2
Introduction
• Ensemble methodsin machine learning refer to techniques that combine multiple
models to improve the overall performance of a machine learning system.
• The central idea is that by combining several models, the ensemble can make
more accurate predictions than any individual model on its own.
• There are two primary ways to build ensembles:
1. Bagging (Bootstrap Aggregating)
2. Boosting
4
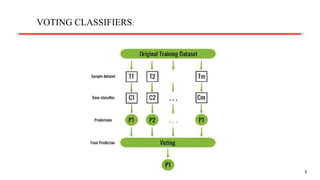
• A VotingClassifier is an ensemble machine learning technique that combines the predictions from
multiple individual classifiers (also known as base classifiers or estimators) to make a final
prediction.
• It’s a type of model averaging approach where each base classifier contributes its prediction, and
the final prediction is determined by a majority vote (for classification) or an average (for
regression).
• The Voting Classifier can be used for both binary and multiclass classification tasks.
INTRODUCTION
5.
5
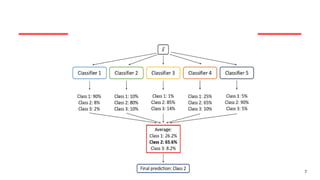
In hard voting,each base classifier’s prediction is treated as a vote, and the final prediction is the
majority vote among the predictions of the individual classifiers. This is commonly used for
classification tasks.
Hard Voting:
6.
6
Soft Voting: Insoft voting, each base classifier’s predicted probabilities for each class are
averaged, and the class with the highest average probability is chosen as the final prediction.
Soft voting often produces better results than hard voting because it takes into account the
confidence levels of the classifiers.
Soft Voting:
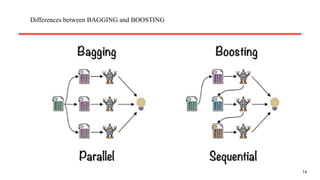
Bagging
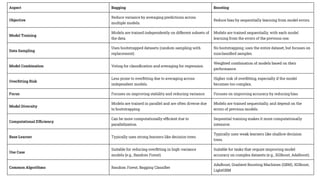
Purpose: Reduce varianceand prevent overfitting
How it works: Bagging trains multiple models independently on different subsets of the training
data. These subsets are created by random sampling with replacement (bootstrap sampling).
After training, the predictions from all models are averaged (for regression) or voted on (for
classification).
Example: Random Forest, which is an ensemble of decision trees.
10
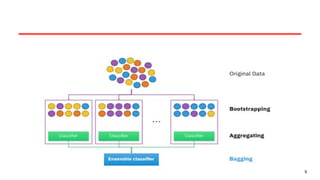
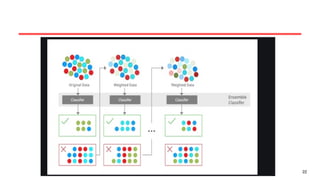
Working of BAGGING
•Bagging works by generating multiple bootstrapped datasets
(random samples drawn with replacement from the original dataset)
and training a separate model on each of these datasets.
• The key idea is that by combining predictions from models trained
on slightly different datasets, the overall variance of the model
decreases, leading to more accurate and reliable predictions.
12
13.
13
Data Sampling: Multiplesubsets of the original dataset are created using bootstrapping (random
sampling with replacement). Each subset may contain duplicate instances but will be different from the
others.
Model Training: A separate model is trained on each bootstrapped subset of the data. These models
are typically of the same type, such as decision trees, but each model sees different data.
Aggregation: For classification tasks, the final prediction is made by taking a majority vote across all
models. For regression tasks, the final prediction is the average of all models’ predictions.
Steps for BAGGING
Boosting
Purpose: Reduce biasand improve the performance of weak models.
How it works: Boosting builds an ensemble sequentially, where each model is trained to correct the errors
made by the previous one. Weights are assigned to instances that are misclassified, and subsequent models
focus more on these challenging instances.
The final prediction is typically made by a weighted vote or average of all models.
Example: AdaBoost, Gradient Boosting, XGBoost, LightGBM, and CatBoost
16
17.
17
• Boosting createsa strong model by combining the predictions of weak learners (models that are
only slightly better than random guessing), improving accuracy and performance over time.
