Download to read offline


















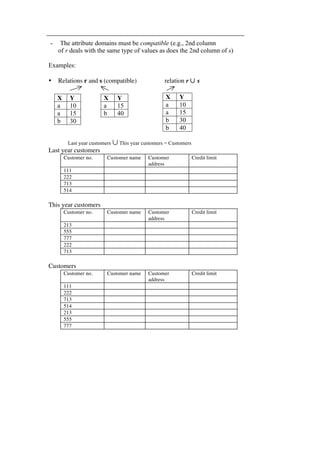






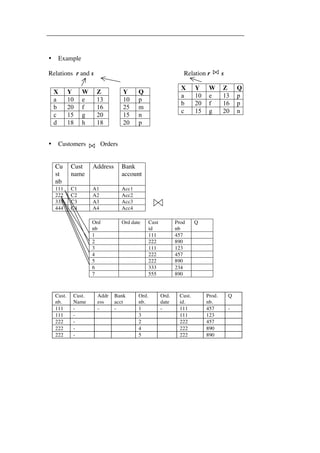


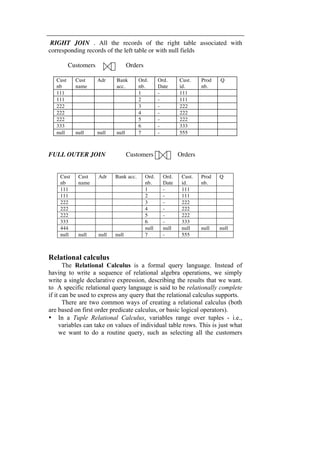




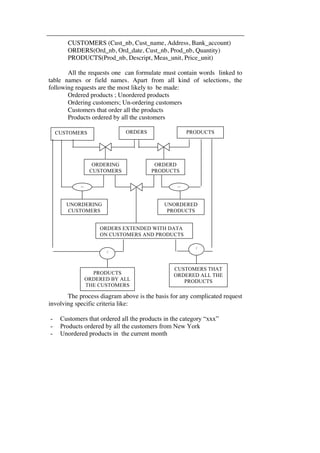



- A data model is an abstraction that represents real-world objects and their relationships to help describe an organization's data requirements. It includes concepts for describing data, relationships between data, and constraints on the data. - Early data models included the hierarchical and network models, which used pointers to represent physical relationships between records. This led to issues like data redundancy and an inability to easily change relationships. - The relational model was developed to address limitations of earlier models by using logical relationships without pointers. It represented a significant improvement over previous approaches.







![Data Models [DATABASE SYSTEMS: Design, Implementation, and Management]](https://cdn.slidesharecdn.com/ss_thumbnails/coronelpptch02-datamodels-190903105908-thumbnail.jpg?width=640&height=640&fit=bounds)



















































































