Recommended
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
PDF
semantic segmentation サーベイ
PPTX
近年のHierarchical Vision Transformer
PDF
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PPTX
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
PPTX
[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...
PPTX
PDF
PDF
PDF
物体検知(Meta Study Group 発表資料)
PDF
【DL輪読会】Vision-Centric BEV Perception: A Survey
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
PDF
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
PDF
MIRU2013チュートリアル:SIFTとそれ以降のアプローチ
PDF
PDF
PDF
PDF
PDF
論文紹介:Grad-CAM: Visual explanations from deep networks via gradient-based loca...
PPTX
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
PDF
PPTX
[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
PPTX
[DL輪読会]End-to-End Object Detection with Transformers
PDF
ICCV 2019 論文紹介 (26 papers)
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
More Related Content
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
PDF
semantic segmentation サーベイ
PPTX
近年のHierarchical Vision Transformer
PDF
PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ
PPTX
[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...
PPTX
[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...
PPTX
What's hot
PDF
PDF
PDF
物体検知(Meta Study Group 発表資料)
PDF
【DL輪読会】Vision-Centric BEV Perception: A Survey
PDF
SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法
PDF
PDF
【メタサーベイ】Vision and Language のトップ研究室/研究者
PDF
MIRU2013チュートリアル:SIFTとそれ以降のアプローチ
PDF
PDF
PDF
PDF
PDF
論文紹介:Grad-CAM: Visual explanations from deep networks via gradient-based loca...
PPTX
PPTX
[DL輪読会]Focal Loss for Dense Object Detection
PDF
【論文読み会】Deep Clustering for Unsupervised Learning of Visual Features
PDF
PPTX
[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
PPTX
【DL輪読会】Efficiently Modeling Long Sequences with Structured State Spaces
PPTX
[DL輪読会]End-to-End Object Detection with Transformers
Similar to 物体検出の歴史まとめ(1) 20180417
PDF
ICCV 2019 論文紹介 (26 papers)
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
PDF
Convolutional Neural Networks のトレンド @WBAFLカジュアルトーク#2
PDF
PDF
object detection with lidar-camera fusion: survey (updated)
PDF
[DL輪読会]YOLO9000: Better, Faster, Stronger
PPTX
論文紹介: Fast R-CNN&Faster R-CNN
PDF
PDF
SSD: Single Shot MultiBox Detector (ECCV2016)
PDF
【DLゼミ】XFeat: Accelerated Features for Lightweight Image Matching
PPTX
PDF
Tutorial-DeepLearning-PCSJ-IMPS2016
PDF
PPTX
PPTX
PDF
DeepLearningDay2016Summer
PDF
PDF
SAS Viyaのディープラーニングを用いた物体検出
