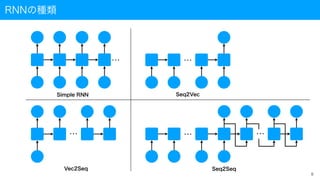
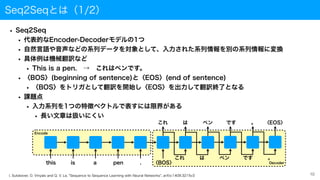
Seq2Seqとは(1/2)
• Seq2Seq
• 代表的なEncoder-Decoderモデルの1つ
•自然言語や音声などの系列データを対象として、入力された系列情報を別の系列情報に変換
• 具体例は機械翻訳など
• This is a pen. → これはペンです。
• 〈BOS〉(beginning of sentence)と〈EOS〉(end of sentence)
• 〈BOS〉をトリガとして翻訳を開始し〈EOS〉を出力して翻訳終了となる
• 課題点
• 入力系列を1つの特徴ベクトルで表すには限界がある
• 長い文章は扱いにくい
I. Sutskever, O. Vinyals and Q. V. Le, "Sequence to Sequence Learning with Neural Networks", arXiv:1409.3215v3
Decoder
Encode
this is a pen . 〈BOS〉
これ は ペン です 。 〈EOS〉
これ は ペン です 。
10
11.
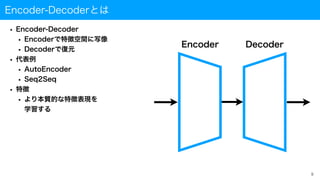
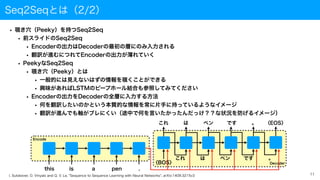
Seq2Seqとは(2/2)
• 覗き穴(Peeky)を持つSeq2Seq
• 前スライドのSeq2Seq
•Encoderの出力はDecoderの最初の層にのみ入力される
• 翻訳が進むにつれてEncoderの出力が薄れていく
• PeekyなSeq2Seq
• 覗き穴(Peeky)とは
• 一般的には見えないはずの情報を覗くことができる
• 興味があればLSTMのピープホール結合も参照してみてください
• Encoderの出力をDecoderの全層に入力する方法
• 何を翻訳したいのかという本質的な情報を常に片手に持っているようなイメージ
• 翻訳が進んでも軸がブレにくい(途中で何を言いたかったんだっけ??な状況を防げるイメージ)
I. Sutskever, O. Vinyals and Q. V. Le, "Sequence to Sequence Learning with Neural Networks", arXiv:1409.3215v3
Encode
this is a pen .
11
Decoder
これ は ペン です 。
これ は ペン です 。 〈EOS〉
〈BOS〉
12.
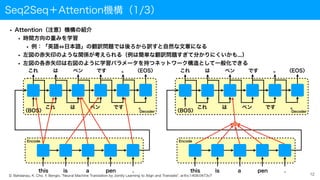
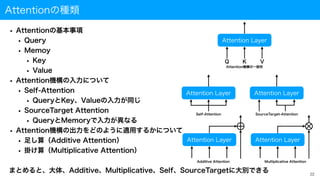
Seq2Seq+Attention機構(1/3)
• Attention(注意)機構の紹介
• 時間方向の重みを学習
•例:「英語 日本語」の翻訳問題では後ろから訳すと自然な文章になる
• 左図の赤矢印のような関係が考えられる(例は簡単な翻訳問題すぎて分かりにくいかも...)
• 左図の各赤矢印は右図のように学習パラメータを持つネットワーク構造として一般化できる
12
Decoder
Encode
this is a pen .
これ は ペン です 。 〈EOS〉
これ は ペン です 。
〈BOS〉
+
Decoder
Encode
this is a pen .
これ は ペン です 。 〈EOS〉
これ は ペン です 。
〈BOS〉
D. Bahdanau, K. Cho, Y. Bengio, "Neural Machine Translation by Jointly Learning to Align and Translate", arXiv:1409.0473v7
13.
