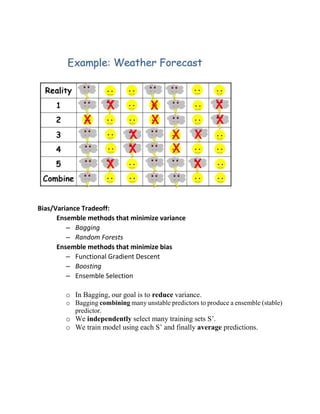
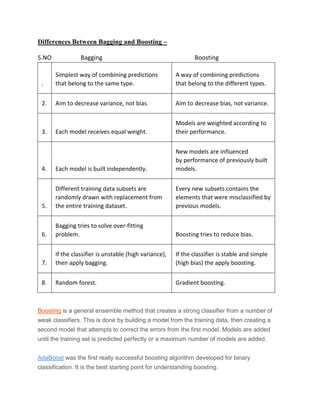
Ensemble methods like bagging, boosting, random forest and AdaBoost combine multiple classifiers to improve performance. Bagging aims to reduce variance by training classifiers on random subsets of data and averaging their predictions. Boosting sequentially trains classifiers to focus on misclassified examples from previous classifiers to reduce bias. Random forest extends bagging by randomly selecting features for training each decision tree. AdaBoost is a boosting algorithm that iteratively adds classifiers and assigns higher weights to misclassified examples.