Downloaded 119 times



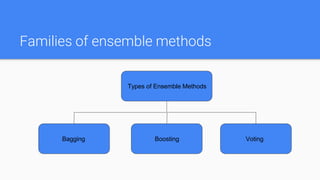


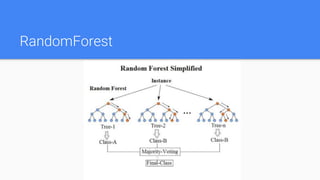


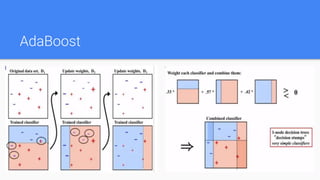
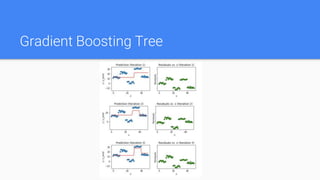






Ensemble methods combine multiple machine learning models to obtain better predictive performance than could be obtained from any of the constituent models alone. The document discusses major families of ensemble methods including bagging, boosting, and voting. It provides examples like random forest, AdaBoost, gradient tree boosting, and XGBoost which build ensembles of decision trees. Ensemble methods help reduce variance and prevent overfitting compared to single models.


















































![[Webinar] Following the Agile Footprint - zekeLabs](https://cdn.slidesharecdn.com/ss_thumbnails/followingtheagilefootprint-webinar-200130092825-thumbnail.jpg?width=640&height=640&fit=bounds)




































