[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embedding Features
1.
1
DEEP LEARNING JP
[DLPapers]
http://deeplearning.jp/
Discriminative Learning for Monaural Speech
Separation Using Deep Embedding Features
Hiroshi Sekiguchi, Morikawa Lab
2.
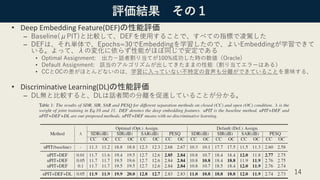
書誌情報
• “Discriminative Learningfor Monaural Speech Separation Using Deep
Embedding Features” (Interspeech 2019)
Author: Cunhang Fan, Bin Liu, Jianhua Tao, Jiangyan Yi, Zhengqi Wen
NLPR, Institute of Automation, Chinese Academy of Science, Beijing China
• 概要:
– モノラル信号の重畳音声分離を,最近注目の2手法、Deep Clusteringと
Utterance Permutation Invariant Trainingの良いとこ取りをし,かつ, end-to-
endでの学習を行い,単体の手法よりも“不特定話者”の複数音声分離性能を
上げた. 注)”不特定話者”とは、学習に含まれない話者のこと
– さらに,Discriminative Learningを追加して,分離性能を上げた.
• 動機
– 研究関連分野の論文レビュー 2
参考文献
• J. R.Hershey, Z. Chen, J. L. Roux, and S. Watanabe, “Deep clustering:
Discriminative embeddings for segmentation and separation," in IEEE
International Conference on Acoustics, Speech and Signal Processing, 2016,
• M. Kolbæk, D. Yu, Z. Tan, J. Jensen, M. Kolbaek, D. Yu, Z. Tan, and J. Jensen,
“Multitalker speech separation with utterance-level permutation invariant
training of deep recurrent neural networks,” IEEE/ACM Transactions on
Audio, Speech and Language Processing (TASLP), vol. 25, no. 10, pp. 1901–
1913, 2017
17
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Discriminative Learning for Monaural Speech
Separation Using Deep Embedding Features
Hiroshi Sekiguchi, Morikawa Lab](https://image.slidesharecdn.com/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259/85/DL-Discriminative-Learning-for-Monaural-Speech-Separation-Using-Deep-Embedding-Features-1-320.jpg)
![1
DEEP LEARNING JP
[DL Papers]
http://deeplearning.jp/
Discriminative Learning for Monaural Speech
Separation Using Deep Embedding Features
Hiroshi Sekiguchi, Morikawa Lab](https://image.slidesharecdn.com/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259/75/DL-Discriminative-Learning-for-Monaural-Speech-Separation-Using-Deep-Embedding-Features-1-2048.jpg)



