ロス関数は
物体の位置ずれである、localization loss (loc)と
物体のクラスである、confidence loss (conf)を組み合わせたもの
各画像で出てきた全ての出力に対して、(1)式を計算する
(Nはマッチしたボックスの数、重みαは実験では1.0)
Training Objective
29
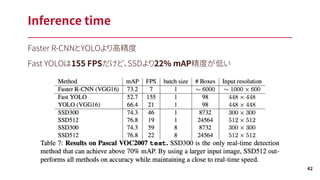
SSD300 is alreadybetter than Faster R-CNN by 1.1%
SSD512 is 3.6% better.
PASCAL VOC 2007
37
38.
- Data augmentationは重要
-Default boxは多い方がいい
- Atrous is faster
- 使わない場合は精度はほぼ同じで20%遅い
Model analysis
38
39.
- Multiple outputlayers at different resolutions is better
- SSDのメジャーコントリビューション
- conv7だけだと一番精度が低い
- ROI Poolingを使わないので"collapsing bins problem"は起きない
Model analysis
39
• [1] Girshick,Ross, et al. "Rich feature hierarchies for accurate object detection and semantic
segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
• [2] He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition."
European Conference on Computer Vision. Springer International Publishing, 2014.
• [3] Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE International Conference on Computer Vision. 2015.
• [4] Ren, Shaoqing, et al. "Faster R-CNN: Towards real-time object detection with region proposal networks."
Advances in neural information processing systems. 2015.
• [5] Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." arXiv preprint arXiv:
1506.02640 (2015).
• [6] Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." arXiv preprint arXiv:1512.02325 (2015).
• [7] Uijlings, Jasper RR, et al. "Selective search for object recognition." International journal of computer
vision 104.2 (2013): 154-171.
Appendix
45





![• R-CNN (Regions with CNN features) (CVPR 2014) [1]
• SPPnet (ECCV 2014) [2]
• Fast R-CNN (ICCV 2015) [3]
• Faster R-CNN (NIPS 2015) [4]
• YOLO(You Only Look Once) (CVPR 2016) [5]
Related Works
6](https://image.slidesharecdn.com/161203kantocvssd-161203041412/85/SSD-Single-Shot-MultiBox-Detector-ECCV2016-6-320.jpg)
![• R-CNN (Regions with CNN features) (CVPR 2014) [1]
• SPPnet (ECCV 2014) [2]
• Fast R-CNN (ICCV 2015) [3]
• Faster R-CNN (NIPS 2015) [4]
• YOLO(You Only Look Once) (CVPR 2016) [5]
Related Works
7
深いぃ歴史!](https://image.slidesharecdn.com/161203kantocvssd-161203041412/85/SSD-Single-Shot-MultiBox-Detector-ECCV2016-7-320.jpg)
![• R-CNN (Regions with CNN features) (CVPR 2014) [1]
• SPPnet (ECCV 2014) [2]
• Fast R-CNN (ICCV 2015) [3]
• Faster R-CNN (NIPS 2015) [4]
• YOLO(You Only Look Once) (CVPR 2016) [5]
Overview
8](https://image.slidesharecdn.com/161203kantocvssd-161203041412/85/SSD-Single-Shot-MultiBox-Detector-ECCV2016-8-320.jpg)

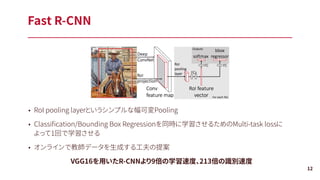
![■欠点
• 学習を各目的ごとに別々に学習する必要がある(Fine-tune/SVM/Bounding Box Regression)
• 実行時間がすごく遅い(GPUを使って10-45 [s/image])
R-CNN
10](https://image.slidesharecdn.com/161203kantocvssd-161203041412/85/SSD-Single-Shot-MultiBox-Detector-ECCV2016-10-320.jpg)
![• R-CNN (Regions with CNN features) (CVPR 2014) [1]
• SPPnet (ECCV 2014) [2]
• Fast R-CNN (ICCV 2015) [3]
• Faster R-CNN (NIPS 2015) [4]
• YOLO(You Only Look Once) (CVPR 2016) [5]
Overview
11](https://image.slidesharecdn.com/161203kantocvssd-161203041412/85/SSD-Single-Shot-MultiBox-Detector-ECCV2016-11-320.jpg)

