Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
KM
Uploaded by
Koji Matsuda
3,008 views
Unified Expectation Maximization
Read more
2
Save
Share
Embed
Embed presentation
Download
Downloaded 13 times
1
/ 23
2
/ 23
3
/ 23
4
/ 23
5
/ 23
6
/ 23
7
/ 23
8
/ 23
9
/ 23
10
/ 23
11
/ 23
12
/ 23
13
/ 23
14
/ 23
15
/ 23
16
/ 23
17
/ 23
18
/ 23
19
/ 23
20
/ 23
21
/ 23
22
/ 23
23
/ 23
More Related Content
PDF
Nips yomikai 1226
by
Yo Ehara
PDF
ベイズ推論とシミュレーション法の基礎
by
Tomoshige Nakamura
PPTX
Neural word embedding as implicit matrix factorization の論文紹介
by
Masanao Ochi
PDF
Probabilistic Graphical Models 輪読会 Chapter5
by
Daiki Shimada
PDF
Sparse models
by
Daisuke Yoneoka
PDF
ML: Sparse regression CH.13
by
Daisuke Yoneoka
PDF
2015 08 survey
by
marujirou
PPTX
連結と閉包
by
政孝 鍋島
Nips yomikai 1226
by
Yo Ehara
ベイズ推論とシミュレーション法の基礎
by
Tomoshige Nakamura
Neural word embedding as implicit matrix factorization の論文紹介
by
Masanao Ochi
Probabilistic Graphical Models 輪読会 Chapter5
by
Daiki Shimada
Sparse models
by
Daisuke Yoneoka
ML: Sparse regression CH.13
by
Daisuke Yoneoka
2015 08 survey
by
marujirou
連結と閉包
by
政孝 鍋島
Similar to Unified Expectation Maximization
PPTX
充足可能性問題のいろいろ
by
Hiroshi Yamashita
PDF
幾何を使った統計のはなし
by
Toru Imai
PDF
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
PDF
Prml 10 1
by
正志 坪坂
PDF
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PDF
PFI Christmas seminar 2009
by
Preferred Networks
PPTX
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PDF
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
by
Toshiyuki Shimono
PDF
FOBOS
by
Hidekazu Oiwa
PDF
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PDF
PRML_titech 8.1 - 8.2
by
Takafumi Sakakibara
PDF
Data assim r
by
Xiangze
PDF
Oshasta em
by
Naotaka Yamada
PDF
深層学習と確率プログラミングを融合したEdwardについて
by
ryosuke-kojima
PDF
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PDF
Datamining 4th adaboost
by
sesejun
PDF
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
PPTX
モンテカルロ法と情報量
by
Shohei Miyashita
PPTX
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PDF
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
充足可能性問題のいろいろ
by
Hiroshi Yamashita
幾何を使った統計のはなし
by
Toru Imai
行列およびテンソルデータに対する機械学習(数理助教の会 2011/11/28)
by
ryotat
Prml 10 1
by
正志 坪坂
統計的学習理論チュートリアル: 基礎から応用まで (Ibis2012)
by
Taiji Suzuki
PFI Christmas seminar 2009
by
Preferred Networks
Prml 1.3~1.6 ver3
by
Toshihiko Iio
PRML輪講用資料10章(パターン認識と機械学習,近似推論法)
by
Toshiyuki Shimono
FOBOS
by
Hidekazu Oiwa
統計的因果推論 勉強用 isseing333
by
Issei Kurahashi
PRML_titech 8.1 - 8.2
by
Takafumi Sakakibara
Data assim r
by
Xiangze
Oshasta em
by
Naotaka Yamada
深層学習と確率プログラミングを融合したEdwardについて
by
ryosuke-kojima
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
Datamining 4th adaboost
by
sesejun
SGD+α: 確率的勾配降下法の現在と未来
by
Hidekazu Oiwa
モンテカルロ法と情報量
by
Shohei Miyashita
MASTERING ATARI WITH DISCRETE WORLD MODELS (DreamerV2)
by
harmonylab
PRML復々習レーン#7 前回までのあらすじ
by
sleepy_yoshi
More from Koji Matsuda
PPTX
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
PDF
研究室内PRML勉強会 11章2-4節
by
Koji Matsuda
PDF
Information-Theoretic Metric Learning
by
Koji Matsuda
PDF
研究室内PRML勉強会 8章1節
by
Koji Matsuda
PDF
「今日から使い切る」 ための GNU Parallel による並列処理入門
by
Koji Matsuda
PDF
Align, Disambiguate and Walk : A Unified Approach forMeasuring Semantic Simil...
