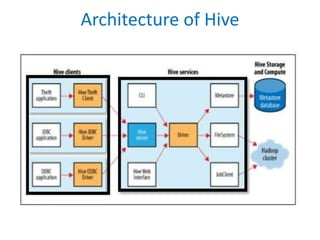
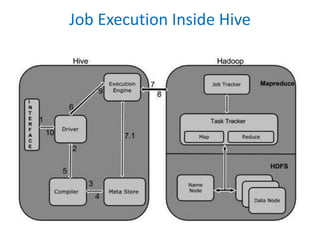
Hive is a data warehouse infrastructure tool used to process large datasets in Hadoop. It allows users to query data using SQL-like queries. Hive resides on HDFS and uses MapReduce to process queries in parallel. It includes a metastore to store metadata about tables and partitions. When a query is executed, Hive's execution engine compiles it into a MapReduce job which is run on a Hadoop cluster. Hive is better suited for large datasets and queries compared to traditional RDBMS which are optimized for transactions.