cvpaper.challenge の Meta Study Group 発表スライド
cvpaper.challenge はコンピュータビジョン分野の今を映し、トレンドを創り出す挑戦です。論文サマリ・アイディア考案・議論・実装・論文投稿に取り組み、凡ゆる知識を共有します。2019の目標「トップ会議30+本投稿」「2回以上のトップ会議網羅的サーベイ」
http://xpaperchallenge.org/cv/
Haar-like + AdaBoost(Hand-craftedfeat.)
7
Rapid Object Detection using a Boosted Cascade of Simple Features
著者 :Paul Viola, Michael Jones
論⽂:CVPR2001(Best Paper)
l 領域の陰影組み合わせ特徴,識別器による取捨選択
• 学習時には無数の陰影パターン/スケールの組み合わせ(左図)を⽣成
– AdaBoostにより識別に良好なパターンを選択
• 識別時にはカスケード型の識別器(右図)を使⽤
– 途中棄却(図中のF)を導⼊することで⾼速化
– 2001年当時のノートPCにてリアルタイムで動作するくらいには⾼速
8.
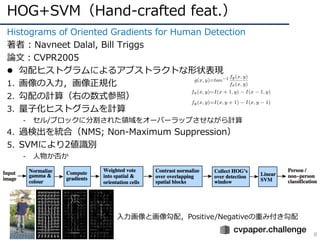
HOG+SVM(Hand-crafted feat.)
8
Histograms ofOriented Gradients for Human Detection
著者 : Navneet Dalal, Bill Triggs
論⽂:CVPR2005
l 勾配ヒストグラムによるアブストラクトな形状表現
1. 画像の⼊⼒,画像正規化
2. 勾配の計算(右の数式参照)
3. 量⼦化ヒストグラムを計算
- セル/ブロックに分割された領域をオーバーラップさせながら計算
4. 過検出を統合(NMS; Non-Maximum Suppression)
5. SVMにより2値識別
- ⼈物か否か
⼊⼒画像と画像勾配,Positive/Negativeの重み付き勾配
9.
ICF+Cascade(Hand-crafted feat.)
9
Integral ChannelFeatures
著者 : Piotr Dollarほか
論⽂:BMVC2009
l 多チャンネルから良好な特徴を識別器学習により獲得
1. 画像の⼊⼒
2. 多チャネルの前処理(下図参照)
- Grayscale, ||G||, edges, LUV, Gabor filter, gradient histogram, binary images,
DoG imaegs
3. カスケード型識別器により重み計算
- 有効な特徴量のみを残す
10.
DPM+LatentSVM(Hand-crafted feat.)
10
Object Detectionwith Discriminatively Trained Part Based Models
著者 :Pedro F. Felzenszwalb, Ross B. Girshick, David McAllester, Deva
Ramanan
論⽂:TPAMI 2012
l HOGをベース特徴に,全体(Root filter; RT)および部位ごと(Part
filters; PT)の評価をLatent SVMにより判断
画像ピラミッドからRT特徴量と解像
度を上げたPTの特徴量を抽出
PFに対する位置変動の潜在変数をLatent SVMに
より学習,RFも含めて全体の尤度が⾼い領域が
検出領域となる
11.
R-CNN(R-CNN)
11
Rich feature hierarchiesfor accurate object detection and semantic segmentation
(CVPR2014)
著者 : Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik
l 深層学習を取り⼊れた初の物体検出モデル,2ステージ物体検出モデルの元祖
1. 画像の⼊⼒
2. 物体候補の探索
- Selective Serchで画像中から領域の候補 (region proposal)を約2,000個抽出
- Selective Search: ピクセルレベルで類似する領域をグルーピングしていく⼿法 (かなり処理時間がかかる)
3. 物体の画像をリサイズし,CNNで特徴抽出
- 全ての物体候補を、CNN (AlexNet)の⼊⼒サイズに合うようにリサイズ
- リサイズした画像をCNN(AlexNet)に⼊⼒し、C特徴を抽出
4. SVMでクラス分類
- CNN特徴量から、SVMでクラス推定。論⽂では、Pascal VOC (20クラス+背景)で検証
- 実験では、全結合層でなくSVMを使った⽅が⾼精度
12.
