Download as PDF, PPTX



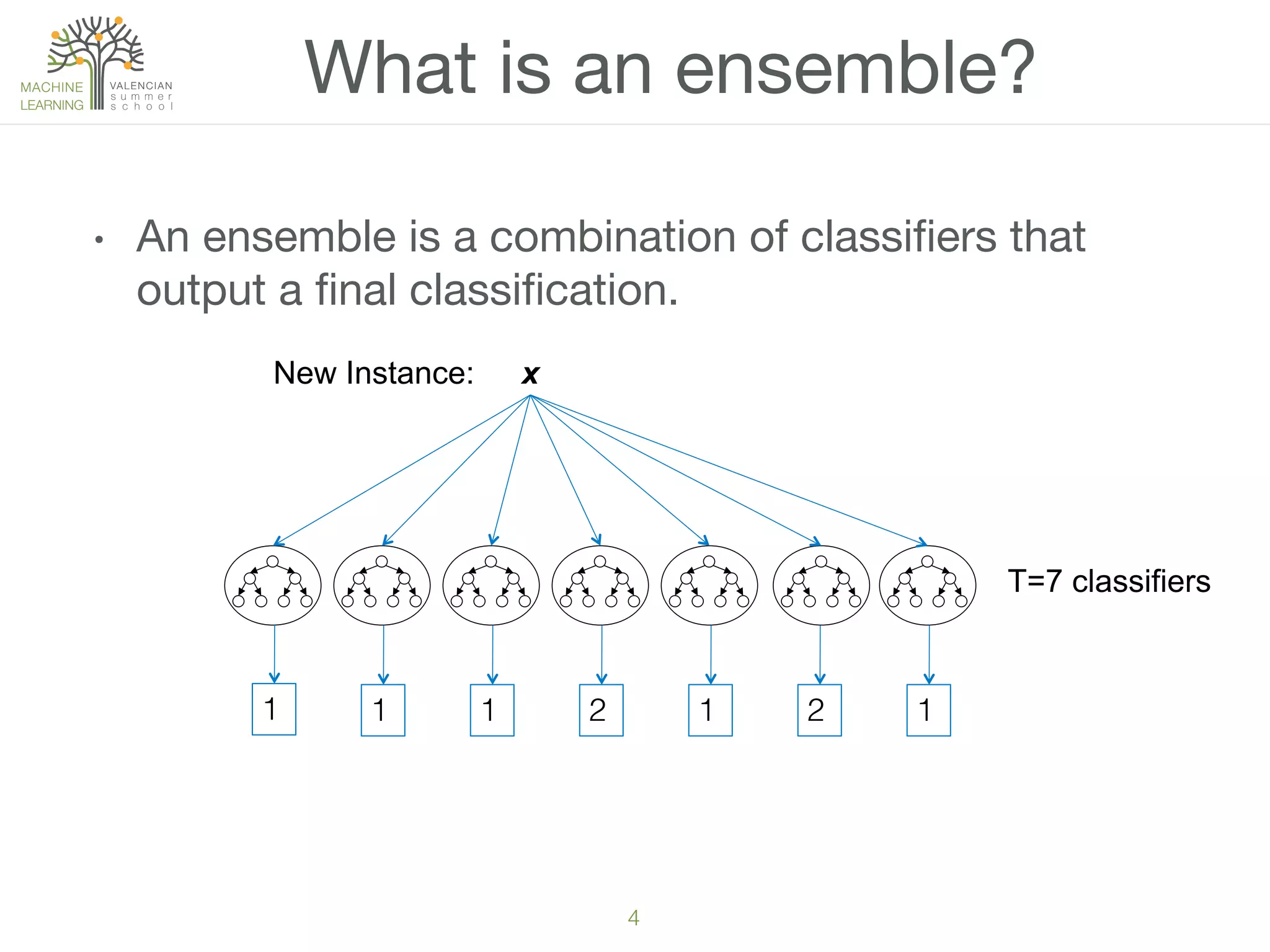





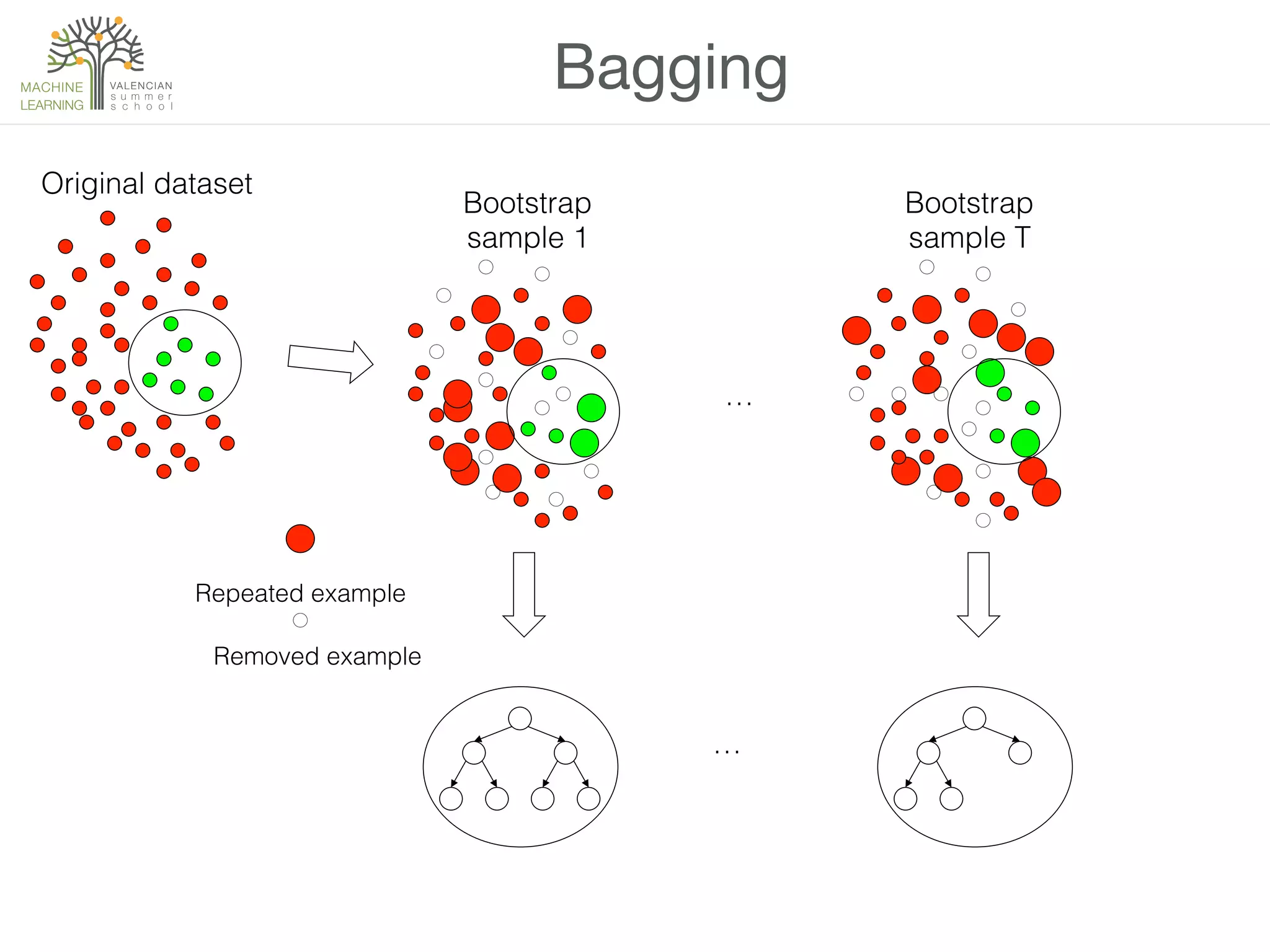


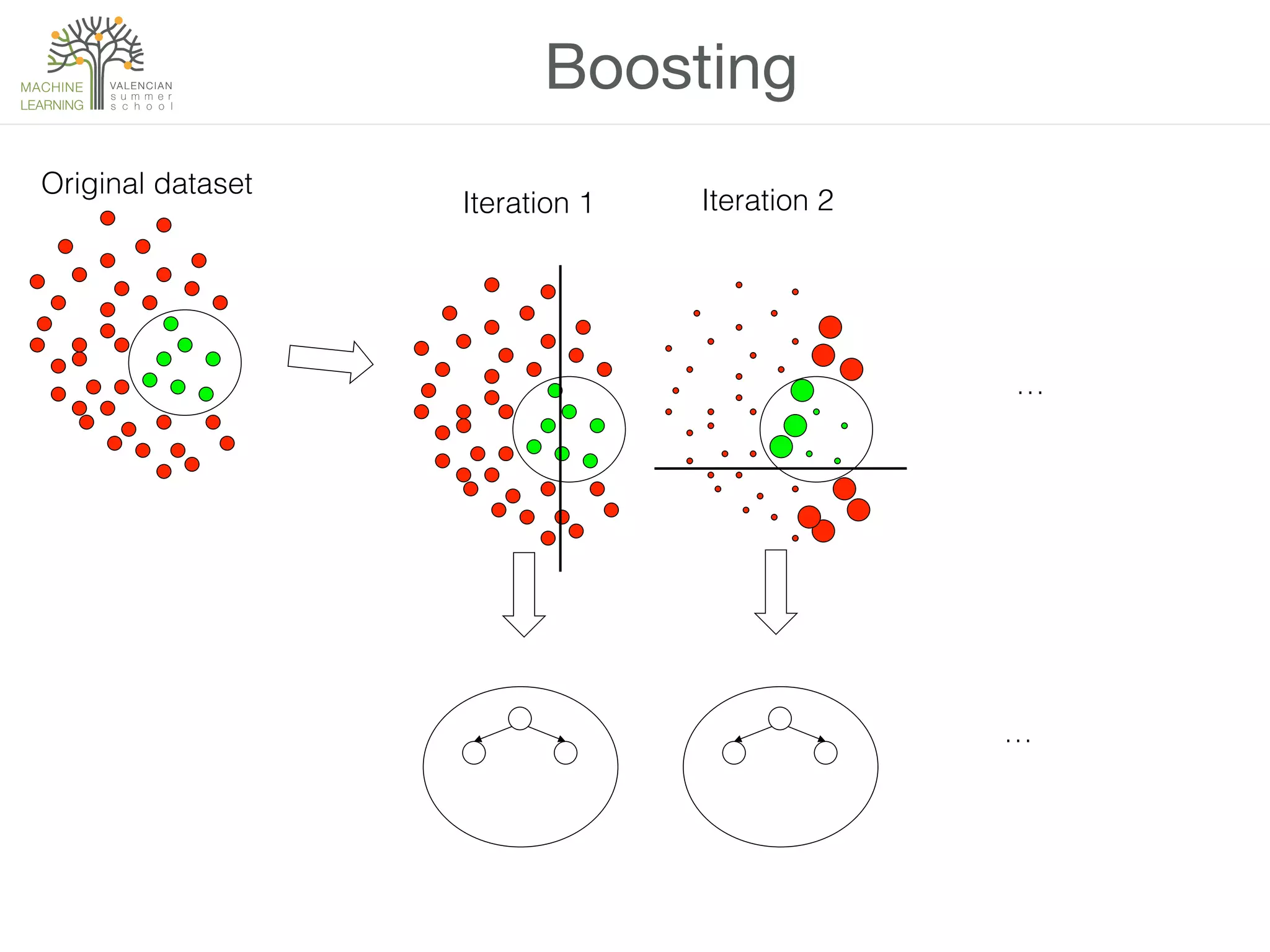