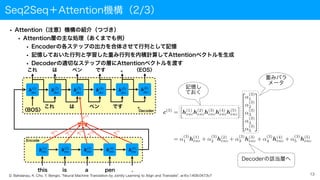
Seq2Seq+Attention機構(2/3)
13
D. Bahdanau, K.Cho, Y. Bengio, "Neural Machine Translation by Jointly Learning to Align and Translate", arXiv:1409.0473v7
• Attention(注意)機構の紹介(つづき)
• Attention層の主な処理(あくまでも例)
• Encoderの各ステップの出力を合体させて行列として記憶
• 記憶しておいた行列と学習した重み行列を内積計算してAttentionベクトルを生成
• Decoderの適切なステップの層にAttentionベクトルを渡す
+
Decoder
Encode
this is a pen .
これ は ペン です 。 〈EOS〉
これ は ペン です 。
〈BOS〉
α(3)
1
α(3)
2
α(3)
3 α(3)
4
α(3)
5
h(1)
enc h(2)
enc h(3)
enc h(4)
enc h(5)
enc
記憶し
ておく
重みパラ
メータ
Decoderの該当層へ
h(1)
dec
h(2)
dec
h(3)
dec
h(4)
dec
h(5)
dec
h(6)
dec
c(3)
14.
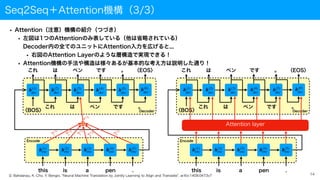
Seq2Seq+Attention機構(3/3)
14
Decoder
Encode
this is apen .
これ は ペン です 。 〈EOS〉
これ は ペン です 。
〈BOS〉
+
Decoder
Encode
this is a pen .
これ は ペン です 。 〈EOS〉
これ は ペン です 。
〈BOS〉
Attention layer
D. Bahdanau, K. Cho, Y. Bengio, "Neural Machine Translation by Jointly Learning to Align and Translate", arXiv:1409.0473v7
• Attention(注意)機構の紹介(つづき)
• 左図は1つのAttentionのみ表している(他は省略されている)
Decoder内の全てのユニットにAttention入力を広げると...
• 右図のAttention Layerのような層構造で実現できる!
• Attention機構の手法や構造は様々あるが基本的な考え方は説明した通り!
h(1)
enc h(2)
enc h(3)
enc h(4)
enc h(5)
enc
h(1)
enc h(2)
enc h(3)
enc h(4)
enc h(5)
enc
α(3)
1
α(3)
2
α(3)
3 α(3)
4
α(3)
5
h(1)
dec
h(2)
dec
h(3)
dec
h(4)
dec
h(5)
dec
h(6)
dec
h(1)
dec
h(2)
dec
h(3)
dec
h(4)
dec
h(5)
dec
h(6)
dec
c(3)
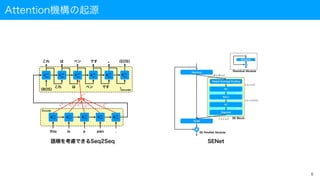
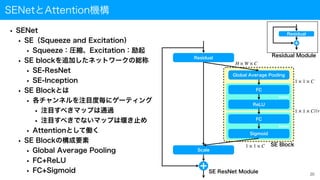
SENetとAttention機構
• SENet
• SE(Squeezeand Excitation)
• Squeeze:圧縮、Excitation:励起
• SE blockを追加したネットワークの総称
• SE-ResNet
• SE-Inception
• SE Blockとは
• 各チャンネルを注目度毎にゲーティング
• 注目すべきマップは通過
• 注目すべきでないマップは堰き止め
• Attentionとして働く
• SE Blockの構成要素
• Global Average Pooling
• FC+ReLU
• FC+Sigmoid 20
Residual
Scale
Global Average Pooling
FC
ReLU
FC
Sigmoid
Dense
Dense
Residual
H × W × C
1 × 1 × C
1 × 1 × C//r
1 × 1 × C
SE ResNet Module
SE Block
Residual Module
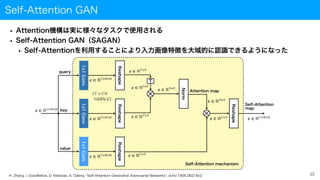
Self-Attention GAN
• Attention機構は実に様々なタスクで使用される
•Self-Attention GAN(SAGAN)
• Self-Attentionを利用することにより入力画像特徴を大域的に認識できるようになった
23
H. Zhang, I. Goodfellow, D. Metaxas, A. Odena, "Self-Attention Generative Adversarial Networks", arXiv:1805.08318v2
24.