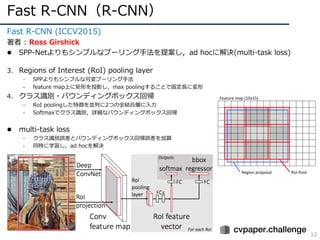
Fast R-CNN(R-CNN)
12
Fast R-CNN(ICCV2015)
著者 : Ross Girshick
l SPP-Netよりもシンプルなプーリング⼿法を提案し,ad hocに解決(multi-task loss)
3. Regions of Interest (RoI) pooling layer
- SPPよりもシンプルな可変プーリング⼿法
- feature map上に矩形を投影し,max poolingすることで固定⻑に変形
4. クラス識別・バウンディングボックス回帰
- RoI poolingした特徴を並列に2つの全結合層に⼊⼒
- Softmaxでクラス識別,詳細なバウンディングボックス回帰
l multi-task loss
- クラス識別誤差とバウンディングボックス回帰誤差を加算
- 同時に学習し,ad hocを解決
13.
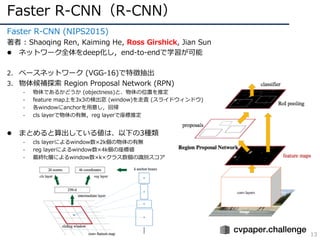
Faster R-CNN(R-CNN)
13
Faster R-CNN(NIPS2015)
著者 : Shaoqing Ren, Kaiming He, Ross Girshick, Jian Sun
l ネットワーク全体をdeep化し,end-to-endで学習が可能
2. ベースネットワーク (VGG-16)で特徴抽出
3. 物体候補探索 Region Proposal Network (RPN)
- 物体であるかどうか (objectness)と、物体の位置を推定
- feature map上を3x3の検出窓 (window)を⾛査 (スライドウィンドウ)
- 各windowにanchorを⽤意し,回帰
- cls layerで物体の有無,reg layerで座標推定
l まとめると算出している値は、以下の3種類
- cls layerによるwindow数×2k個の物体の有無
- reg layerによるwindow数×4k個の座標値
- 最終fc層によるwindow数×k×クラス数個の識別スコア
14.
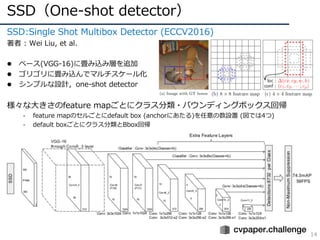
SSD(One-shot detector)
14
SSD:Single ShotMultibox Detector (ECCV2016)
著者 : Wei Liu, et al.
l ベース(VGG-16)に畳み込み層を追加
l ゴリゴリに畳み込んでマルチスケール化
l シンプルな設計,one-shot detector
様々な⼤きさのfeature mapごとにクラス分類・バウンディングボックス回帰
- feature mapのセルごとにdefault box (anchorにあたる)を任意の数設置 (図では4つ)
- default boxごとにクラス分類とBbox回帰
15.
YOLO(One-shot detector)
15
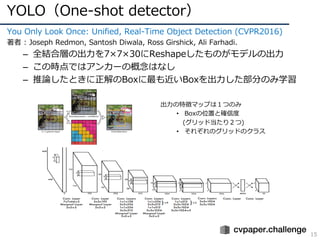
You OnlyLook Once: Unified, Real-Time Object Detection (CVPR2016)
著者 : Joseph Redmon, Santosh Diwala, Ross Girshick, Ali Farhadi.
– 全結合層の出⼒を7×7×30にReshapeしたものがモデルの出⼒
– この時点ではアンカーの概念はなし
– 推論したときに正解のBoxに最も近いBoxを出⼒した部分のみ学習
出⼒の特徴マップは1つのみ
• Boxの位置と確信度
(グリッド当たり2つ)
• それぞれのグリッドのクラス
16.