by
Koji Matsuda
PDF
いまさら聞けない “モデル” の話 @DSIRNLP#5
by
Koji Matsuda
PDF
場所参照表現タグ付きコーパスの 構築と評価
by
Koji Matsuda
PPTX
知識を紡ぐための言語処理と、 そのための言語資源
by
Koji Matsuda
PDF
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010)
by
Koji Matsuda
PDF
A Machine Learning Framework for Programming by Example
by
Koji Matsuda
PPTX
Vanishing Component Analysis
by
Koji Matsuda
PDF
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
PDF
Language Models as Representations for Weakly-Supervised NLP Tasks (CoNLL2011)
by
Koji Matsuda
PDF
Joint Modeling of a Matrix with Associated Text via Latent Binary Features
by
Koji Matsuda
PPTX
KB + Text => Great KB な論文を多読してみた
by
Koji Matsuda
PPTX
Large-Scale Information Extraction from Textual Definitions through Deep Syn...
by
Koji Matsuda
PPTX
Reading Wikipedia to Answer Open-Domain Questions (ACL2017) and more...
by
Koji Matsuda
PPTX
Entity linking meets Word Sense Disambiguation: a unified approach(TACL 2014)の紹介
by
Koji Matsuda
Approximate Scalable Bounded Space Sketch for Large Data NLP
by
Koji Matsuda
研究室内PRML勉強会 11章2-4節
by
Koji Matsuda
Information-Theoretic Metric Learning
by
Koji Matsuda
研究室内PRML勉強会 8章1節
by
Koji Matsuda
「今日から使い切る」 ための GNU Parallel による並列処理入門
by
Koji Matsuda
Align, Disambiguate and Walk : A Unified Approach forMeasuring Semantic Simil...
by
Koji Matsuda
いまさら聞けない “モデル” の話 @DSIRNLP#5
by
Koji Matsuda
場所参照表現タグ付きコーパスの 構築と評価
by
Koji Matsuda
知識を紡ぐための言語処理と、 そのための言語資源
by
Koji Matsuda
Word Sense Induction & Disambiguaon Using Hierarchical Random Graphs (EMNLP2010)
by
Koji Matsuda
A Machine Learning Framework for Programming by Example
by
Koji Matsuda
Vanishing Component Analysis
by
Koji Matsuda
Practical recommendations for gradient-based training of deep architectures
by
Koji Matsuda
Language Models as Representations for Weakly-Supervised NLP Tasks (CoNLL2011)
by
Koji Matsuda
Joint Modeling of a Matrix with Associated Text via Latent Binary Features
by
Koji Matsuda
KB + Text => Great KB な論文を多読してみた
by
Koji Matsuda
Large-Scale Information Extraction from Textual Definitions through Deep Syn...
by
Koji Matsuda
Reading Wikipedia to Answer Open-Domain Questions (ACL2017) and more...
by
Koji Matsuda
Entity linking meets Word Sense Disambiguation: a unified approach(TACL 2014)の紹介
by
Koji Matsuda
Unified Expectation Maximization
1.
Unified Expecta.on Maximiza.on
R. Samdani, M. Chang ,Dan Roth (NAACL’12) すずかけ論文読み会 2013 / 03 / 23 紹介者:matsuda 1
2.
Unified EM Algorithm •
[Samdani+ NAACL’12] – EMによる(Semi-‐supervised)学習の統一的な解釈 • この論文のアイデアは非常にシンプル – 構造に「制約」が無い場合は簡単(アニーリング EMの拡張) – 構造に「制約」が入る場合はややこしい • Prior Work 主にこっちのお話をします – Posterior Reguraliza.on [Ganchev+ JMLR’10] – Constraint Driven Learning [Chang+ ACL’07] 2
3.
構造に制約が無いEM • ふつうの EM
アルゴリズム – 色々な定式化があるが,ここでは発表者スライド に合わせて • E-‐step: 現在のパラメータのもとで,尤もらしい argminqKL(qt(y),P (y|x;wt)) ラベルyの分布qを求める • M-‐step: 求めた分布qの期待値が最大 argmaxw Eqlog P(x, y; w) になるようにパラメータwを更新 3
4.
自然言語処理における
具体的な事前知識の例 • 文書分類 – ある割合の文書はあるクラスであるということが分かっている • POS-‐tagging – 各文に最低一つは動詞,名詞が含まれている – ある語が多数のPOSに割り当てられることは少ない • Rela.on Informa.on Extrac.on – ある種類のEn.tyと他の種類のEn.tyの間には,特定の Rela.onしか成り立たない • LOCATION – PERSON間 なら LIVE-‐IN とか. • (SMTにおける)アラインメント – L1 -‐> L2の対応は, L2 -‐> L1の対応と等しい – L1のある語がL2の多数の語と対応することは少ない 多数のラベルつきデータがあれば,そこから自然に学習が可能そう しかし,ラベルつきデータが利用できない場合でも,事前知識をモデルに取り込みたい 4
5.
