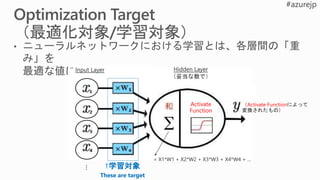
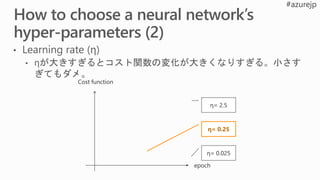
L1
regularization
L2
regularization
Cost function(C0) にL1正規化項を追加
※λ:正規化パラメータ
wが大きい:L1 shrinks the weight much less than L2 does.
wが小さい: L1 shrinks the weight much more than L2 does.
Cost function(C0) にL2正規化項を追加
※λ:正規化パラメータ
→The effect of regularization is to make it so the network
prefer to learn small weight
Wight decay it makes weight smaller lower complexity reduce overfitting
引用例:http://sig.tsg.ne.jp/ml2015/ml/2015/06/29/techniques-of-learning.html
Is there adeer in
the image?
Where is the deer
in the image?
Where exactly is the
deer? What pixels?
Which images are similar
to the query image?
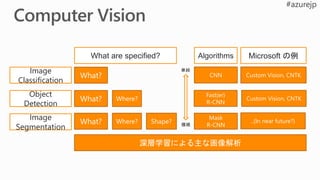
Image
Classification
Object
detection
Image
segmentation
Image
Similarity
Similar
image
Query
imageYes
64.
Jabil, Printed CircuitBoard
Defect Detection
Schneider Electric, Circuit
Breaker Defect Detection
Shell, Counting Grey Stock of
Pipes for Inventory
Management
Land O’Lakes, Sustainability
Farming, Map Labeling
Brillio - Which images are
similar to the query image?
Image
Classification
Object
detection
Image
segmentation
Image
Similarity
Darlie, Retail Store Inspection



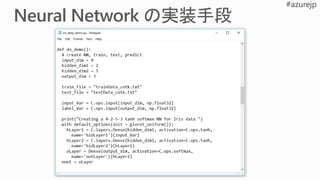



























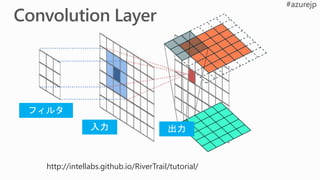

![my_model = Sequential ([
Dense(64, activation=relu),
Dense(64, activation=relu),
Dense(10, activation=softmax)
])
with default_options(activation=relu):
my_model = Sequential([
For(range(2), lambda: Dense(64)),
Dense(10, activation=softmax)
])
net = Dense(64, activation=relu)(net)
net = Dense(64, activation=relu)(net)
net = Dense(10, activation=softmax)(net)
普通に実装
Sequential()
For()
活性化関数にReLU を
使う 2つの隠れ層と
Softmaxを使う出力層
を実装した3つの例](https://image.slidesharecdn.com/r6fa1p3truazv6jwtdw7-signature-693ba3e44e1482f197cdb156e01e464b4a53cc63925736ed9c64c75737dd4460-poli-180918212955/85/Deep-Learning-2-Deep-Learning-81-320.jpg)







![def create_model(model_uri, num_classes, input_features, feature_node_name, last_hidden_name, new_prediction_node_name='pred
base_model = C.load_model(download_from_uri(model_uri))
feature_node = C.logging.find_by_name(base_model, feature_node_name)
last_node = C.logging.find_by_name(base_model, last_hidden_name)
cloned_layers = C.combine([last_node.owner]).clone(C.CloneMethod.clone,
{feature_node: C.placeholder(name='features')})
feat_norm = input_features - C.Constant(114)
cloned_out = cloned_layers(feat_norm)
return C.layers.Dense(num_classes, activation=None, name=new_prediction_node_name) (cloned_out)](https://image.slidesharecdn.com/r6fa1p3truazv6jwtdw7-signature-693ba3e44e1482f197cdb156e01e464b4a53cc63925736ed9c64c75737dd4460-poli-180918212955/85/Deep-Learning-2-Deep-Learning-91-320.jpg)













































![[第2版]Python機械学習プログラミング 第13章](https://cdn.slidesharecdn.com/ss_thumbnails/13-190318023252-thumbnail.jpg?width=640&height=640&fit=bounds)

