YOLOv2(One-shot detector)
16
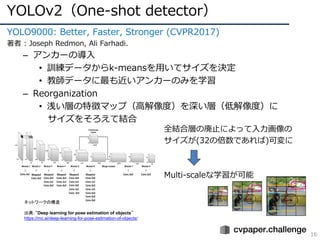
YOLO9000: Better,Faster, Stronger (CVPR2017)
著者 : Joseph Redmon, Ali Farhadi.
– アンカーの導⼊
• 訓練データからk-meansを⽤いてサイズを決定
• 教師データに最も近いアンカーのみを学習
– Reorganization
• 浅い層の特徴マップ(⾼解像度)を深い層(低解像度)に
サイズをそろえて結合
全結合層の廃⽌によって⼊⼒画像の
サイズが(32の倍数であれば)可変に
Multi-scaleな学習が可能
ネットワークの構造
出典:“Deep learning for pose estimation of objects”
https://mc.ai/deep-learning-for-pose-estimation-of-objects/
17.
YOLOv3(One-shot detector)
17
YOLOv3: AnIncremental Improvement
著者 : Joseph Redmon, Ali Farhadi.
– より深いベースネット(Darknet-19→Darknet-53)
– サイズの異なる3つの特徴マップが出⼒
• 各特徴マップに3つのアンカー
• Deconvolutionにより⼩さい物体の検出は深い層が担当
– Softmaxの代わりにsigmoidを使⽤
One-shot系で精度⾯SOTAのRetinaNetに
匹敵する精度で、より⾼速な検出の達成
(Darknet-53の影響が強そう?)
出典:“What’s new in YOLO v3?”
https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b
最近のSOTA(Latest Algorithm)
20
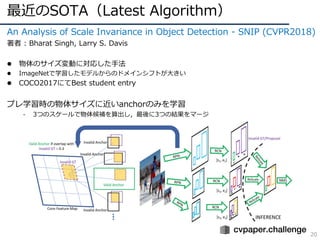
An Analysisof Scale Invariance in Object Detection - SNIP (CVPR2018)
著者 : Bharat Singh, Larry S. Davis
l 物体のサイズ変動に対応した⼿法
l ImageNetで学習したモデルからのドメインシフトが⼤きい
l COCO2017にてBest student entry
プレ学習時の物体サイズに近いanchorのみを学習
- 3つのスケールで物体候補を算出し,最後に3つの結果をマージ
21.
最近のSOTA(Latest Algorithm)
21
SNIPER: EfficientMulti-Scale Training (NeurIPS 2018)
著者 : Bharat Singh, Mahyar Najibi, Larry S. Davis
l より効率的なマルチスケール学習
l ピクセル処理ではなく,チップ周辺のコンテキスト領域を学習
l ⽣成するチップ数は画像の複雑さに応じて変化
コンテキストに基づいたチップのサンプリング
- 画像中の物体の存在の基づいてチップ(コンテキスト領域)を⽣成
- チップからバウンディングボックスを推定
22.
最近のSOTA(Latest Algorithm)
22
M2Det: ASingle-Shot Object Detector based on Multi-Level Feature
Pyramid Network (AAAI 2019)
著者 : Qijie Zhao, Tao Sheng, Yongtao Wang, Zhi Tang, Ying Chen, Ling Cai, Haibin Ling
l ダウンサンプリングとアップサンプリングを何度も繰り返す
l 処理速度は出ないが,2019年2⽉現在でSOTA
浅い特徴と深い特徴をマージしてマルチスケール化
- アップサンプリング時のfeature mapを同じサイズ同⼠で結合
- 結合したfeature mapから物体検出
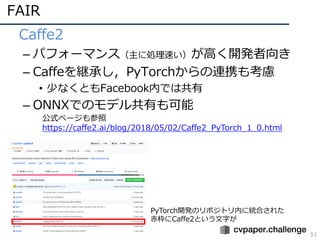
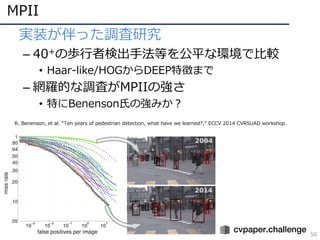
MPII
56
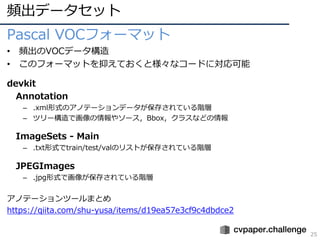
• 実装が伴った調査研究
– 40+の歩⾏者検出⼿法等を公平な環境で⽐較
•Haar-like/HOGからDEEP特徴まで
– 網羅的な調査がMPIIの強さ
• 特にBenenson⽒の強みか?