EM学習において,
どのように事前知識を入れるか • 制約をどのように表現するか • 制約を用いた学習はどうすれば良いか Posterior Regulariza.on COnstraint Driven Learning [Ganchev et al, 2010] [Chang et al, 2007] 制約を「ソフト」に入れる 制約を「ハード」に入れる 「制約を満たす分布」とのKLダイバージェンス最小化 ビームサーチ + hard EM (今回は紹介しません) Unified EM 一つパラメータを導入することで,一般的な解釈 ラグランジュ緩和に基づく効率的なE-‐stepの計算 5
6.
Posterior Regulariza.on • ふつう
“Regulariza.on” というと – パラメータw(とかθ)に対する事前知識の導入 正則化と言われてすぐ思いつく例 正則化項(L2ノルムなど) w = argmin " L(x, y, w) + ! R(w) ! w • しかし,出力(の構造)に事前知識を入れたい ・・・どうやって?? – Posterior Regulariza.on – Constraint Driven Learing – Generalized Expecta.on Criteria 6
7.
PRにおける制約の表現(1/2) • 制約の「素性表現」を導入
– 文書分類の例) ある文書が”poli.cs” ! (x, y) = ! 1 if y is "politics" # " # 0 $ otherwise • 素性の「期待値」を取る – 文書分類の例) 25%の文書が”poli.cs” E p! [" (x, y)] = b 期待値を取るのは「モデル全体として」 のソフトな制約を入れるため b = 0.25 (期待値をとらないハードな手法もある) bは一般にはベクトル表現になる(多数 の制約を入れるため) 7
8.
PRにおける制約の表現(2/2) • 制約を満たす確率分布の集合を定義
– 先ほどの例なら,”poli.cs”が25%であるような分 布の集合(一般には,不等式制約で書く) • 分布の集合とのKLダイバージェンスを定義 制約を満たす分布qの中で,最 • 最大化する目的関数 もモデルの分布と近いものとの KLダイバージェンス モデルの尤度を 制約分布とのKLダイバージェンスを最小に 最大に 8
9.
PRにおけるEM学習(1/2) • Jensenの不等式で尤度の下限をおさえる q, θを交互に最大化
9
10.
PRにおけるEM学習(2/2) • 先ほどの制約を導入した目的関数 つまり, q∈Qの範囲でE-‐stepの探索を行えばよい
10
11.
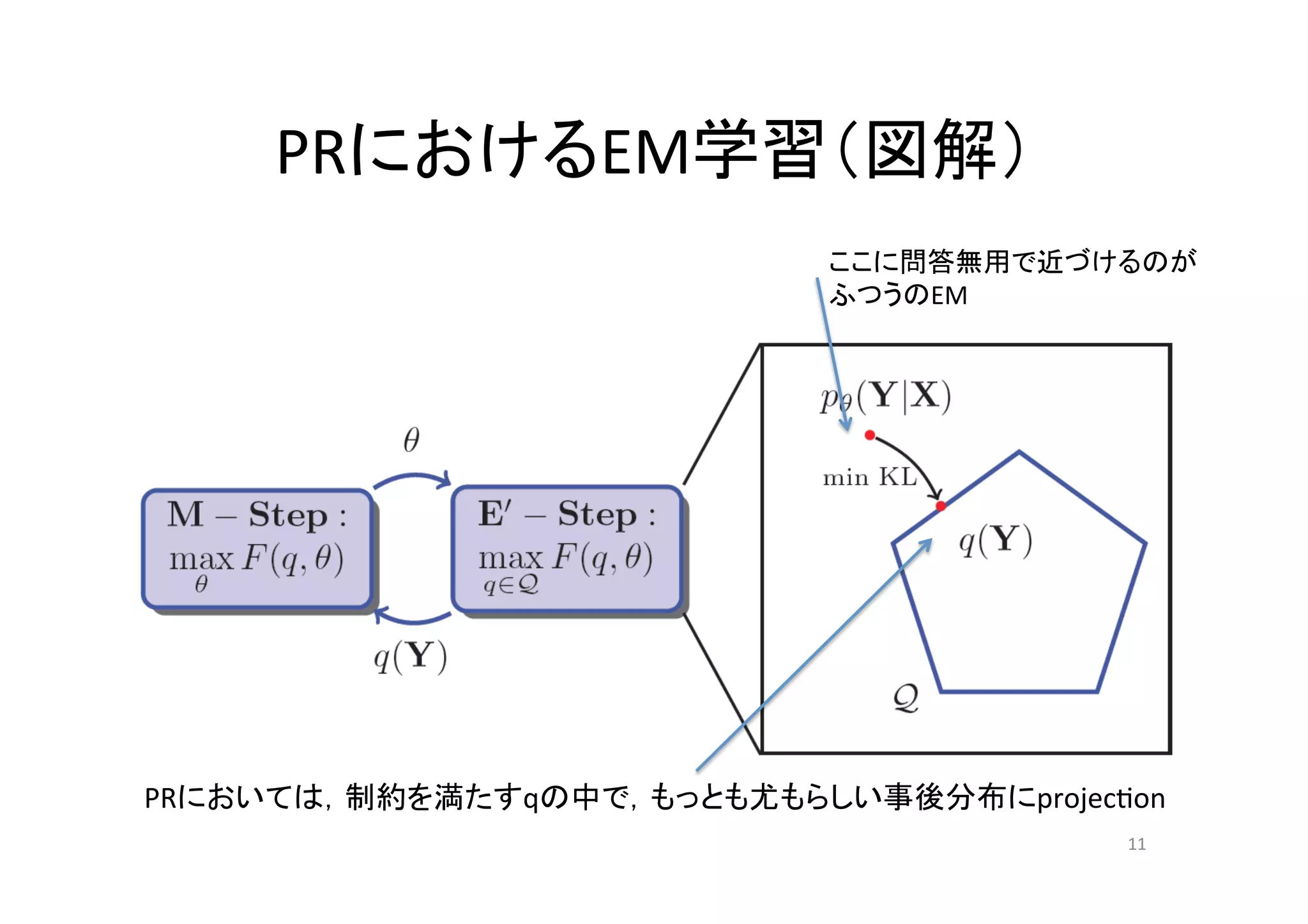
PRにおけるEM学習(図解)
ここに問答無用で近づけるのが ふつうのEM PRにおいては,制約を満たすqの中で,もっとも尤もらしい事後分布にprojec.on 11
12.