PDF
cvpaper.challenge -サーベイの共有と可能性について- (画像応用技術専門委員会研究会 2016年7月)
PDF
CVPR2015読み会 "Joint Tracking and Segmentation of Multiple Targets"
More from Masakazu Shinoda
PDF
Batch normalization effectiveness_20190206
PDF
Perception distortion-tradeoff 20181128
PDF
PPTX
PDF
Network weight saving_20190123
PDF
PPTX
PDF
Ml desginpattern 16_stateless_serving_function_21210511
PDF
Ml desginpattern 12_checkpoints_21210427
物体検出の歴史まとめ(1) 20180417 1. 2. Agenda
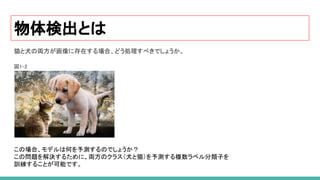
1. 物体検出とは
2. HOG機能を使用した物体検出
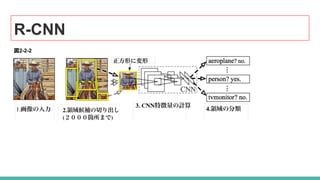
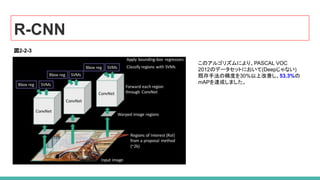
3. R-CNN (Region-based CNN)
non-maximum suppression
R-CNN の欠点
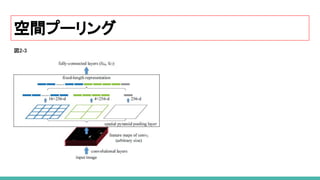
4. SPP-net(spatial pyramid pooling)
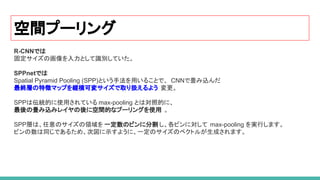
空間プーリング
SPPの欠点
5. Fast R-CNN
Fast R-CNN の改善点
RoIプーリングの詳細
6. Faster R-CNN
ネットワーク概要
RPN(Region Proposal Network)の導入
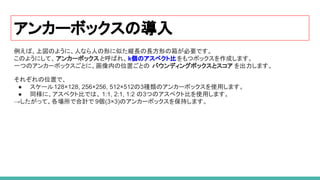
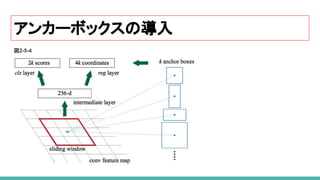
アンカーボックスの導入
Regressionベースの物体検出
7. YOLO(You only Look Once)
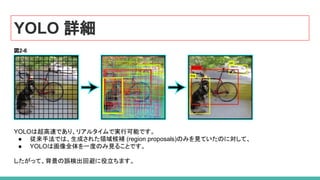
YOLO 詳細
YOLOの欠点
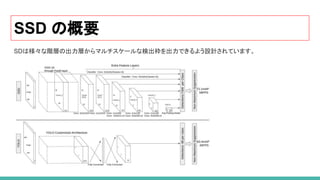
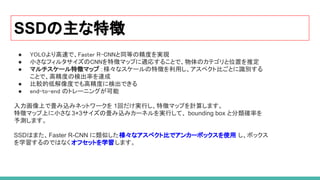
8. SSD(Single Shot Detector)
SSDの主な特徴
初期ボックスとアスペクト比
Jaccard係数
初期ボックスのスケールとアスペクト比の選択
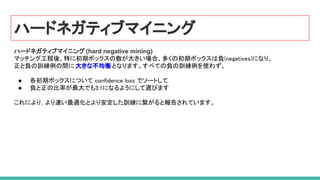
ハードネガティブマイニング (hard negative mining)
データ拡張
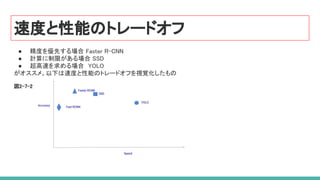
速度と性能のトレードオフ
SSD のVOC2007のデータセットにおいての成績
9. Mask R-CNN
ブランチ部の入力と出力
RoiAlign :RoIPoolの再配置
バイリニア補間
10. まとめ
3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. non-maximum suppression
IoU(Intersection over Union)値とは、画像の重なりの割合を表す値であり、
この値が大きいほど画像が重なっている状態ということになります。
逆に、小さいほど重なっていない状態ということになります。
例えば、IoU=0のときは全く重なっていない状態ということになります。
non-maximum suppressionは、このIoUを利用して、同じクラスとして認識された重なっている
状態の領域を抑制するためのアルゴリズムです。
IoU値の閾値を0.3という具合に定め、この閾値よりも大きいものを重複した物体領域の候補として
外し、閾値に満たないものは、物体領域の候補として残すことになります。
23. 24. 25. SPP-netの特長
従来手法の問題
Selective Search によって生成された2000の領域候補(region proposal)上でCNNを実行すると、
多くの時間がかかる。
SPP-Net はこの改善を試みたもので、画像1枚から一回の CNNで大きな特徴マップを作成した後、
領域候補の特徴をSPPによってベクトル化し、スピードは GPU上にて24-102倍に高速化を実現。
(2000個の領域候補はかなり領域の重複が多いため、重複する画像領域を CNNで特徴抽出するのはかなり無
駄)
その領域に対応する 最後の畳み込み層の特徴マップのその部分だけにプーリング操作を実行 する
ことで実現。
中間層で起こるダウンサンプリング( VGGの場合は座標を単に 16で割る)を考慮に入れて、
畳み込み層上の領域を投影することによって、領域に対応する畳み込み層の矩形部分は計算可能。
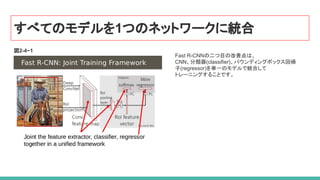
26. 27. 28. 29. 30. Fast R-CNNの特長
● RoI pooling layerという、SPPのpyramid構造を取り除いたシンプルな幅可変 poolingを行う
● classification/bounding box regressionを同時に学習させるための multi-task loss