R. Benenson, et al. “Ten years of pedestrian detection, what have we learned?,” ECCV 2014 CVRSUAD workshop.
57.
MPII
57
• 公開データに対して再アノテーション
– CaltechPedestrianに対しラベルをクリーンに
– Human Baselineも与えた
• Humanのエラー率は5.6%だったことから疑問を持ち,
改良ラベルで⾏ったら同エラー率は0.88%となった
S. Zhang, et al. “How Far are We from Solving Pedestrian
Detection?,” CVPR, 2016.
Caltech Pedestrian Benchmarkに含まれる
ラベル誤り(左)とボックスのズレ(右)
最先端⼿法と⼈間のベースライン⽐較



![物体検知の変遷(ʼ01〜ʼ19)
3
Haar-like [Viola+, CVPR01]
+ AdaBoost
Fast R-CNN [Girshick, ICCV15]
ROI Pooling, Multi-task Loss
Faster R-CNN [Ren+, NIPS15]
RPN
・・・
・・・
R-CNN時代(それ以前は”Hand-crafted” ObjectNess)⾼速化 & ⾼精度化
One-shot Detector時代 兎にも⾓にも(精度を保ちつつ)⾼速化
YOLO(v1)/v2/v3 [Redmon+,
CVPR16/CVPR17/arXiv18]
One-shot detector, w/ full-connect layer
・・・
Latest Algorithm 精度重視,⾼速
Mask R-CNN [He+, ICCV17]
RoI Align, Det+Seg
・・・
bbox+segmentationのラベル
が同時に⼿に⼊るならMask R-
CNNを試そう
41.8AP@MSCOCO
bboxのみが⼿に⼊るな
らRetinaNetを⽤いるの
がベター
40.8AP@MSCOCO
SSD [Liu+, ECCV16]
One-shot detector, Anchor Box
RetinaNet [Lin+, ICCV17]
FocalLoss, PyramidNet
Hand-crafted feature時代 基礎/枠組みの構築
HOG [Dalal+, CVPR05]
+ SVM
ICF [Dollár+, BMVC09]
+ Soft-cascade
DPM [Felzenszwalb+, TPAMI12]
+ Latent SVM
・・・](https://image.slidesharecdn.com/190226objectdetectionfinalize-190225110609/85/Meta-Study-Group-3-320.jpg)


































![FAIR
46
• FAIRのデータ基盤
– もちろんSNSとしてのFacebook!
– Instagram買収(2012年4⽉)
– SNSを⽤いた弱教師によるPre-trainの実⾏(下図)
• Hashtagでラベル付/スケール増加
• 35億枚の画像により特徴表現学習
[Mahajan+, ECCV18]
FBはSNSのHashtagでラベル付けなし,弱教師付きの3.5B
枚画像DB構築](https://image.slidesharecdn.com/190226objectdetectionfinalize-190225110609/85/Meta-Study-Group-46-320.jpg)
























![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会] Residual Attention Network for Image Classification](https://cdn.slidesharecdn.com/ss_thumbnails/residualattentionnetworkforimageclassification-170907072057-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)




![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]GLIDE: Guided Language to Image Diffusion for Generation and Editing](https://cdn.slidesharecdn.com/ss_thumbnails/glide2-220107030326-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]YOLOv4: Optimal Speed and Accuracy of Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/200515dlseminar-200515082345-thumbnail.jpg?width=640&height=640&fit=bounds)