実装例 constraint.project() は問題(制約)依存だが既存のgradientベースのソルバで解ける
12
13.
Unified EM(ここからが本論文) • PRのE-‐StepはKLダイバージェンスを最小化
KL(q , p) = ∑y q(y) log q(y) – q(y) log p(y) • modified KL Divergenceを導入 KL(q , p; °) = ∑y ° q(y) log q(y) – q(y) log p(y) • ここで°がどういう役割を果たしているか考え る 13
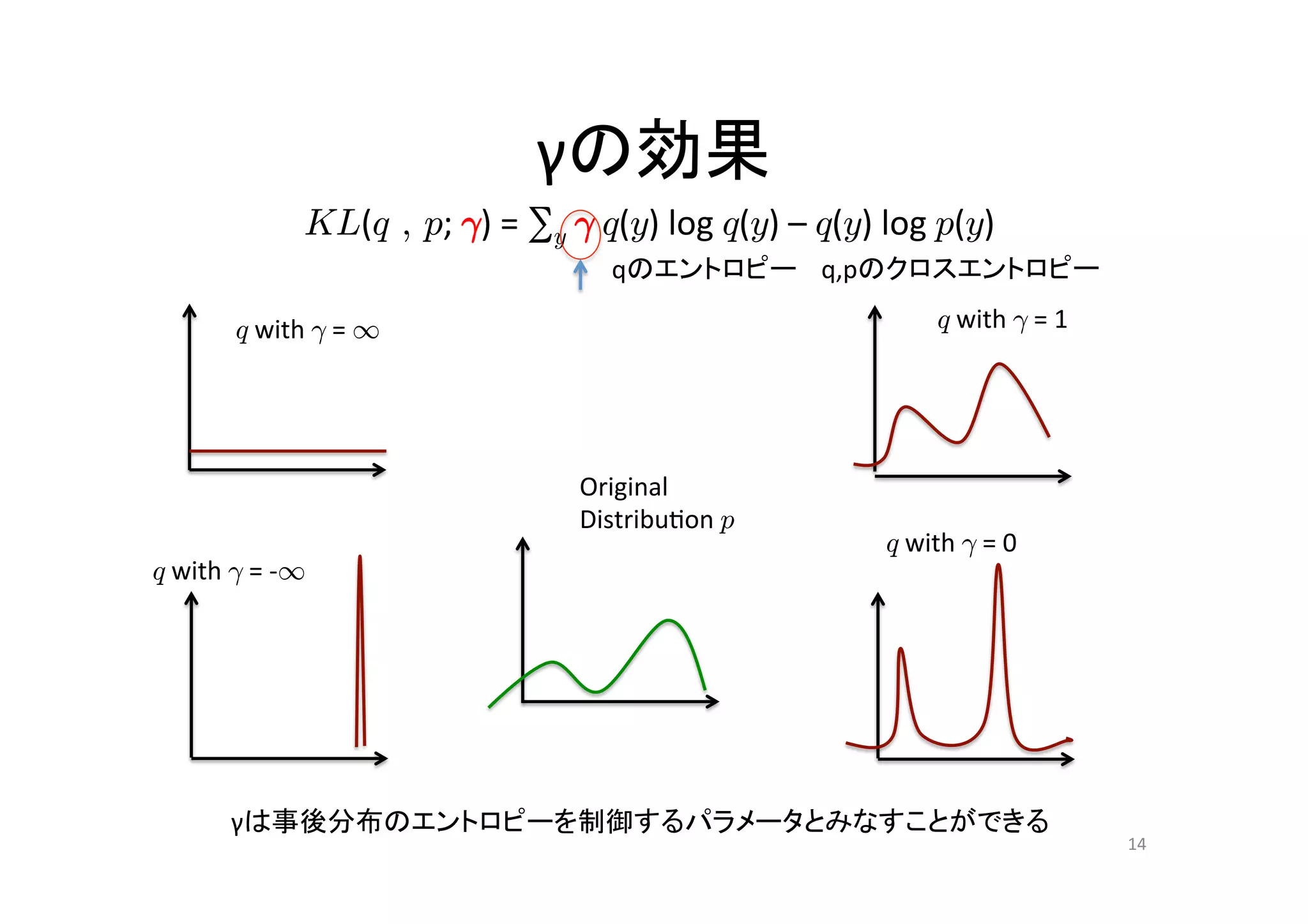
14.