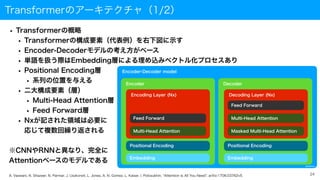
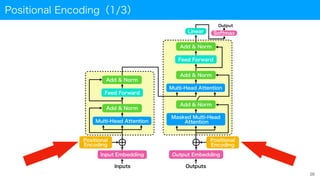
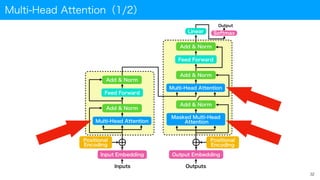
Transformerのアーキテクチャ(1/2)
Encoder-Decoder model
@AGIRobo
Encoder
Embedding
Positional Encoding
EncodingLayer (Nx)
Feed Forward
Multi-Head Attention
Decoder
Embedding
Positional Encoding
Decoding Layer (Nx)
Feed Forward
Masked Multi-Head Attention
Multi-Head Attention
24
• Transformerの概略
• Transformerの構成要素(代表例)を右下図に示す
• Encoder-Decoderモデルの考え方がベース
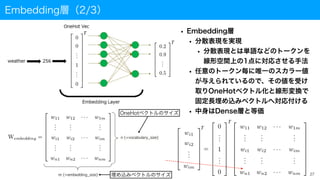
• 単語を扱う際はEmbedding層による埋め込みベクトル化プロセスあり
• Positional Encoding層
• 系列の位置を与える
• 二大構成要素(層)
• Multi-Head Attention層
• Feed Forward層
• Nxが記された領域は必要に
応じて複数回繰り返される
※CNNやRNNと異なり、完全に
Attentionベースのモデルである
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, "Attention Is All You Need", arXiv:1706.03762v5.
25.
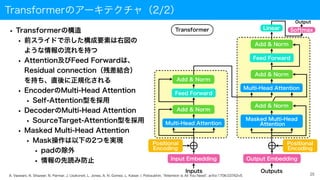
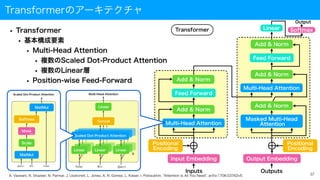
Transformerのアーキテクチャ(2/2)
• Transformerの構造
• 前スライドで示した構成要素は右図の
ような情報の流れを持つ
•Attention及びFeed Forwardは、
Residual connection(残差結合)
を持ち、直後に正規化される
• EncoderのMulti-Head Attention
• Self-Attention型を採用
• DecoderのMulti-Head Attention
• SourceTarget-Attention型を採用
• Masked Multi-Head Attention
• Mask操作は以下の2つを実現
• padの除外
• 情報の先読み防止
25
Transformer
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
Multi-Head Attention
Feed Forward
Masked Multi-Head
Attention
Add & Norm
Add & Norm
Add & Norm
Input Embedding
Positional
Encoding
Output Embedding
Positional
Encoding
Inputs Outputs
Linear Softmax
Output
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, "Attention Is All You Need", arXiv:1706.03762v5.
