Downloaded 96 times






















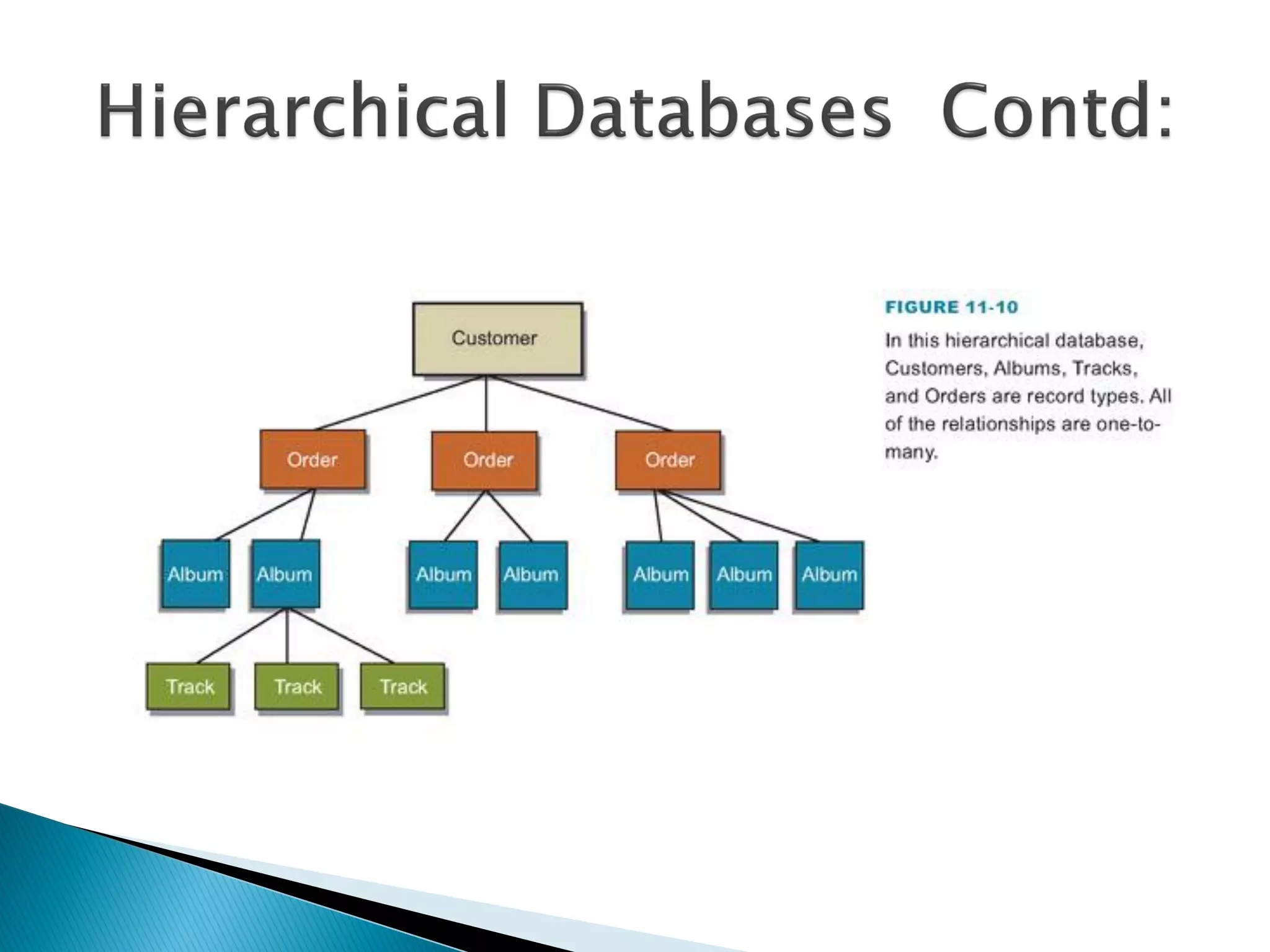










