γの効果
KL(q , p; °) = ∑y ° q(y) log q(y) – q(y) log p(y) qのエントロピー q,pのクロスエントロピー q with ° = 1 q with ° = 1 Original Distribu.on p q with ° = 0 q with ° = -‐1 γは事後分布のエントロピーを制御するパラメータとみなすことができる 14
15.
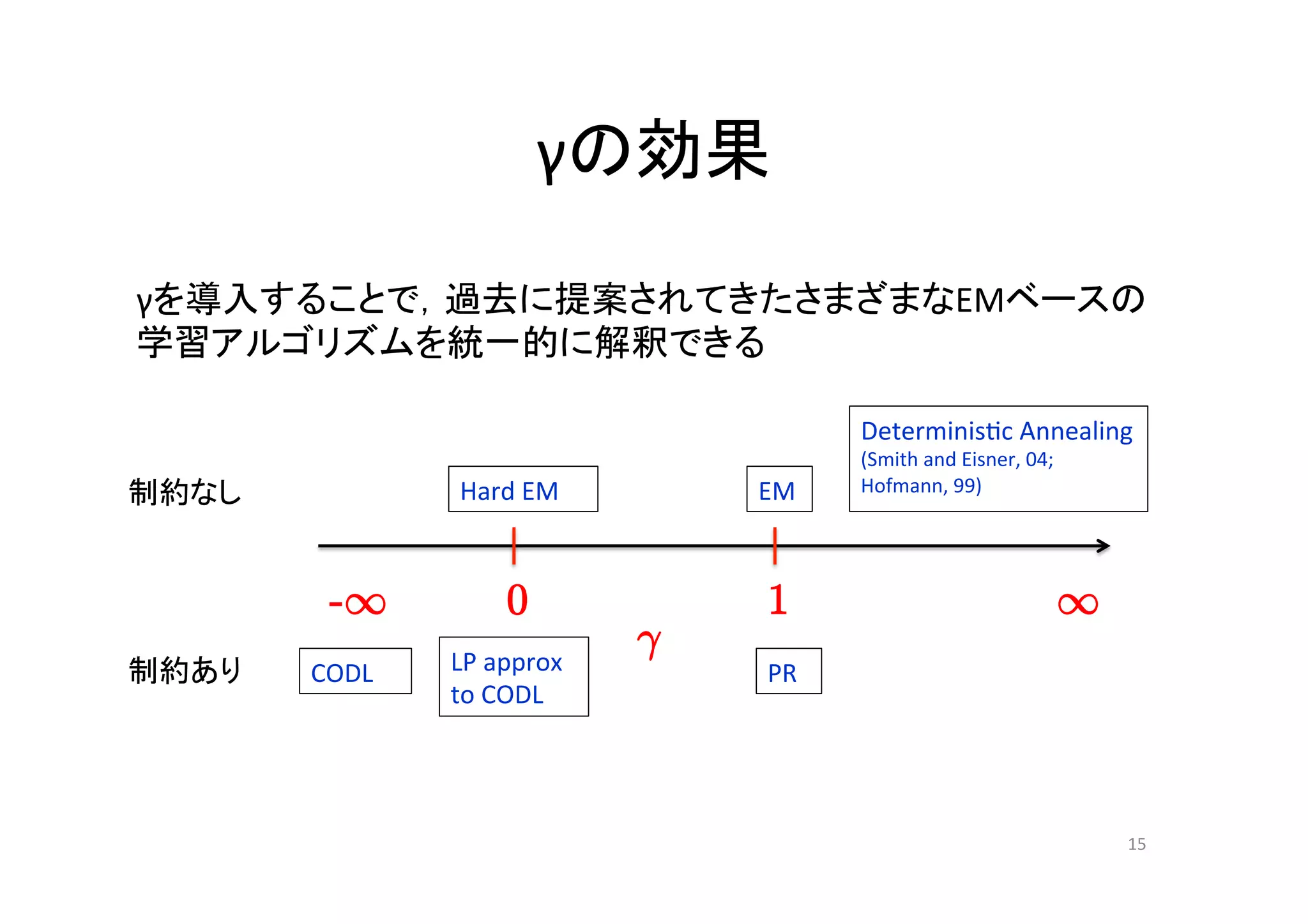
γの効果 γを導入することで,過去に提案されてきたさまざまなEMベースの 学習アルゴリズムを統一的に解釈できる
Determinis.c Annealing (Smith and Eisner, 04; 制約なし Hard EM EM Hofmann, 99) -1 0 1 1 LP approx ° 制約あり CODL PR to CODL 15
16.
