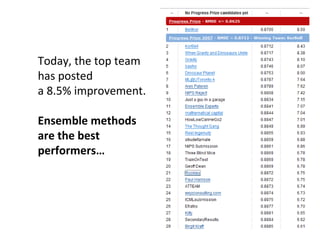
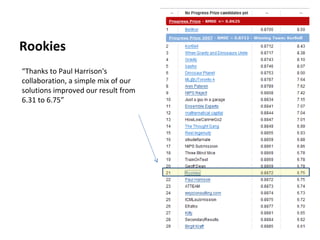
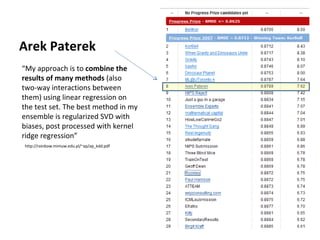
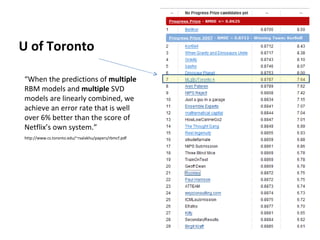
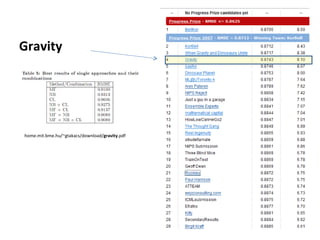
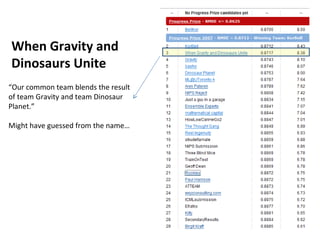
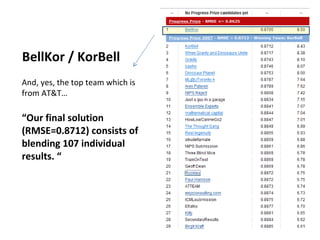
Ensemble learning methods were very successful in the Netflix Prize competition to improve movie recommendations. These methods combine the predictions from multiple models to obtain better accuracy than single models. Popular ensemble techniques included bagging, boosting, and random forests. The winning teams in the Netflix Prize all used ensemble methods that blended the predictions of dozens or hundreds of individual models.

























































![[Women in Data Science Meetup ATX] Decision Trees](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontrees-161118165341-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt2931-thumbnail.jpg?width=640&height=640&fit=bounds)
![[ppt]](https://cdn.slidesharecdn.com/ss_thumbnails/ppt3441-thumbnail.jpg?width=640&height=640&fit=bounds)


