• Boosting focuses on reducing bias rather than variance.
• Boosting works by building models one at a time, with each subsequent model focusing on the
mistakes made by the previous models.
• The key to Boosting’s success lies in its ability to learn from past mistakes and improve
gradually.
18.
18
Model Initialization: Theprocess starts with training a weak learner (usually a simple model like a
decision tree) on the entire dataset.
Weight Adjustment: The algorithm assigns higher weights to the incorrectly classified examples,
emphasizing them in the next round of training.
This ensures that the subsequent model focuses on these difficult examples.
Model Combination: Each model is added to the ensemble, and its prediction is combined with
those of the previous models.
In the case of classification, a weighted majority vote is often used, while for regression, the
models’ predictions are averaged.
Steps for BOOSTING:
19.
19
Boosting typically worksby combining several weak learners.
A weak learner is a model that performs only slightly better than random guessing, but when
combined with others in a Boosting framework, it contributes to creating a strong learner
Key Concept in BOOSTING:
21
AdaBoost (Adaptive Boosting)
AdaBoostis one of the first and most well-known Boosting algorithms.
In AdaBoost, each model is trained sequentially, with greater emphasis placed on the data points that
were misclassified by the previous models.
After training each model, AdaBoost assigns a weight to that model’s prediction, which is based on its
accuracy. The final output is a weighted combination of the predictions from all models.
Use Case: AdaBoost is often used in binary classification tasks such as spam detection or fraud
detection, where the data may contain outliers or noisy samples that the algorithm can learn to handle.
.
Popular BOOOSTING Algorithms :
23
2. Gradient BoostingMachines (GBM)
Gradient Boosting Machines (GBM) is a generalization of AdaBoost that applies gradient descent
to optimize the performance of the model.
Each subsequent model is trained to correct the residual errors (i.e., the difference between the
actual and predicted values) from the previous models, which helps improve accuracy.
Use Case: GBM is widely used in predictive analytics tasks such as predicting credit default risk,
customer churn, and sales forecasting. It’s known for its strong predictive performance in both
classification and regression tasks
24.
24
3. XGBoost (ExtremeGradient Boosting)
XGBoost is an optimized implementation of Gradient Boosting that has gained immense popularity for
its speed and performance.
XGBoost incorporates several additional features, including regularization to prevent overfitting and
parallel processing for faster training.
Use Case: XGBoost is commonly used in data science competitions (like Kaggle) and in real-world
applications such as time-series forecasting, marketing analytics, and recommendation systems.
More info:
https://medium.com/towards-data-science/random-forest-explained-a-visual-guide-with-code-examples-
9f736a6e1b3c
31
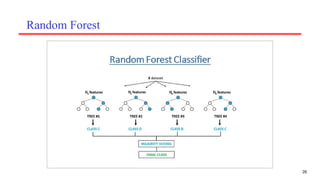
A Random Forestis an ensemble machine learning model that combines multiple decision
trees.
Each tree in the forest is trained on a random sample of the data (bootstrap sampling) and
considers only a random subset of features when making splits (feature randomization).
The forest predicts by majority voting among trees, while for regression tasks, it averages the
predictions.
The model’s strength comes from its “wisdom of crowds” approach — while individual trees
might make errors, the collective decision-making process tends to average out these
mistakes and arrive at more reliable predictions.
More on Random Forest :
33
Bootstrap Sampling: Eachtree gets its own unique training set, created by randomly sampling
from the original data with replacement.
This means some data points may appear multiple times while others aren’t used.
Random Feature Selection: When making a split, each tree only considers a random subset of
features (typically square root of total features).
Growing Trees: Each tree grows using only its bootstrap sample and selected features, making
splits until it reaches a stopping point (like pure groups or minimum sample size).
Final Prediction: All trees vote together for the final prediction. For classification, take the
majority vote of class predictions; for regression, average the predicted values from all trees.
Mechanism of Random Forest:
35
Steps for RANDOMFOREST:
The following steps explain the working Random Forest Algorithm:
Step 1: Select random samples from a given data or training set.
Step 2: This algorithm will construct a decision tree for every training data.
Step 3: Voting will take place by averaging the decision tree.
Step 4: Finally, select the most voted prediction result as the final prediction result.
36.