制約つきE-‐Stepの計算
modified KL divergence 制約の期待値 q(y)のsimplex制約 γ ≧ 0 であればconvexなので,(劣)勾配法で最小化が可能 16
17.
制約つきE-‐Stepの計算 • ラグランジュ変数λを各制約に対して導入
– あとは劣勾配法でλとqを更新していくだけ G(・)は論文参照 いわゆるヘルパ 17
18.
制約付きE-‐Stepの計算 • 制約および分布が分解できる場合は双対分
解を用いることができる たとえば,等式制約を 二つの不等式制約 (上下から抑える)に 分けたり, アラインメントのように 双方向で一致するような 制約を入れたりできる 18
19.
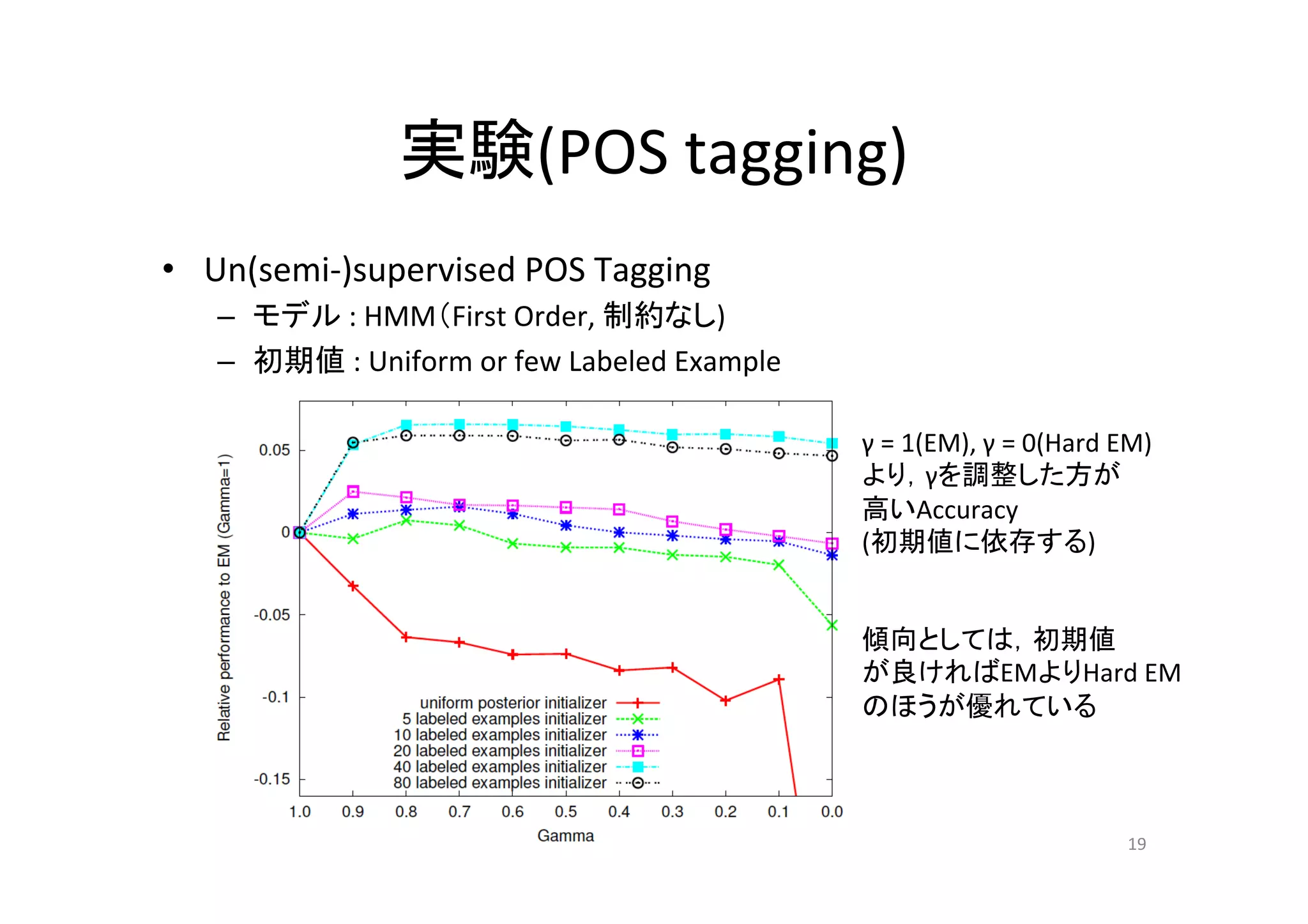
実験(POS tagging) • Un(semi-‐)supervised
POS Tagging – モデル : HMM(First Order, 制約なし) – 初期値 : Uniform or few Labeled Example γ = 1(EM), γ = 0(Hard EM) より,γを調整した方が 高いAccuracy (初期値に依存する) 傾向としては,初期値 が良ければEMよりHard EM のほうが優れている 19
20.
