Download to read offline

![従来手法
◼DPM [Yan+, CVPR, 2011]
• スライディングウィンドウ方式により物体の検出
• クラス分類はその後
◼R-CNN [Girshick+, CVPR, 2014]
• Selective Researchにより物体の検出
入力画像 物体提案領域
出典:Qiita; 物体検出についての歴史まとめ](https://image.slidesharecdn.com/20220415youonlylookoncecvpr2016-220630005006-855c4273/85/You-Only-Look-Once-Unified-Real-Time-Object-Detection-3-320.jpg)
![従来手法
◼DPM [Yan+, CVPR, 2011]
• スライディングウィンドウ方式により物体の検出
• クラス分類はその後
◼R-CNN [Girshick+, CVPR, 2014]
• Selective Researchにより物体の検出
入力画像 物体提案領域
出典:Qiita; 物体検出についての歴史まとめ](https://image.slidesharecdn.com/20220415youonlylookoncecvpr2016-220630005006-855c4273/85/You-Only-Look-Once-Unified-Real-Time-Object-Detection-4-320.jpg)
![従来手法
◼DPM [Yan+, CVPR, 2011]
• スライディングウィンドウ方式により物体の検出
• クラス分類はその後
◼R-CNN [Girshick+, CVPR, 2014]
• Selective Researchにより物体の検出
入力画像 物体提案領域
提案領域のみを
畳み込み
出典:Qiita; 物体検出についての歴史まとめ](https://image.slidesharecdn.com/20220415youonlylookoncecvpr2016-220630005006-855c4273/85/You-Only-Look-Once-Unified-Real-Time-Object-Detection-5-320.jpg)
![従来手法
◼DPM [Yan+, CVPR, 2011]
• スライディングウィンドウ方式により物体の検出
• クラス分類はその後
◼R-CNN [Girshick+, CVPR, 2014]
• Selective Researchにより物体の検出
入力画像 物体提案領域
提案領域の
クラス分類
出典:Qiita; 物体検出についての歴史まとめ](https://image.slidesharecdn.com/20220415youonlylookoncecvpr2016-220630005006-855c4273/85/You-Only-Look-Once-Unified-Real-Time-Object-Detection-6-320.jpg)
![物体特定とクラス分類は二段階で行っていた
従来手法
◼DPM [Yan+, CVPR, 2011]
• スライディングウィンドウ方式により物体の検出
• クラス分類はその後
◼R-CNN [Girshick+, CVPR, 2014]
• Selective Researchにより物体の検出
入力画像 物体提案領域
出典:Qiita; 物体検出についての歴史まとめ](https://image.slidesharecdn.com/20220415youonlylookoncecvpr2016-220630005006-855c4273/85/You-Only-Look-Once-Unified-Real-Time-Object-Detection-7-320.jpg)

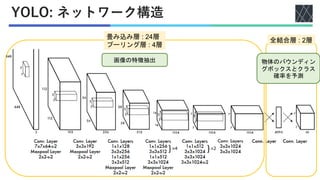
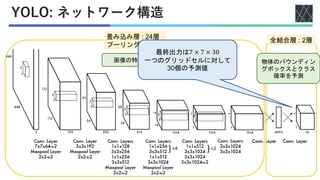

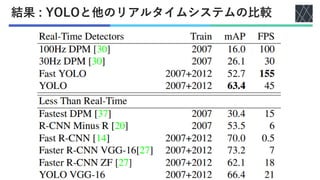
![実験1: 他のリアルタイムシステムとの比較
◼他のリアルタイムシステム
• DPM : 100Hz DPM [Forsyth+, ECCV, 2014], 30Hz DPM [Forsyth+, ECCV, 2014],
Fastest DPM [Yan+, CVPR, 2014]
• R-CNN : R-CNN Minus R [Lenc+, BMVC, 2015], Fast R-CNN [Girshick+, ICCV, 2015],
Faster R-CNN VGG-16 [Ren+, NIPS, 2016], Faster R-CNN ZF[Ren+, ICCV, 2015]
◼計算速度, 精度を比較
• 計算速度 : fpsを計測
• 精度 : mAP (平均適合率)
◼データセット: PASCAL VOC 2007, 2012
• 物体認識用データセット
• 人, 動物, 乗り物, 家具を含む画像
• クラス数 : 20(人, 鳥, 自転車, 椅子など)
全クラスでのAPの平均
AP (適合率) : PrecisionとRecallの関係
にから算出](https://image.slidesharecdn.com/20220415youonlylookoncecvpr2016-220630005006-855c4273/85/You-Only-Look-Once-Unified-Real-Time-Object-Detection-22-320.jpg)


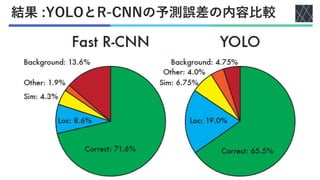
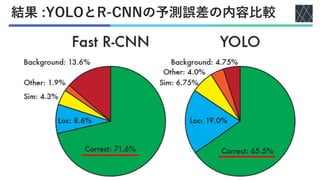
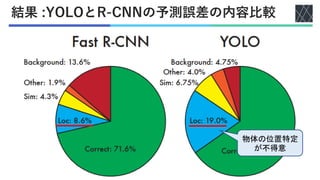
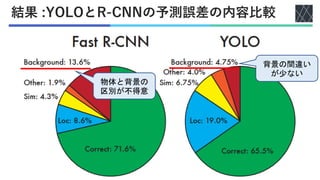
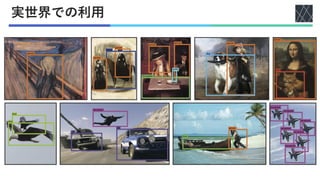


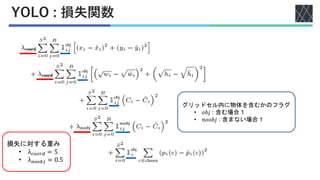
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi; You Only Look Once: Unified, Real-Time Object Detection, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 779-788 https://openaccess.thecvf.com/content_cvpr_2016/html/Redmon_You_Only_Look_CVPR_2016_paper.html








![SSII2022 [OS3-02] Federated Learningの基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/ssii2022-os3-02-220607020834-2b5f93ff-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)




![[研究室論文紹介用スライド] Adversarial Contrastive Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/acepub-181119101425-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]YOLO9000: Better, Faster, Stronger](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingpaper20170804-170803075138-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)





































