More Related Content

PDF

PDF

PDF

PDF

PPTX

PDF
Large Scale Incremental Learning ![[DL輪読会]Measuring abstract reasoning in neural networks](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi0727-180727002112-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL輪読会]Measuring abstract reasoning in neural networks 
PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大) What's hot

PDF

PDF
テンソル多重線形ランクの推定法について(Estimation of Multi-linear Tensor Rank) 
PDF

PDF

PPTX
Image net classification with deep convolutional neural network 
PDF
KDD2014勉強会: Large-Scale High-Precision Topic Modeling on Twitter 
PDF

PPT
Deep Auto-Encoder Neural Networks in Reiforcement Learnning (第 9 回 Deep Learn... 
PPTX
CG Image Recognition with Deep Learning 
PDF

PDF

PDF
単語分散表現を用いた多層 Denoising Auto-Encoder による評価極性分類 
PDF

PDF
Deep Semi-Supervised Anomaly Detection 
PDF
パンハウスゼミ 異常検知論文紹介 20191005 
PDF

ODP
Introduction to "Facial Landmark Detection by Deep Multi-task Learning" 
PDF
Anomaly detection 系の論文を一言でまとめた 
PDF
PoisoningAttackSVM (ICMLreading2012) 
PDF
Viewers also liked

PDF

PDF

PDF

PDF

PDF
Tutorial of topological_data_analysis_part_1(basic) 
PDF
Topological data analysis 
PDF
エンジニアから飛んでくるマサカリを受け止める心得 
PDF

PDF

PDF

PDF

PDF
Similar to E-SOINN

PDF

PDF
PFI Christmas seminar 2009 
PDF
Appendix document of Chapter 6 for Mining Text Data 
KEY

PDF

PDF
オンライン凸最適化と線形識別モデル学習の最前線_IBIS2011 
PDF
2007 IEEE ICDM DMC task1 result 
PPTX
Pythonとdeep learningで手書き文字認識 
PDF
Semi-supervised Active Learning Survey 
PDF
Unified Expectation Maximization 
PDF

PDF
SIGIR2012勉強会 23 Learning to Rank 
PDF
LCCC2010:Learning on Cores, Clusters and Cloudsの解説 
PDF

PPTX

PDF

PDF

PDF

PDF

PDF
Recently uploaded

PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望 
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版 
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」 
PPTX

PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis 
PDF

PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜 
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信 
PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector E-SOINN
- 1.
1/27
E-SOINN
オンライン教師なし分類のための追加学習手法
東京工業大学
小倉和貴, 申富饒, 長谷川修
電子情報通信学会論文誌, D Vol. J90-D, No.6, pp.1610-1622 (2007)
- 2.
2/27
研究背景
• 教師なし追加学習の重要性
(実世界で活躍する知能の実現に向けて)
– 教師なし学習
• 教師のない学習データから、
データの背後に存在する本質的な構造を自律的に獲得すること
• 学習すべき対象全てに教師を与えることは困難
– 追加学習
• 過去の学習結果を破壊あるいは忘却せず、
新規の学習データに適応すること
• あらかじめ全てを学習しておくことは困難
(環境の変化に応じて、未知の知識を追加的に学習)
- 3.
- 4.
4/27
競合型ニューラルネットワークと
追加学習能力
• 自己組織化マップ SOM (T.Kohonen, 1982)
• Neural Gas (T.M.Martinetz, 1993)
– ネットワーク構造(ノード数など)を事前に決定
– 問題点:表現能力に限界がある
• Growing Neural Gas :GNG(B.Fritzke, 1995)
– ノードを定期的に挿入することで、追加学習に対応
– 問題点:永続的な学習には適さない
• GNG-U (B.Fritzke, 1997)
– ノードを削除することで、環境の変化に対応
– 問題点:既存の学習結果を破壊
- 5.
- 6.
6/27
SOINNにおける学習の流れ
入力データ
• 1層目に学習データを入力
– ノードを増殖させながら入力の
分布を近似
1層目 – 事前に決定された回数が入力
されると、学習を停止
• 1層目の学習結果を2層目に
入力
2層目 – 最終的な学習結果を取得
- 7.
7/27
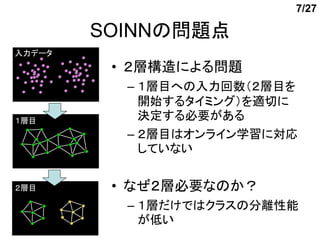
SOINNの問題点
入力データ
• 2層構造による問題
– 1層目への入力回数(2層目を
開始するタイミング)を適切に
1層目 決定する必要がある
– 2層目はオンライン学習に対応
していない
2層目 • なぜ2層必要なのか?
– 1層だけではクラスの分離性能
が低い
- 8.
8/27
本研究の目的
• SOINNに改良を加え
– クラス分離性能を向上させる
– 2層目が不要になり、SOINNの問題点を解決
入力データ 1層目 2層目
- 9.
9/27
クラス分離性能の向上
• 基本的な考え
– ノードの密度を定義
– サブクラスを定義
– 辺の必要性を判定(不要な辺を削除)
- 10.
10/27
ノードの密度
• 勝者ノード(入力ベクトルに最も近いノード)になった際、
以下のポイントを与える
:隣接ノードへの平均距離
• 「一定期間λに与えられるポイントの平均値」
を密度として定義
(ただし、ノード近傍に入力が与えられなかった期間は除く)
N:与えられたポイントが0以上の期間
:j番目の期間におけるk番目の
入力によって与えられたポイント
- 11.
11/27
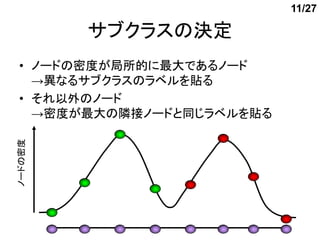
サブクラスの決定
• ノードの密度が局所的に最大であるノード
→異なるサブクラスのラベルを貼る
• それ以外のノード
→密度が最大の隣接ノードと同じラベルを貼る
ノードの密度
- 12.
12/27
辺の必要性(1)
• ノイズがある場合、ノードの密度には
細かい凹凸がある
→特定の条件を満たす辺は残す必要がある
ノードの密度
- 13.
13/27
辺の必要性(2)
• 以下の条件を満たす辺は残す
ノードの密度
A
Amax
×αA
ここで、αは以下の式で算出
B
Bmax
×αB m
:サブクラスAにおける密度の最大値
:サブクラスAにおける密度の平均値
- 14.
14/27
分離性能向上による効果
• 2層目が不要に
– 完全なオンライン学習が可能に
– 「クラス内挿入」が不要に(もう1つの効果)
- 15.
15/27
クラス内挿入の削除
• クラス内挿入とは?
– ノードを増殖させる処理の1つ
– 2層目において、活用される
• クラス内挿入の削除による利点
– 計算量の軽減
– パラメータ数の削減
従来手法(8つ)→提案手法(4つ)
- 16.
16/27
実験1:人工データその1
• 5クラス(ガウス分布×2、同心円×2、サインカーブ)
• 10%の一様ノイズ
• 従来手法は正しく学習できる(論文より)
追加学習における入力
1 2 3 4 5 6 7
A ○ ○
B ○ ○
C ○ ○
D ○ ○
E1 ○
E2 ○
E3 ○
- 17.
17/27
人工データその1:実験結果
• 従来手法と同様の結果が得られた
– 従来手法の利点を継承
(ノイズ耐性、クラス数・位相構造の自律的獲得)
通常の学習 追加学習
- 18.
18/27
実験2:人工データその2
• 3クラス(ガウス分布×3)
• 10%の一様ノイズ
• 実験1より高密度な重なりを持つ
追加学習における入力
1 2 3
A ○
B ○
C ○
- 19.
19/27
人工データその2:従来手法
Input First layer Second layer
• 高密度の重なりを持つクラスを分離できない
Input First layer Second layer
通常の学習 追加学習
- 20.
20/27
人工データその2:提案手法
• 従来手法を超える分離能力を実現
–
Input 高密度の重なりを持つクラスを分離できる
通常の学習 追加学習 デモ
- 21.
21/27
実験3:AT&T_FACE
• 10人の顔画像(各クラス10サンプル)
• 1/4に縮小し、平滑化した画像を使用
(23×28=644次元)
• 従来手法では正しく分類できる(論文より)
- 22.
22/27
AT&T_FACE:実験結果
• 従来手法と同等の結果が得られた
– 学習例(各クラスのプロトタイプベクトル)
認識率(%)
通常の学習 追加学習
提案手法 90 86
従来手法(論文より) 90 86
※得られたクラスのラベル(誰の顔か)は人が決定し、認識実験を行った
- 23.
- 24.
24/27
実験4:Optdigits
• 0~9までの手書き数字(10クラス)
• 8×8サイズ(64次元)
• データ数:3823(学習用)、1797(テスト用)
学習データの例(各クラスの平均ベクトル)
- 25.
25/27
Optdigits:実験結果
• 従来手法より適切な分類を実現
– 学習例(各クラスの平均ベクトル)
• 提案手法
• 従来手法
最頻出の 認識率(%)
クラス数 通常の学習 追加学習
提案手法 12 94.3 95.8
従来手法 10 92.2 90.4
※得られたクラスのラベル(どの数字か)は人が決定し、認識実験を行った
- 26.
26/27
まとめ
• SOINN(F.Shen, Neural Networks, 2006)を
改良した新しい教師なし学習手法を提案
– 従来手法(SOINN)の利点を継承
• ノイズ耐性
• クラス数、位相構造の自律的獲得
– 分布に重なりを持つクラスの分離性能を向上
– 完全なオンライン学習が可能に
– 安定性の向上
– パラメータ数の削減
- 27.
27/27
今後の課題
• 更なる安定性の向上
• 更なるパラメータ数の削減
• 学習結果の忘却