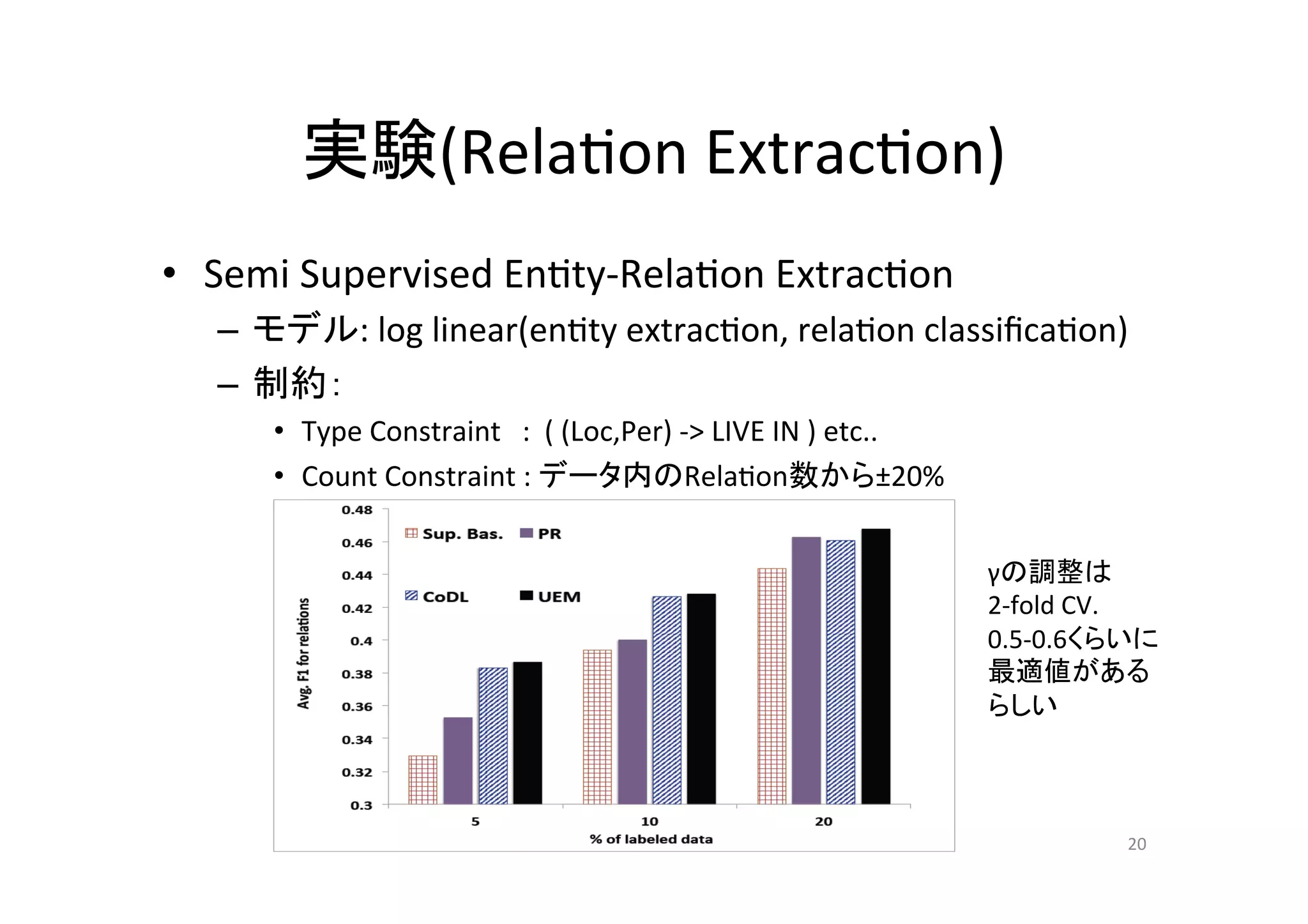
実験(Rela.on Extrac.on) • Semi
Supervised En.ty-‐Rela.on Extrac.on – モデル: log linear(en.ty extrac.on, rela.on classifica.on) – 制約: • Type Constraint : ( (Loc,Per) -‐> LIVE IN ) etc.. • Count Constraint : データ内のRela.on数から±20% γの調整は 2-‐fold CV. 0.5-‐0.6くらいに 最適値がある らしい 20
21.
