[DL輪読会]Adaptive Gradient Methods with Dynamic Bound of Learning Rate
1.
DEEP LEARNING JP
[DLPapers]
Adaptive Gradient Methods with Dynamic Bound of
Learning Rate
Koichiro Tamura, Matsuo Lab
http://deeplearning.jp/
2.
PAPER INFORMATION
• AdaptiveGradient Methods with Dynamic Bound of Learning
Rate
– Liangchen Luo, Yuanhao Xiong, Yan Liu, Xu Sun
– Submitted on 26 Feb 2019 (arxiv)
– https://arxiv.org/abs/1902.09843
– ICLR2019 under review
• Metareview: The paper was found to be well-written and conveys interesting idea.
However the AC notices a large body of clarifications that were provided to the
reviewers (regarding the theory, experiments, and setting in general) that need to
be well addressed in the paper.
• Confidence: 5: The area chair is absolutely certain
• Recommendation: Accept (Poster)
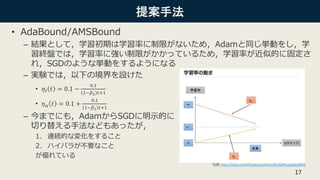
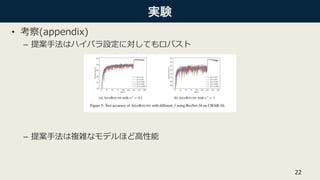
• 最適化手法
– Adamの収束の速さとSGDの汎化性能のいいとこ取り
• GitHub: https://github.com/Luolc/AdaBound 2
![DEEP LEARNING JP
[DL Papers]
Adaptive Gradient Methods with Dynamic Bound of
Learning Rate
Koichiro Tamura, Matsuo Lab
http://deeplearning.jp/](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-1-320.jpg)

![イントロ
• 近年の機械学習の発展に伴って,最適化手法も研究が盛んに行われてきた
– SGD: シンプルで汎化性能が高い手法だが,収束速度と離散的なデータに対する性能が課題
– Adaptiveな手法(adagrad, RMSProp, adamなど): 収束速度が向上したが,汎化性能が課題
– SGDの欠点を補うために研究・提案されたAdaptiveな最適化手法であるが,未知データに対
する性能に対してあまりパフォームしていないなどとの問題提起[Wilsom et al., 2017]など
もあり,最近のDeep Learningに関連する手法では結局SGDが用いられている
– AMSGrad[Reddi et al., 2018]はLong Term Memoryを持つことによって,既存の指数平均
的なアルゴリズムでは取り扱っていなかった学習データの持つ情報量のバイアスに対処し,ま
た小さな学習率を適用することで高性能であることを示した.しかし,Adamとそこまで性能
が変わらないとの指摘も[Keskar&Socher, 2017; Chen et al.,2018]
4
今回は,実験的にAdam/AMSGradなどの最適化手法が収束しない
原因を実証的に特定し,それに対して新しい手法を提案する](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-4-320.jpg)
![既存の最適化手法の整理と課題
• 既存手法を汎用的な表現で整理すると以下のようになる
5
AMSGrad [Reddi et al., 2018]より引用](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-5-320.jpg)