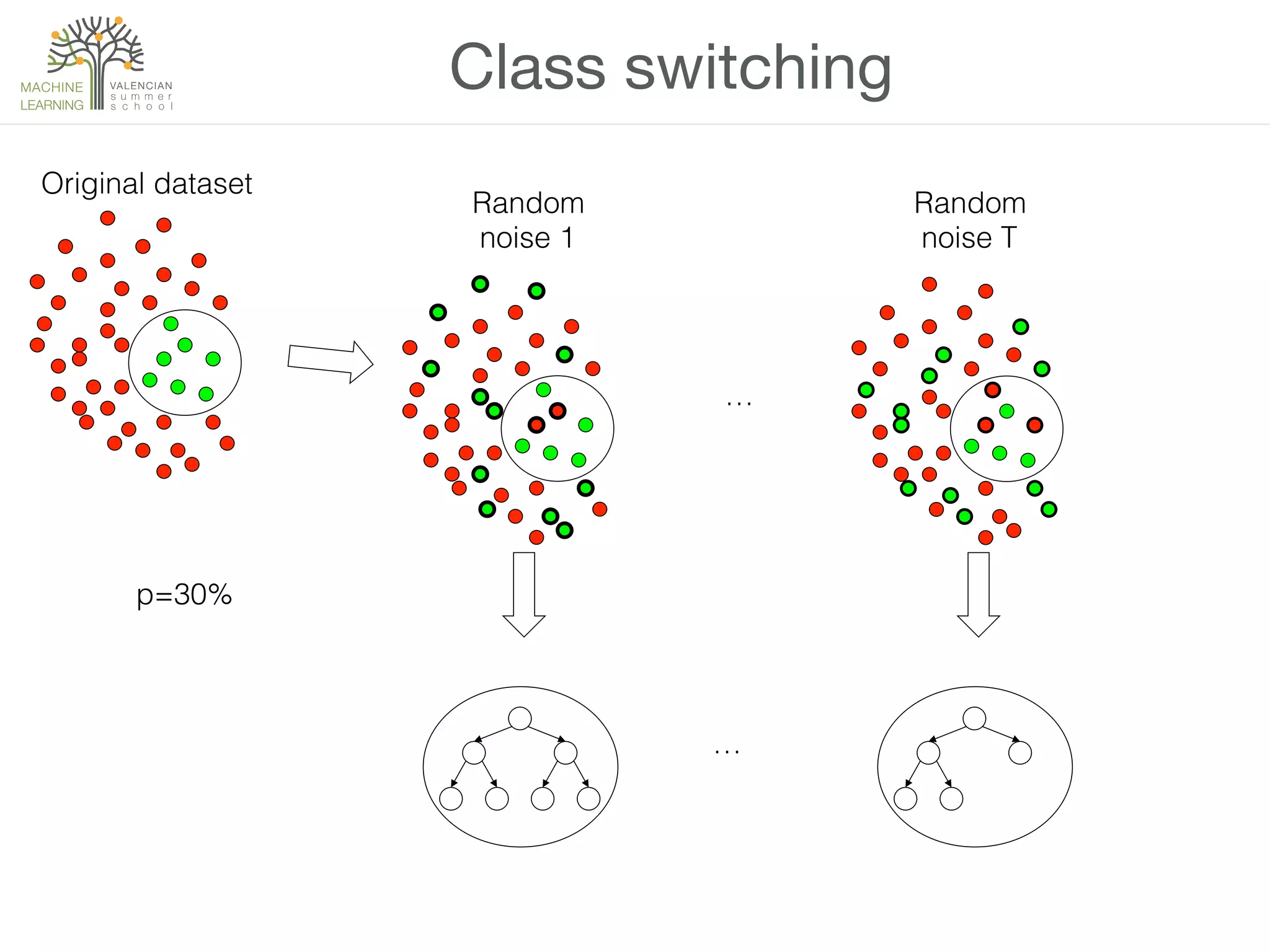
![Example
• 2D example
• Boundary is x1=x2
• x1~U[0, 1] x2~U[0, 1]
• Not an easy task for a normal decision tree
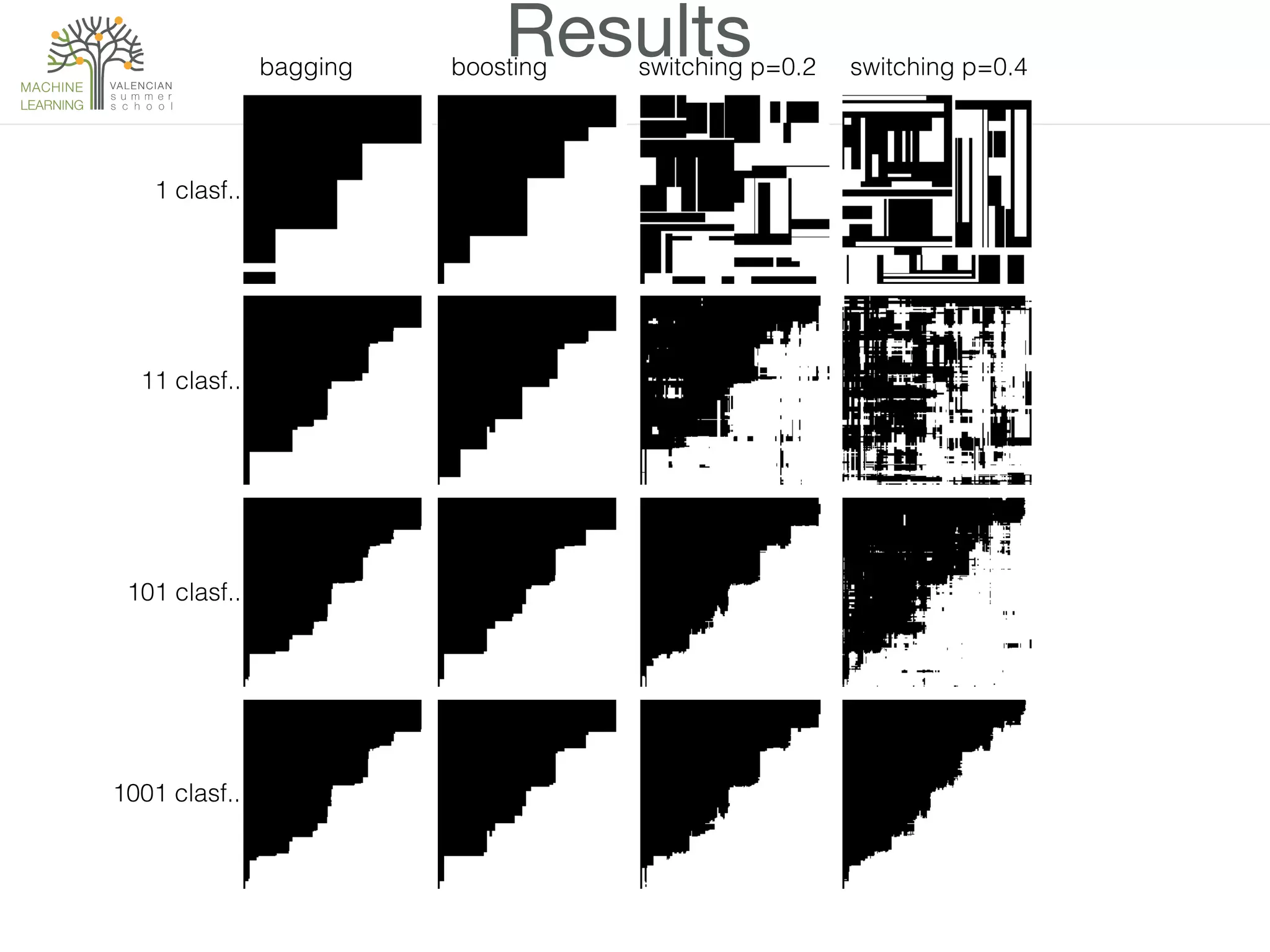