実験(Word Alignment) • モデル:
HMM,MBRデコード • 制約:bi-‐direc.onal agreement • E-‐Stepは双対分解(ループ数5,けっこう重い?) γはdevelopment setで決定, 0.5-‐0.7くらいに最適値があるらしい 21
22.
まとめ • EMに基づくun(semi) supervisedな学習において,事前知識を導入する手
法のひとつPosterior Regulariza.on を紹介 • PRを含んだ様々な(制約付き)EMアルゴリズムを内包するアルゴリズムと して,UEMを紹介 • この論文のContribu.on – KLダイバージェンスにパラメータを一個足すことで,CoDL, PRを一般化できるこ とを示した – ラグランジュ緩和による効率的なE-‐Stepの計算法を示した – 実験において,PR(γ=1)とCoDL(γ=-‐inf)の間に最適なγがあることを明らかにした – (EM, PRのコードがあれば)実装が非常に簡単なのもポイントらしい • 感想 – 思っていたのとはちょっと違った,Posterior Regulariza.onは面白そう,双対分 解する必要性がどれくらいあるものなの?ICML Workshopにまったく同じ内容 の論文出てますね(今気づいた) 22
23.
Further Reading • Posterior
Regulariza.on for Structured Latent Variable Models [Ganchev+ JMLR 2010] – PRについて恐らくもっとも詳しく書いてある文献 • Rich Prior Knowledge in Learning for NLP [Druck+ ACL 2011 Tutorial] – PR, CODL, その他の類似フレームワークについて整理されたチュート リアル.スライドがわかりやすい. – hup://sideinfo.wikkii.com/ • MALLET – PR,GE (for Maxent, linear-‐chain CRF)のコードが含まれている – hup://mallet.cs.umass.edu/ge-‐classifica.on.php 23
Download

![Unified
EM
Algorithm
• [Samdani+
NAACL’12]
– EMによる(Semi-‐supervised)学習の統一的な解釈
• この論文のアイデアは非常にシンプル
– 構造に「制約」が無い場合は簡単(アニーリング
EMの拡張)
– 構造に「制約」が入る場合はややこしい
• Prior
Work
主にこっちのお話をします
– Posterior
Reguraliza.on
[Ganchev+
JMLR’10]
– Constraint
Driven
Learning
[Chang+
ACL’07]
2](https://image.slidesharecdn.com/preg-pptx-130323092445-phpapp02/75/Unified-Expectation-Maximization-2-2048.jpg)


![EM学習において,
どのように事前知識を入れるか
• 制約をどのように表現するか
• 制約を用いた学習はどうすれば良いか
Posterior
Regulariza.on
COnstraint
Driven
Learning
[Ganchev
et
al,
2010]
[Chang
et
al,
2007]
制約を「ソフト」に入れる
制約を「ハード」に入れる
「制約を満たす分布」とのKLダイバージェンス最小化
ビームサーチ
+
hard
EM
(今回は紹介しません)
Unified
EM
一つパラメータを導入することで,一般的な解釈
ラグランジュ緩和に基づく効率的なE-‐stepの計算
5](https://image.slidesharecdn.com/preg-pptx-130323092445-phpapp02/75/Unified-Expectation-Maximization-5-2048.jpg)

![PRにおける制約の表現(1/2)
• 制約の「素性表現」を導入
– 文書分類の例) ある文書が”poli.cs”
! (x, y) = ! 1 if y is "politics"
#
"
# 0
$ otherwise
• 素性の「期待値」を取る
– 文書分類の例) 25%の文書が”poli.cs”
E p! [" (x, y)] = b 期待値を取るのは「モデル全体として」
のソフトな制約を入れるため
b = 0.25 (期待値をとらないハードな手法もある)
bは一般にはベクトル表現になる(多数
の制約を入れるため)
7](https://image.slidesharecdn.com/preg-pptx-130323092445-phpapp02/75/Unified-Expectation-Maximization-7-2048.jpg)










![Further
Reading
• Posterior
Regulariza.on
for
Structured
Latent
Variable
Models
[Ganchev+
JMLR
2010]
– PRについて恐らくもっとも詳しく書いてある文献
• Rich
Prior
Knowledge
in
Learning
for
NLP
[Druck+
ACL
2011
Tutorial]
– PR,
CODL,
その他の類似フレームワークについて整理されたチュート
リアル.スライドがわかりやすい.
– hup://sideinfo.wikkii.com/
• MALLET
– PR,GE
(for
Maxent,
linear-‐chain
CRF)のコードが含まれている
– hup://mallet.cs.umass.edu/ge-‐classifica.on.php
23](https://image.slidesharecdn.com/preg-pptx-130323092445-phpapp02/75/Unified-Expectation-Maximization-23-2048.jpg)














