Decision Fusion Techniques
•Fixed Rule Fusion
– The decision of each classifiers are fused using some fixed rules (eg.
Majority Voting, Max(max/ min/ mean) etc)
• Trained Rule Fusion
– A Classifier is trained using the decisions of all base classifiers to take a
decision.
36
37.
Fixed Rule FusionTechniques
1. Majority Voting: This rule takes the output from multiple classifiers or sources and selects the class that
receives the most votes. It’s often used in classification tasks where the output is categorical.
2. Sum Rule: Each classifier provides a score for each class, and these scores are summed for each class
across classifiers. The class with the highest cumulative score is selected. This method is effective when
classifier outputs are probabilistic scores or likelihoods.
3. Product Rule: This rule multiplies the output scores for each class from each classifier. It emphasizes
agreement among classifiers, as a low score from any classifier reduces the final product significantly. It’s
suitable when classifiers have high confidence on certain outputs.
4. Max Rule: This rule takes the maximum score among classifiers for each class and selects the class with
the highest maximum score. It’s useful when some classifiers are very confident about certain classes, and
this confidence should be prioritized.
5. Min Rule: This rule takes the minimum score from each classifier for each class and selects the class with
the highest minimum score. It’s less common and works well when the classifiers should all be confident
for a decision to be considered strong.
6. Median Rule: The median score across classifiers is computed for each class, and the class with the highest
median score is chosen. This is robust to outliers as it ignores extreme values from individual classifiers.
37
38.
Trained Rule FusionTechniques
• Trained rule fusion techniques are advanced methods used to combine the
outputs from multiple classifiers or sources in a way that is learned from data
rather than using fixed, predefined rules.
• These techniques typically involve training a meta-model (such as a machine
learning model) to learn how to best combine the predictions or outputs from
individual classifiers based on the input data or classifier performance.
• The goal is to improve the overall decision-making process by leveraging the
strengths of each source or classifier.
• Example: Bagging, Boosting, Stacking, Voting
38
Stacking
• Purpose: Combinedifferent types of models to leverage their diverse strengths.
• How it works: Stacking involves training multiple base models (which may be different types of
models) and then using another model, called a "meta-model" or "stacker", to learn how to best
combine the predictions of the base models. The meta-model takes the predictions of the base
models as inputs to produce the final prediction.
• Example: Combining decision trees, SVM, and neural networks as base models, with a logistic
regression or another model as the meta-model
40
42
The primary ideaof stacking is to feed the predictions of numerous base models into a higher-
level model known as the meta-model or blender, which then combines them to get the final
forecast.
Preparing the Data: The first step is to prepare the data for modeling. This entails identifying the
relevant features, cleaning the data, and dividing it into training and validation sets.
Model Selection: The following step is to choose the base models that will be used in the stacking
ensemble.
A broad selection of models is typically chosen to guarantee that they produce different types of
errors and complement one another.
Working of STACKING:
43.
43
Training the BaseModels: After selecting the base models, they are trained on the training set. To
ensure diversity, each model is trained using a different algorithm or set of hyperparameters.
Predictions on the Validation Set: Once the base models have been trained, they are used to make
predictions on the validation set.
Developing a Meta Model: The next stage is to develop a meta-model, also known as a meta learner,
which will take the predictions of the underlying models as input and make the final prediction. Any
algorithm, such as linear regression, logistic regression, or even a neural network, can be used to create
this model.
Training the Meta Model: The meta-model is then trained using the predictions given by the base
models on the validation set. The base models’ predictions serve as features for the meta-model.
44.
44
Making Test SetPredictions: Finally, the meta-model is used to produce test set predictions. The
basic models’ predictions on the test set are fed into the meta-model, which then makes the final
prediction.
Model Evaluation: The final stage is to assess the stacking ensemble’s performance. This is
accomplished by comparing the stacking ensemble’s predictions to the actual values on the test set
using evaluation measures such as accuracy, precision, recall, F1 score, and so on.
https://medium.com/@brijesh_soni/stacking-to-improve-model-performance-a-comprehensive-guide-
on-ensemble-learning-in-python-9ed53c93ce28
45.
Resources
• Click onthe following to know the implementation details of ensembling
techniques:
https://www.nb-data.com/p/comparing-model-ensembling-bagging
45