![• R-CNN (Regions with CNN features) (CVPR 2014) [1]
• SPPnet (ECCV 2014) [2]
• Fast R-CNN (ICCV 2015) [3]
• Faster R-CNN (NIPS 2015) [4]
• YOLO(You Only Look Once) (CVPR 2016) [5]
Overview
14](https://image.slidesharecdn.com/161203kantocvssd-161203041412/85/SSD-Single-Shot-MultiBox-Detector-ECCV2016-14-320.jpg)

![• R-CNN (Regions with CNN features) (CVPR 2014) [1]
• SPPnet (ECCV 2014) [2]
• Fast R-CNN (ICCV 2015) [3]
• Faster R-CNN (NIPS 2015) [4]
• YOLO(You Only Look Once) (CVPR 2016) [5]
Overview
17](https://image.slidesharecdn.com/161203kantocvssd-161203041412/85/SSD-Single-Shot-MultiBox-Detector-ECCV2016-17-320.jpg)
















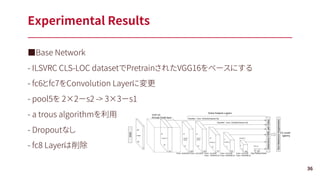
![下記3つの方法からランダムにとる
• 画像全体を利用
• Jaccard Overlapが{0.1, 0.3, 0.5, 0.7, 0.9} のパッチをサンプリング
• パッチをランダムサンプリング
パッチサイズはオリジナルの[0.1, 1]、aspect ratioは[1/2, 2]
もし、Cropしたサンプル内にGround Truthの領域が入っていたら、その領域はすべて含む
(その後)サンプリングした後に、各サンプルをリサイズして0.5の確率でFlip
Data augmentation
35](https://image.slidesharecdn.com/161203kantocvssd-161203041412/85/SSD-Single-Shot-MultiBox-Detector-ECCV2016-35-320.jpg)






![• [1] Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic
segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
• [2] He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition."
European Conference on Computer Vision. Springer International Publishing, 2014.
• [3] Girshick, Ross. "Fast r-cnn." Proceedings of the IEEE International Conference on Computer Vision. 2015.
• [4] Ren, Shaoqing, et al. "Faster R-CNN: Towards real-time object detection with region proposal networks."
Advances in neural information processing systems. 2015.
• [5] Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." arXiv preprint arXiv:
1506.02640 (2015).
• [6] Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." arXiv preprint arXiv:1512.02325 (2015).
• [7] Uijlings, Jasper RR, et al. "Selective search for object recognition." International journal of computer
vision 104.2 (2013): 154-171.
Appendix
45](https://image.slidesharecdn.com/161203kantocvssd-161203041412/85/SSD-Single-Shot-MultiBox-Detector-ECCV2016-45-320.jpg)



![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/pvrcnn-200311050009-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]StarGAN: Unified Generative Adversarial Networks for Multi-Domain Ima...](https://cdn.slidesharecdn.com/ss_thumbnails/171222stargan-171225064145-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DeepLearning論文読み会] Dataset Distillation](https://cdn.slidesharecdn.com/ss_thumbnails/datasetdistillation-181114165952-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DLHacks LT] PytorchのDataLoader -torchtextのソースコードを読んでみた-](https://cdn.slidesharecdn.com/ss_thumbnails/torchtextupload-170918235754-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)




![[CVPR読み会]BING:Binarized normed gradients for objectness estimation at 300fps](https://cdn.slidesharecdn.com/ss_thumbnails/bing-140725194514-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=640&height=640&fit=bounds)





![[論文解説]Unsupervised monocular depth estimation with Left-Right Consistency](https://cdn.slidesharecdn.com/ss_thumbnails/unsupervisedmonoculardepthestimation-170809092538-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)


























