Downloaded 955 times




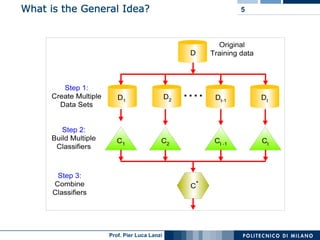

















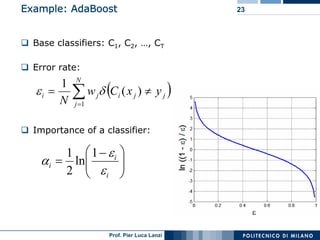

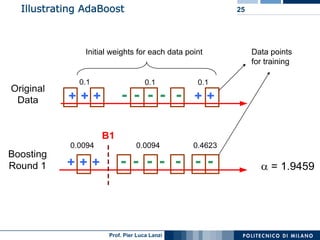
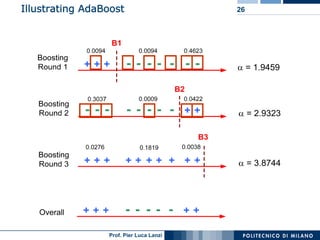












This document discusses ensemble machine learning methods. It introduces classifiers ensembles and describes three common ensemble methods: bagging, boosting, and random forests. For each method, it explains the basic idea, how the method works, advantages and disadvantages. Bagging constructs multiple classifiers from bootstrap samples of the training data and aggregates their predictions through voting. Boosting builds classifiers sequentially by focusing on misclassified examples. Random forests create decision trees with random subsets of features and samples. Ensembles can improve performance over single classifiers by reducing variance.























































