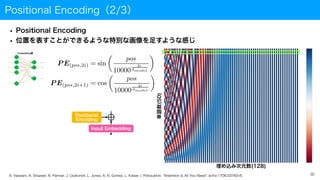
Positional Encoding(2/3)
• PositionalEncoding
• 位置を表すことができるような特別な画像を足すような感じ
30
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, "Attention Is All You Need", arXiv:1706.03762v5.
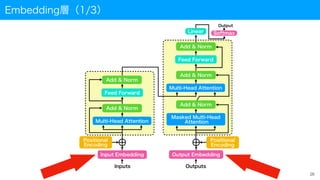
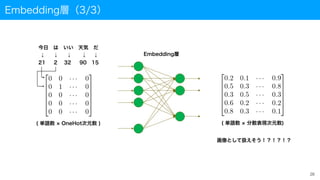
Embedding層
埋め込み次元数(128)
単語数(50)
31.
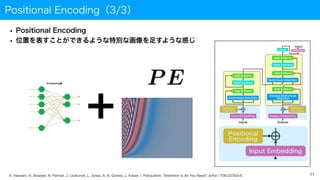
Positional Encoding(3/3)
• PositionalEncoding
• 位置を表すことができるような特別な画像を足すような感じ
31
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, "Attention Is All You Need", arXiv:1706.03762v5.
Embedding層
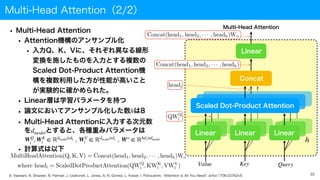
Multi-Head Attention(2/2)
• Multi-HeadAttention
• Attention機構のアンサンブル化
• 入力Q、K、Vに、それぞれ異なる線形
変換を施したものを入力とする複数の
Scaled Dot-Product Attention機
構を複数利用した方が性能が高いこと
が実験的に確かめられた。
• Linear層は学習パラメータを持つ
• 論文においてアンサンブル化した数 は8
• Multi-Head Attentionに入力する次元数
を とすると、各種重みパラメータは
• 計算式は以下
h
dmodel
33
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, "Attention Is All You Need", arXiv:1706.03762v5.
Multi-Head Attention
h
Value Key Query
Scaled Dot-Product Attention
Linear
Concat
Linear Linear
Linear
WQ
i
, WK
i ∈ ℝdmodel×dk , WV
i ∈ ℝdmodel×dv , Wo
∈ ℝhdv×dmodel
34.
Scaled Dot-Product Attention
34
ScaledDot-Product Attention
Query Key Value
MatMul
Scale
Softmax
MatMul
Mask
(opt.)
QKT
dk
QKT
softmax
(
QKT
dk )
softmax
(
QKT
dk )
V
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, "Attention Is All You Need", arXiv:1706.03762v5.
• Scaled Dot-Product Attention(スケール化内積注意)
• [一言で表すと]
QueryとKeyの類似度からValueのどの値に注意を
向けるべきかを計算する
• Multiplicative(Dot-Product) Attentionの一種
• 学習パラメータを持たない
• Scaleを実施する理由
• QueryとKeyの次元数を とする。 が大きいと、
内積が大きくなる可能性が高い。softmax関数の出力は、
softmaxへの全体的な入力が大きいほど0か1に近づく。
出力が0に近づくと学習時に誤差が伝播しにくくなる。
それを回避するために、 でスケーリングする。
• 計算式は以下
dk dk
dk
Transformerのアーキテクチャ
• Transformer
• 基本構成要素
•Multi-Head Attention
• 複数のScaled Dot-Product Attention
• 複数のLinear層
• Position-wise Feed-Forward
37
Transformer
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
Multi-Head Attention
Feed Forward
Masked Multi-Head
Attention
Add & Norm
Add & Norm
Add & Norm
Input Embedding
Positional
Encoding
Output Embedding
Positional
Encoding
Inputs Outputs
Linear Softmax
Output
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, "Attention Is All You Need", arXiv:1706.03762v5.