によって1回で学習ができるようにする (ad hocでない)
● オンラインで教師データを生成する工夫
● multi-task lossの導入により、Back Propagationが全層に適用できるようになったため、
全ての層の学習が可能に。
● 実行速度は、VGG16を用いたR-CNNより9倍の学習速度、213倍の識別速度で、 SPPnetの3倍
の学習速度、10倍の識別速度を達成。
31. 32. RoI (Region of Interest) プーリング
関心領域プーリング、又は RoIプーリング
畳み込みニューラルネットワークを使用する物体検出タスクで広く使用される操作です。
その目的は、不均一なサイズの入力に対して最大プールを実行して、固定サイズの特徴マップ
(たとえば7×7)を得ることです。2015年4月にRoss Girshickによって最初に提案されています。
オープンソースのRoIプーリング実装例
https://github.com/deepsense-ai/roi-pooling
画像の多くの領域候補が必ず重複し、同じ CNN計算を何度も(最大2000回)実行していました。
なので、画像を一回のみ CNN実行し、領域間で計算結果を共有しようと試みました。
CNNの特徴マップから対応する領域を選択することによって、各領域の CNN特徴がどのように
取得されるかを確認します。次に各領域の特徴がプーリングされます(通常 max poolingを使用)。
したがって、従来手法の最大 2000回とは対照的に、元の画像の 1回のパスのみCNNが実行されます。
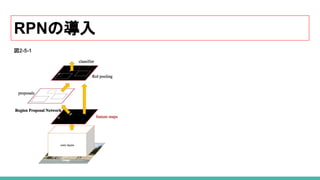
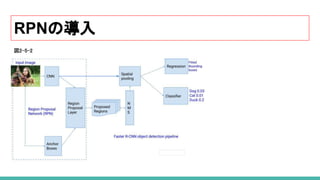
33. 34. 35. 36. 37. 38. 39. 40. 41. RPN(Region Proposal Network)の導入
Fast R-CNN のネットワーク全体のボトルネックは、 Selective Search を利用した領域候補の
生成部分でした。
Faster R-CNN では、ROI(region of interest)の生成のために、Selective Searchを
RPN(Region Proposal Network) と言われる小さな畳み込みネットワークに入れ替えました。
RPNへ渡す特徴マップの生成前に一度だけ CNNを実行します。
42. 43. 44. 45. 46. 47. 48. 49. 50. 51. YOLO(You only Look Once) の概要
YOLOは予め画像全体をグリッド分割しておき、各領域ごとに物体のクラスと bounding boxを求める、
という方法を採用。
CNNのアーキテクチャがシンプルになったため、 Faster R-CNNに識別精度は少し劣りますが
45-155FPSの検出速度を達成。
またスライディングウィンドウや領域候補 (Region Proposal)を使った手法と違い、
1枚の画像の全ての範囲を学習時に利用するため、周辺のコンテクストも同時に学習することが
できます。
これにより、背景の誤検出を抑えることができるようになり、背景の誤検出は Fast R-CNNの
約半分の抑えることが出来ました。
52. YOLO 詳細
画像全体をS×Sのグリッドに分割し、各グリッドは N個の bounding box と confidence を予測。confidence
は、
● bounding box の精度と
● bounding box が実際にオブジェクトを含むかどうか(クラスに関係なく)
を反映します。
YOLO はまた、トレーニング中の各クラスの各 bounding box の分類スコアを予測します。
両方のクラスを組み合わせて、各クラスが予測される bounding box に存在する確率を計算
することができます。
↓
合計SxSxN 個の bounding box が予測されますが、
多くの bounding box は confidence スコアが低く、しきい値を30%と設定すると、
ほとんどのものが削除されます。
53. 54. 55. 56. 57. SSDの主な特徴
● YOLOより高速で、Faster R-CNNと同等の精度を実現
● 小さなフィルタサイズのCNNを特徴マップに適応することで、物体のカテゴリと位置を推定
● マルチスケール特徴マップ :様々なスケールの特徴を利用し、アスペクト比ごとに識別する
ことで、高精度の検出率を達成
● 比較的低解像度でも高精度に検出できる
● end-to-end のトレーニングが可能
入力画像上で畳み込みネットワークを 1回だけ実行し、特徴マップを計算します。
特徴マップ上に小さな 3×3サイズの畳み込みカーネルを実行して、 bounding box と分類確率を
予測します。
SSDはまた、Faster R-CNN に類似した様々なアスペクト比でアンカーボックスを使用 し、ボックス
を学習するのではなく オフセットを学習します。
58. 59. 60. 61. 62. 63. 64. 65. ハードネガティブマイニング
ハードネガティブマイニング (hard negative mining)
マッチング工程後、特に初期ボックスの数が大きい場合、多くの初期ボックスは負(negatives)になり、
正と負の訓練例の間に 大きな不均衡となります。すべての負の訓練例を使わず、
● 各初期ボックスについて confidence loss でソートして
● 負と正の比率が最大でも3:1になるようにして選びます
これにより,より速い最適化とより安定した訓練に繋がると報告されています。
