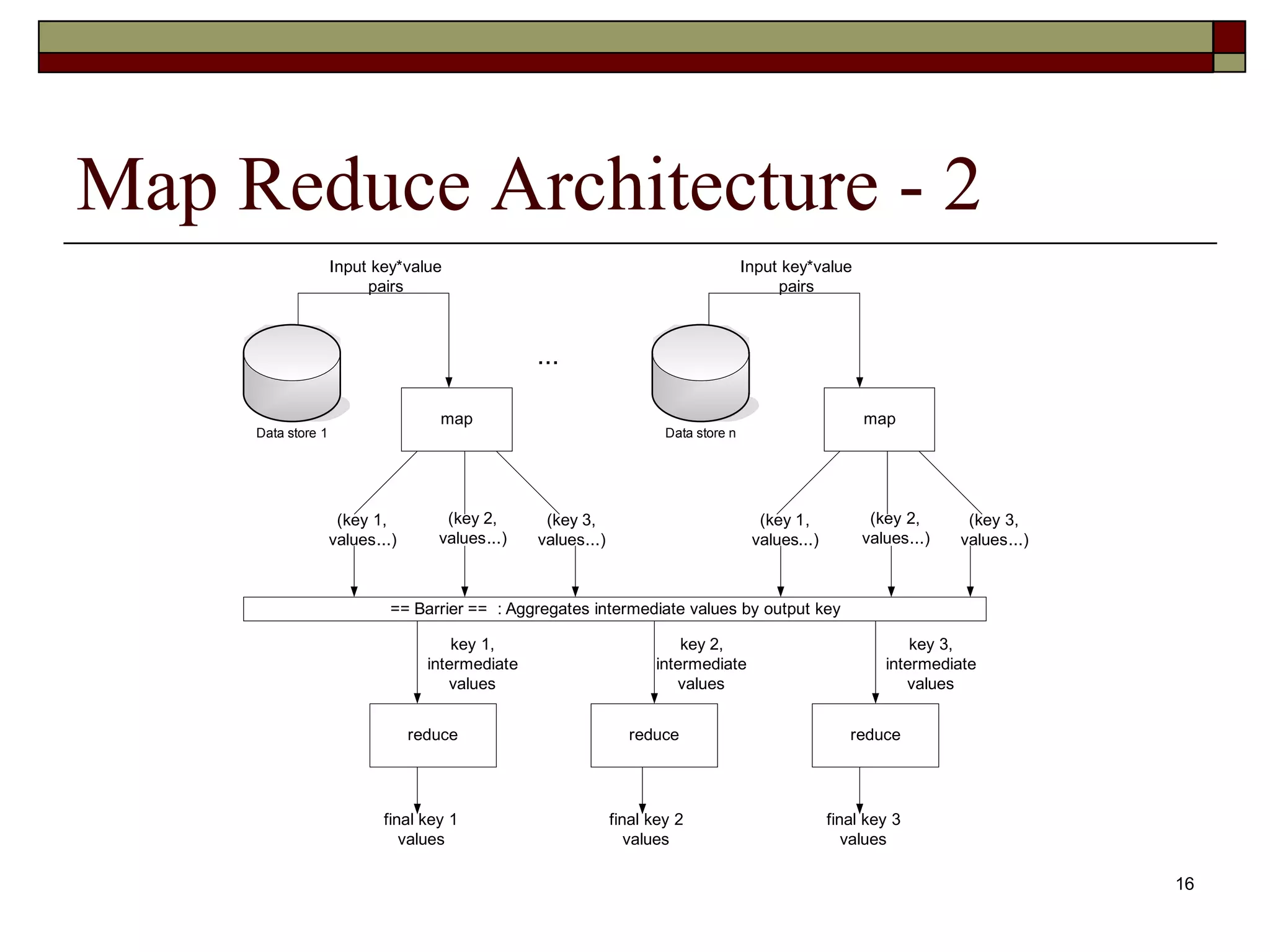
Map Reduce Architecture- 2 Map Phase Map tasks run in parallel – output intermediate key value pairs Shuffle and sort phase Map task output is partitioned by hashing the output key Number of partitions is equal to number of reducers Partitioning ensures all key/value pairs sharing same key belong to same partition The map output partition is sorted by key to group all values for the same key Reduce Phase Each partition is assigned to one reducer. Reducers also run in parallel. No two reducers process the same intermediate key Reducer gets all values for a given key at the same time
Map Reduce Architecture- 2 Job tracker splits input and assigns to various map tasks Schedules and monitors map tasks (heartbeat) On completion, schedules reduce tasks Task tracker Execute map tasks – call mapper for every input record Execute reduce tasks – call reducer for every intermediate key, list of values pair Handle partitioning of map outputs Handle sorting and grouping of reducer input Jobtracker tasktracker tasktracker tasktracker Input Job (mapper, reducer, input) Data transfer Assign tasks
18.
Map Reduce AdvantagesLocality Job tracker divides tasks based on location of data: it tries to schedule map tasks on same machine that has the physical data Parallelism Map tasks run in parallel working different input data splits Reduce tasks run in parallel working on different intermediate keys Reduce tasks wait until all map tasks are finished Fault tolerance Job tracker maintains a heartbeat with task trackers Failures are handled by re-execution If a task tracker node fails then all tasks scheduled on it (completed or incomplete) are re-executed on another node
19.
Conclusion Map Reducegreatly simplifies writing large scale distributed applications Used for building search index at Google, Amazon Widely used for analyzing user logs, data warehousing and analytics Also used for large scale machine learning and data mining applications
20.
References Hadoop. http://hadoop.apache.org/ Jeffrey Dean and Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters. http://labs.google.com/papers/mapreduce.html http://code.google.com/edu/parallel/index.html http://www.youtube.com/watch?v=yjPBkvYh-ss http://www.youtube.com/watch?v=-vD6PUdf3Js S. Ghemawat, H. Gobioff, and S. Leung. The Google File System. http:// labs.google.com/papers/gfs.html







![Map Reduce Programming Model Inspired by functional language primitives map f list : applies a given function f to a each element of list and returns a new list map square [1 2 3 4 5] = [1 4 9 16 25] reduce g list : combines elements of list using function g to generate a new value reduce sum [1 2 3 4 5] = [15] Map and reduce do not modify input data. They always create new data A Hadoop Map Reduce job consists of a mapper and a reducer](https://image.slidesharecdn.com/map-reduce-090514144926-phpapp02/75/Hadoop-Map-Reduce-11-2048.jpg)

![Word Count Map Reduce Job Mapper Input: <key:, offset, value:line of a document> Output: for each word w in input line output<key: w, value:1> Input: (2133, The quick brown fox jumps over the lazy dog.) Output: (the, 1) , (quick, 1), (brown, 1) … (fox,1), (the, 1) Reducer Input: <key: word, value: list<integer>> Output: sum all values from input for the given key input list of values and output <Key:word value:count> Input: (the, [1, 1, 1, 1,1]), (fox, [1, 1, 1]) … Output: (the, 5) (fox, 3)](https://image.slidesharecdn.com/map-reduce-090514144926-phpapp02/75/Hadoop-Map-Reduce-13-2048.jpg)