38.
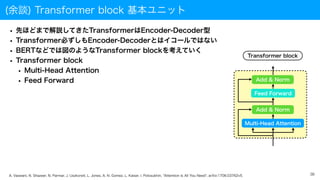
(余談) Transformer block基本ユニット
• 先ほどまで解説してきたTransformerはEncoder-Decoder型
• Transformer必ずしもEncoder-Decoderとはイコールではない
• BERTなどでは図のようなTransformer blockを考えていく
• Transformer block
• Multi-Head Attention
• Feed Forward
38
Transformer block
Multi-Head Attention
Add & Norm
Feed Forward
Add & Norm
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, "Attention Is All You Need", arXiv:1706.03762v5.


![認知科学と注意(Attention)(2/2)
• 注意とは
• 特定の対象に感覚や意識を集中させること
• 不必要な情報は排除し必要な情報を選択することで、知的資源の効果的配分を実現
• 人間の知的活動の本質かも
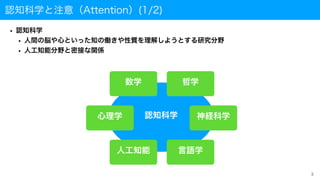
• 代表的な注意
• 視覚的注意
• (例)街を歩いていて看板に書かれた文字を読む
• 聴覚的注意
• (例)カクテルパーティ効果
• 騒がしい環境下でも会話が可能
• 会話相手の声を選択
4
[ウィケンズの人間の情報処理モデルを参考]](https://image.slidesharecdn.com/attention-210920063734/85/Attention-Transformer-4-320.jpg)


![ILSVRCの優勝モデル
19
year model top-5 error
rates [%]
2010 28.2
2011 SIFT+FVs 25.8
2012 AlexNet 16.4
2013 ZFNet 11.7
2014 GoogLeNet 6.7
↳ VGGNet 7.3
2015 ResNet 3.6
2016 ensemble 3.0
2017 SENet 2.3
※ILSVRC頻出用語
・top-1 error rates:正解ラベルが1番目候補として示されない割合
・top-5 error rates:正解ラベルが5番目候補までに含まれない割合
・SOTA:state of the artの略。”最も高精度”の意で使われる。](https://image.slidesharecdn.com/attention-210920063734/85/Attention-Transformer-19-320.jpg)

![Scaled Dot-Product Attention
34
Scaled Dot-Product Attention
Query Key Value
MatMul
Scale
Softmax
MatMul
Mask
(opt.)
QKT
dk
QKT
softmax
(
QKT
dk )
softmax
(
QKT
dk )
V
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, "Attention Is All You Need", arXiv:1706.03762v5.
• Scaled Dot-Product Attention(スケール化内積注意)
• [一言で表すと]
QueryとKeyの類似度からValueのどの値に注意を
向けるべきかを計算する
• Multiplicative(Dot-Product) Attentionの一種
• 学習パラメータを持たない
• Scaleを実施する理由
• QueryとKeyの次元数を とする。 が大きいと、
内積が大きくなる可能性が高い。softmax関数の出力は、
softmaxへの全体的な入力が大きいほど0か1に近づく。
出力が0に近づくと学習時に誤差が伝播しにくくなる。
それを回避するために、 でスケーリングする。
• 計算式は以下
dk dk
dk](https://image.slidesharecdn.com/attention-210920063734/85/Attention-Transformer-34-320.jpg)








![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Attention Is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks170714-170714005330-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Pervasive Attention: 2D Convolutional Neural Networks for Sequence-to-...](https://cdn.slidesharecdn.com/ss_thumbnails/20180907pervasiveattention2dconvolutionalneuralnetworksforsequence-to-sequenceprediction-180907000649-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] Residual Attention Network for Image Classification](https://cdn.slidesharecdn.com/ss_thumbnails/residualattentionnetworkforimageclassification-170907072057-thumbnail.jpg?width=640&height=640&fit=bounds)