• Let’s try bagging, boosting and class-switching with
p=0.2 y p=0.4
x1
x2
Clase 1
Clase 2
1
1](https://image.slidesharecdn.com/ensemblesofdecisiontrees-150917154434-lva1-app6892/75/L4-Ensembles-of-Decision-Trees-20-2048.jpg)




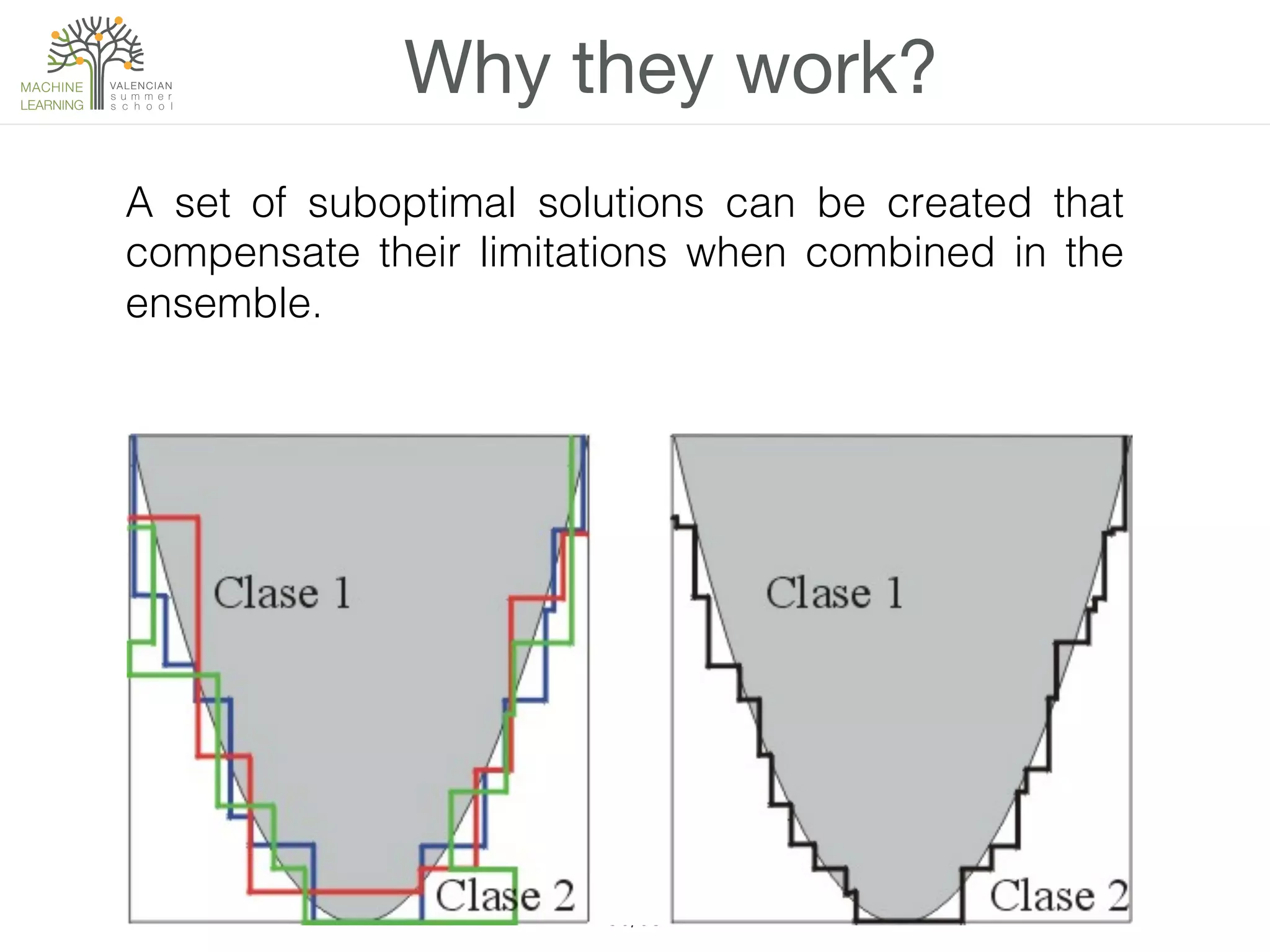
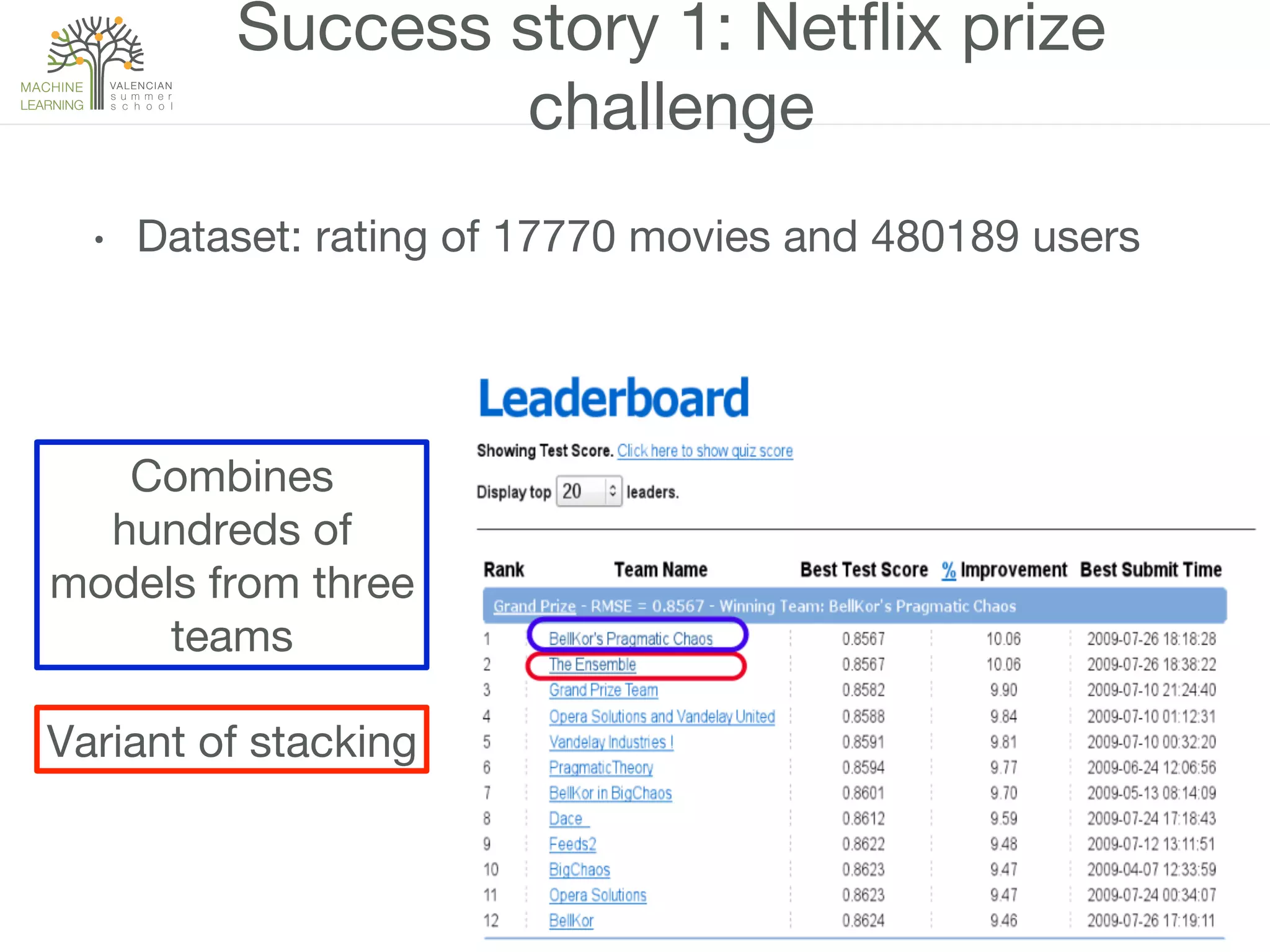





The document discusses ensemble methods in machine learning, which involve combining multiple classifiers to enhance performance. It outlines various techniques for building ensembles, such as bagging, boosting, and random forests, and explains the principles behind their effectiveness, including the Condorcet Jury Theorem. The text also highlights success stories from competitions like the Netflix Prize and KDD Cup, showcasing the practical application of these strategies.















































