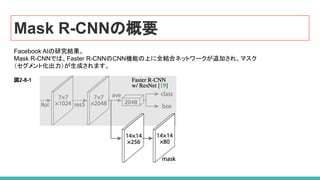
66. 67. 68. 69. 70. 71. 72. Mask R-CNNの概要
Mask R-CNNは、Faster R-CNN に分岐(上記の画像の白い部分)を追加し、指定ピクセルが
物体の一部かどうか を示すバイナリマスクを出力します。
追加されたブランチ部は、 CNNベースの特徴マップの上にある完全畳み込みネットワークです。
ブランチ部の入力と出力
● 入力:CNN特徴マップ
● 出力:物体なら1, 物体でないなら 0 を表すバイナリマスク、を持つ行列
このパイプラインを期待どおりに動作させるために、小さな調整を行う必要がありました。
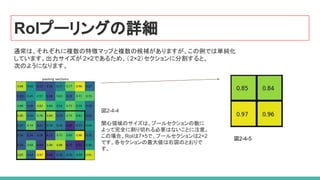
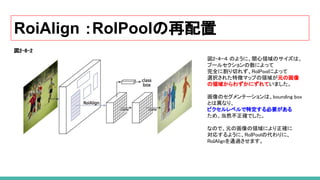
73. RoiAlign :RoIPoolの再配置
図2-8-2
図2-4−4 のように、関心領域のサイズは、
プールセクションの数によって
完全に割り切れず、RoIPoolによって
選択された特徴マップの領域が元の画像
の領域からわずかにずれていました。
画像のセグメンテーションは、bounding box
とは異なり、
ピクセルレベルで特定する必要がある
ため、当然不正確でした。
なので、元の画像の領域により正確に
対応するように、RoIPoolの代わりに、
RoIAlignを通過させます。
74. 75. 76. 77. 78. 79. 参考文献
[1] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
https://arxiv.org/abs/1406.4729
[2] SSD: Single Shot MultiBox Detector
https://arxiv.org/abs/1512.02325.
[3] R-CNN
https://arxiv.org/abs/1311.2524
[4] Fast R-CNN
https://arxiv.org/abs/1504.08083
[5] Faster R-CNN
https://arxiv.org/abs/1506.01497
[6] Mask R-CNN
https://arxiv.org/abs/1703.06870
80. 参考文献
[7] Zero to Hero: Guide to Object Detection using Deep Learning: Faster R-CNN,YOLO,SSD
http://cv-tricks.com/object-detection/faster-r-cnn-yolo-ssd/
[8] A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
https://blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4
[9] Mask R-CNN
https://www.slideshare.net/windmdk/mask-rcnn
[10] Region of interest pooling explained
https://blog.deepsense.ai/region-of-interest-pooling-explained/
[11] Instance segmentation with Mask R-CNN
https://lmb.informatik.uni-freiburg.de/lectures/seminar_brox/seminar_ss17/maskrcnn_slides.pdf
[12] 線形補間、バイリニア補間
https://goo.gl/snAcXQ
81. 参考文献
[13] A paper list of object detection using deep learning
https://github.com/hoya012/deep_learning_object_detection













![R-CNN
物体検出のタスクに対しても CNNのアルゴリズムを上手く応用できないか?という課題を解く
先駆けとなった論文 [3]です。
深層学習の登場後、物体検出はより正確な畳み込みニューラルネットワークに基づく分類器に置き換えられま
した。しかし、CNNは非常に遅く、計算上非常に高価で、スライディングウィンドウ検出器によって生成された非
常に多くのパッチでCNNを実行することは不可能でした。
R-CNNは、Selective Searchと呼ばれる物体候補 (object proposal)アルゴリズムを使用することで
この問題を解決しました。
R-CNNの目的は、画像を取り込み、画像内の主要な物体を bounding box を介して、正確に特定
することです。
● 入力:画像
● 出力:画像内の各物体の境界ボックス +ラベル
しかし、これらの bounding box がどこにあるのかをどのように見つけ出すのでしょうか?](https://image.slidesharecdn.com/objectdetection120180417-190425095416/85/1-20180417-17-320.jpg)




























![データ拡張
モデルを様々な入力物体サイズと形状に対してロバストにするために、各訓練画像は次に示す
オプションによってランダムにサンプリングしています。
● 元の入力画像全体を使用
● 物体との最小の jaccard overlap が0.1, 0.3, 0.4, 0.7, 0.9となるように パッチをサンプリング
● ランダムにパッチをサンプルする.