![既存の最適化手法の整理と課題
• 既存手法を汎用的な表現で整理すると以下のようになる
7
AMSGrad [Reddi et al., 2018]より引用
普通のSGD .スケーリングはなし(固定)](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-7-320.jpg)
![既存の最適化手法の整理と課題
• 既存手法を汎用的な表現で整理すると以下のようになる
8
AMSGrad [Reddi et al., 2018]より引用
SGD に対して,Momentumを追加.
過去の最適化のトレンドを反映させるこ
とで局所最適を飛ばして大局的最適へ
スケーリングはなし(固定)
引用: https://postd.cc/optimizing-gradient-descent/](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-8-320.jpg)
![既存の最適化手法の整理と課題
• 既存手法を汎用的な表現で整理すると以下のようになる
9
AMSGrad [Reddi et al., 2018]より引用
SGD に対して,Regretの上界を制限すること
によって局所解に陥りにくくした手法.
Learning rateが適応的に減少していく](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-9-320.jpg)
![既存の最適化手法の整理と課題
• 既存手法を汎用的な表現で整理すると以下のようになる
10
AMSGrad [Reddi et al., 2018]より引用
ADAGrad に対して,より最近の勾配に大き
な重みを置くことで,急激な曲率に対して
適応できるようにした](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-10-320.jpg)
![既存の最適化手法の整理と課題
• 既存手法を汎用的な表現で整理すると以下のようになる
11
AMSGrad [Reddi et al., 2018]より引用
RMSPROPにさらにMomentumを組み合わせ,
収束スピードを向上.
パラメタ毎に適切なスケールで重みが更新
されていくようにした](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-11-320.jpg)
![既存の最適化手法の整理と課題
• AMSGradの登場
– 実際のデータには,情報量のばらつきがある
– Adamなどの問題点として,そうした最適化
に対して大きく貢献する勾配の重みが即座に
減少してしまう
– =>Long Term Memoryの導入
• しかし、AMSGradはAdamとそれほど性能差がないことが報告され
ることも[Keskar&Socher, 2017; Chen et al.,2018]
12
引用: https://www.slideshare.net/harmonylab/20180611-102102340
特定期間の最大値をと
ることで,有効だった
重みを反映](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-12-320.jpg)






![みんなの口コミ
• 実際に使ってみた人の声を集めてみた
– AdaBoundを試してみた
• https://blog.knjcode.com/adabound-memo/
• [内容]ラーメン二郎のデータセットでAdaBoound/AMSBoundを試してみた
• [結果]good: 転移学習においてもほぼ論文の主張どおりの結果 (AdaBound と
AMSBound の速い収束、高い汎化性能)を確認できた
– tweet@fukkaa さん
• https://twitter.com/fukkaa1225/status/1103587061095792640
• [内容]文書分類
• [結果]not good
23](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-23-320.jpg)
![みんなの口コミ
• 実際に使ってみた人の声を集めてみた
– tweet@coz_a_1980 さん
• https://twitter.com/coz_a_1980/status/1107039197565612033
• [内容]CNN
• [結果]final lrの調整は必要だが,good
24](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-24-320.jpg)
![みんなの口コミ
• 実際に使ってみた人の声を集めてみた
– tweet@hrs1985 さん
• https://twitter.com/hrs1985/status/1103996044369584129
• [内容]: 強化学習?
• [結果]: good
25](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-25-320.jpg)
![みんなの口コミ
• 実際に使ってみた人の声を集めてみた
– tweet@Reiji_Hatsu
• https://twitter.com/Reiji_Hatsu/status/1102920991754280961
• [内容]: 強化学習
• [結果]: good (seedなどによってやや不安定)
26](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-26-320.jpg)
![みんなの口コミ
• 実際に使ってみた人の声を集めてみた
– tweet@moopan さん
• https://twitter.com/mooopan/status/1104080839422369792
• [内容]強化学習
• [結果]not good
27](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-27-320.jpg)


• [Optimizer : 深層学習における勾配法について](https://qiita.com/tokkuman/items/1944c00415d129ca0ee9)
• [最適化アルゴリズムを評価するベンチマーク関数まとめ](https://qiita.com/tomitomi3/items/d4318bf7afbc1c835dda)
• [On the Convergence of Adam and Beyond](https://www.slideshare.net/harmonylab/20180611-102102340)
• [Optimizer : 深層学習における勾配法について](https://qiita.com/tokkuman/items/1944c00415d129ca0ee9)
• [[最新論文] 新しい最適化手法誕生! AdaBound & AMSBound](https://qiita.com/Phoeboooo/items/f610affdcaaae0a28f34)
• [AdaBoundを試してみた](https://blog.knjcode.com/adabound-memo/)
29](https://image.slidesharecdn.com/adabound-190325085133/85/DL-Adaptive-Gradient-Methods-with-Dynamic-Bound-of-Learning-Rate-29-320.jpg)






![[DL輪読会]AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning](https://cdn.slidesharecdn.com/ss_thumbnails/dl1211-191213002847-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Disentangling by Factorising](https://cdn.slidesharecdn.com/ss_thumbnails/20180720disentanglingbyfactorising-180720000930-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Recent Advances in Autoencoder-Based Representation Learning](https://cdn.slidesharecdn.com/ss_thumbnails/20190119dljournalclubweb-190401063633-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)





