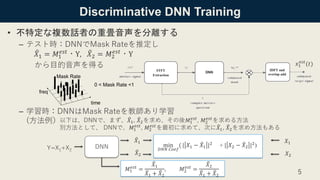

![Permutation Invariant Training(PIT):
• 時間フレーム内のPermutation Invariant問題:各フレーム毎に、複数のDNN出力( 𝑋𝑠)と
Target話者(𝑋 𝑠′)、𝑠, 𝑠′
= 1, ⋯ , 𝑆のペアリングを事前に固定して割り当ててしまう(例えば
𝑠 = 𝑠′
)と、似た音質の複数話者では、異なるフレームで話者の割り当てが誤まる
解決法がPIT:複数の出力( 𝑋𝑠)とTarget話者( 𝑋 𝑠′)、 𝑠, 𝑠′ = 1, ⋯ , 𝑆のペアリングを固定せずに
話者数(S)のPermutation(S!)回分の、出力-話者ペアリング組み合わせLoss関数を計算し、
最少のLoss関数値を出力する出力ー話者ペアリングを正しいとする
ロス関数:𝐽𝑖
𝑃𝐼𝑇
= min
Φ∈𝑃
σ 𝑠=1
𝑆
𝑌𝑖 (𝑡, 𝑓) ⊙ ෩𝑀𝑠,𝑖 𝑡, 𝑓 − 𝑋Φ 𝑝 𝑠 ,𝑖(𝑡, 𝑓)
𝐹
2
ここで、i:フレーム、Φ 𝑝 𝑠 、𝑝 ∈ [1, ⋯ , 𝑆!]はtarget話者の割り当て、 ෩𝑀𝑠,𝑖 𝑡, 𝑓 :マスク予
測子、 ⊙:要素ごと乗算、 𝑌𝑖 𝑡, 𝑓 , ෩𝑀𝑠,𝑖 𝑡, 𝑓 , 𝑋Φ 𝑝 𝑠 ,𝑖(𝑡, 𝑓):フレームiのベクトル 7
Y=X1+X2
DNN
𝑋1
𝑋2
𝑋1
𝑋2
min
𝑅𝑁𝑁 𝐶𝑜𝑒𝑓
( | 𝑋1 − 𝑋1 |2
+ | 𝑋2 − 𝑋2 |2
)
フレーム
Target話者
フレーム
DNN出力
DNN出力 s=1がTarget話者s’=1と、
s=2がs’=2と固定の割り付けの例
𝑋1
𝑋2
正解はどちら?](https://image.slidesharecdn.com/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259/85/DL-Discriminative-Learning-for-Monaural-Speech-Separation-Using-Deep-Embedding-Features-7-320.jpg)
![Utterance-Level Permutation Invariant Training(μPIT):
• 話者トラッキングの問題: PITはフレームレベルでは、Loss関数が最小だが、 単語や文章
などの纏まった発声レベル(これをUtterance-levelという)では、出力と話者のペアリン
グはフレーム毎に変化してしまう。これでは、Test時にはフレーム毎のペアリング修正は
不可能なので、学習時に出力index 𝑠と話者index 𝑠′
が、発声レベルでは一貫して、紐づけ
られるようにしたい。
• 解決法がμPIT: 話者数(S)のPermutation(S!)回分の、出力-話者ペアリング組み合わせLoss
関数を発声レベル全部のフレームで計算し、最少のLoss関数値を出力する出力ー話者ペア
リングを正しいとする
ロス関数:𝐽Φ∗ = min
Φ∈𝑃
𝐽Φ 𝑝 𝑠 , 𝐽Φ 𝑝 𝑠 = σ 𝑠=1
𝑆
𝑌(𝑡, 𝑓) ⊙ ෩𝑀𝑠 𝑡, 𝑓 − 𝑋Φ 𝑝 𝑠 (𝑡, 𝑓)
𝐹
2
ここで、Φ 𝑝 𝑠 、𝑝 ∈ [1, ⋯ , 𝑆!]はtarget話者の割り当て、Φ∗
:最適割り当て、 ෩𝑀𝑠 𝑡, 𝑓 :マスク
予測子、𝑌 𝑡, 𝑓 , ෩𝑀𝑠 𝑡, 𝑓 , 𝑋Φ 𝑝 𝑠 (𝑡, 𝑓):行列 8
Y=X1+X2
DNN
𝑋1 𝑡1 , ⋯ , 𝑋1 𝑡 𝑇 𝑋2 𝑡1 , ⋯ , 𝑋2 𝑡 𝑇
MSE
Utteranceの全フレームで同一の
Target話者であるべき
Utteranceの全フレーム
DNN出力
この二者のいずれかにしたい
𝑋2 𝑡1 , ⋯ , 𝑋2 𝑡 𝑇 𝑋1 𝑡1 , ⋯ , 𝑋1 𝑡 𝑇
𝑋2 𝑡1 , ⋯ , 𝑋2 𝑡 𝑇
𝑋1 𝑡1 , ⋯ , 𝑋1 𝑡 𝑇](https://image.slidesharecdn.com/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259/85/DL-Discriminative-Learning-for-Monaural-Speech-Separation-Using-Deep-Embedding-Features-8-320.jpg)


![提案手法:DEF+μPIT+DL その3
③さらに、Discriminative Learning(DL)で、μPITのロス関数に、出力に紐
づいたTarget話者以外とのスペクトル振幅差が大きくなる要素を追加
する
𝐽 𝐷𝐿 = 𝐽Φ∗ − σΦ 𝑝 𝑠 ≠Φ∗,Φ 𝑝 𝑠 ∈𝑝 α 𝐽Φ 𝑝 𝑠 、α:正則化係数
2話者場合に、例として 最適紐づけ、Φ∗ = Φ1とした場合は以下.
𝐽 𝐷𝐿 = σ 𝑠=1
2
𝑌 ⊙ ෩𝑀1 − 𝑋1 𝐹
2
− α 𝑌 ⊙ ෩𝑀1 − 𝑋2 𝐹
2
+
𝑌 ⊙ ෩𝑀2 − 𝑋2 𝐹
2
− α 𝑌 ⊙ ෩𝑀2 − 𝑋1 𝐹
2
④Deep Embedding Feature(DEF) +μPITを通して、ロス関数を融合して、
end2endで学習する
𝐽 𝑇𝑜𝑡𝑎𝑙 = λ𝐽 𝐷𝐶 + 1 − λ 𝐽 𝐷𝐿, λ ∈ [0,1]:重みパラメータ
11](https://image.slidesharecdn.com/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259/85/DL-Discriminative-Learning-for-Monaural-Speech-Separation-Using-Deep-Embedding-Features-11-320.jpg)














![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Diffusion-based Voice Conversion with Fast Maximum Likelihood Samplin...](https://cdn.slidesharecdn.com/ss_thumbnails/20220318akuzawa-220322065615-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)



![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]SlowFast Networks for Video Recognition](https://cdn.slidesharecdn.com/ss_thumbnails/20191206slowfastnetworkkuboshizuma-191206010601-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Monaural Audio Source Separationusing Variational Autoencoders](https://cdn.slidesharecdn.com/ss_thumbnails/20190717dlmonauralaudiosourceseparationusingvariationalautoencodersver2-190719035345-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]VOICEFILTER: Targeted Voice Separation by Speaker-Conditioned Spectrog...](https://cdn.slidesharecdn.com/ss_thumbnails/20181116dlvoicefiltertargetedvoiceseparationbyspeaker-conditionedspectrogrammaskingver3-181116070937-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]An Iterative Framework for Self-supervised Deep Speaker Representatio...](https://cdn.slidesharecdn.com/ss_thumbnails/20220216dlaniterativeframeworkforself-superviseddeepspeakerrepresentationlearning-220218040109-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]音声言語病理学における機械学習とDNN](https://cdn.slidesharecdn.com/ss_thumbnails/201016dltext-to-speech-201016023355-thumbnail.jpg?width=640&height=640&fit=bounds)

