各サンプルパッチのサイズは元の画像サイズの[0.1, 1]で,アスペクト比は1/2と2の間。
サンプルパッチの中に正解ボックスの中心がある場合には,正解ボックスの重複部分は保持する
ものとします。
前述のサンプリングステップの後に,各サンプルパッチは,フォトメトリックな歪みを適用することに加えて,固定
サイズにリサイズされ,確率0.5で水平にフリップします。](https://image.slidesharecdn.com/objectdetection120180417-190425095416/85/1-20180417-66-320.jpg)




![RoiAlign:RoIPoolの再配置
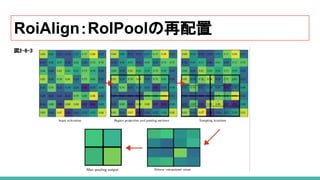
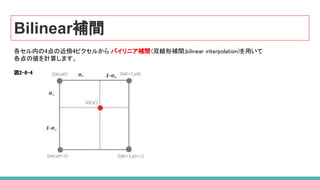
プールセクションのずれによる丸め誤差が発生していた RoIPoolの代わりに、RoIAlignでは、
このような丸め誤差を双線形補間 (biliear interpolation)([12])を使用して避けています。
補間処理した各セクションの値から Maxプーリングを行います。
これにより高いレベルで、 RoIPoolによって引き起こされる不整合を避けることができます。
これらのマスクが生成されると、 Mask R-CNNはそれらをFaster R-CNNの分類および bounding box
と組み合わせて、そのようなきわめて正確なセグメンテーションを生成します。](https://image.slidesharecdn.com/objectdetection120180417-190425095416/85/1-20180417-75-320.jpg)


![参考文献
[1] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
https://arxiv.org/abs/1406.4729
[2] SSD: Single Shot MultiBox Detector
https://arxiv.org/abs/1512.02325.
[3] R-CNN
https://arxiv.org/abs/1311.2524
[4] Fast R-CNN
https://arxiv.org/abs/1504.08083
[5] Faster R-CNN
https://arxiv.org/abs/1506.01497
[6] Mask R-CNN
https://arxiv.org/abs/1703.06870](https://image.slidesharecdn.com/objectdetection120180417-190425095416/85/1-20180417-79-320.jpg)
![参考文献
[7] Zero to Hero: Guide to Object Detection using Deep Learning: Faster R-CNN,YOLO,SSD
http://cv-tricks.com/object-detection/faster-r-cnn-yolo-ssd/
[8] A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN
https://blog.athelas.com/a-brief-history-of-cnns-in-image-segmentation-from-r-cnn-to-mask-r-cnn-34ea83205de4
[9] Mask R-CNN
https://www.slideshare.net/windmdk/mask-rcnn
[10] Region of interest pooling explained
https://blog.deepsense.ai/region-of-interest-pooling-explained/
[11] Instance segmentation with Mask R-CNN
https://lmb.informatik.uni-freiburg.de/lectures/seminar_brox/seminar_ss17/maskrcnn_slides.pdf
[12] 線形補間、バイリニア補間
https://goo.gl/snAcXQ](https://image.slidesharecdn.com/objectdetection120180417-190425095416/85/1-20180417-80-320.jpg)
![参考文献
[13] A paper list of object detection using deep learning
https://github.com/hoya012/deep_learning_object_detection](https://image.slidesharecdn.com/objectdetection120180417-190425095416/85/1-20180417-81-320.jpg)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Encoder-Decoder with Atrous Separable Convolution for Semantic Image S...](https://cdn.slidesharecdn.com/ss_thumbnails/deeplabv3-180309001425-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Objects as Points](https://cdn.slidesharecdn.com/ss_thumbnails/20190614centernetkuboshizuma-190614004246-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)


![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)





