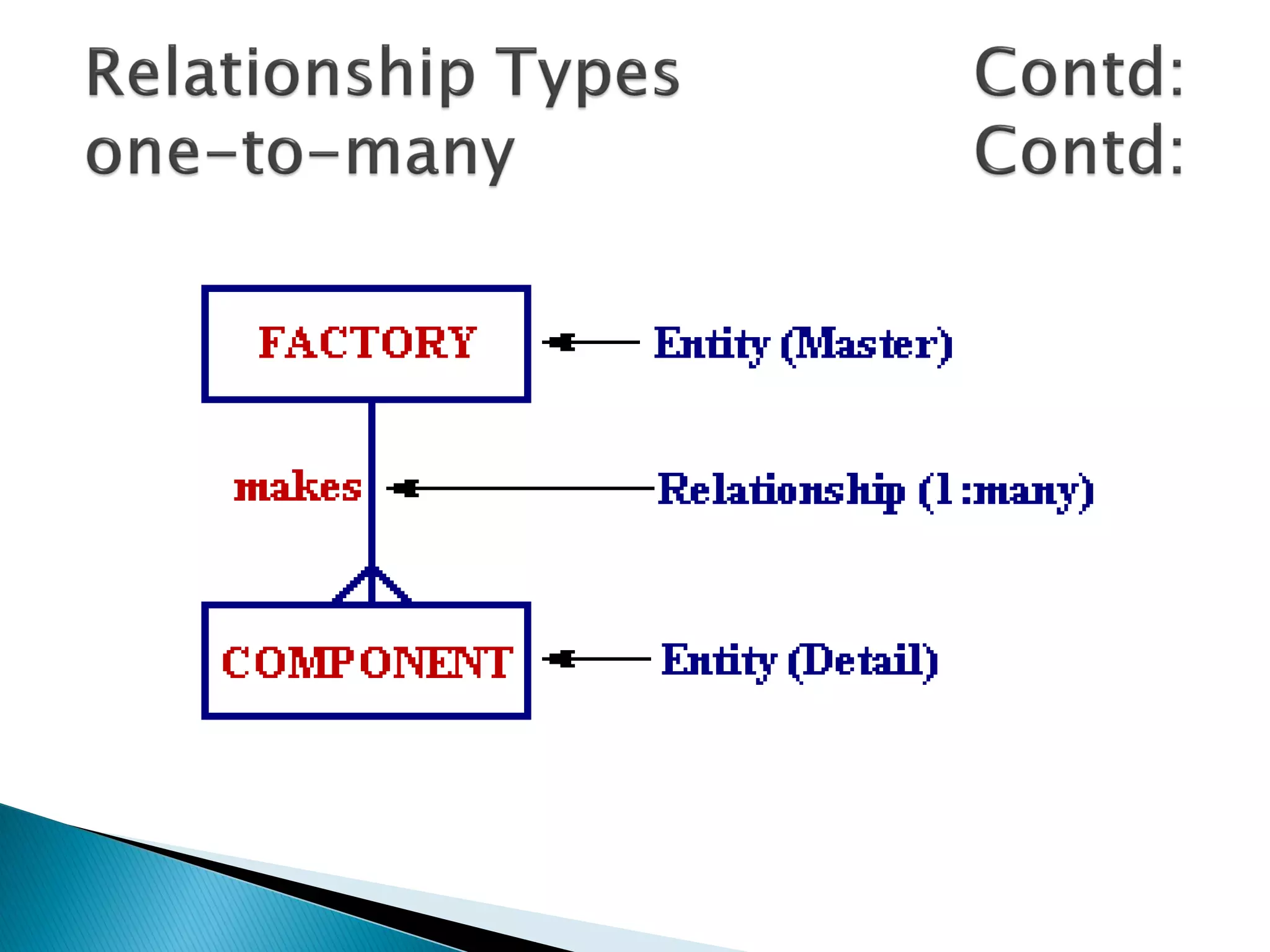

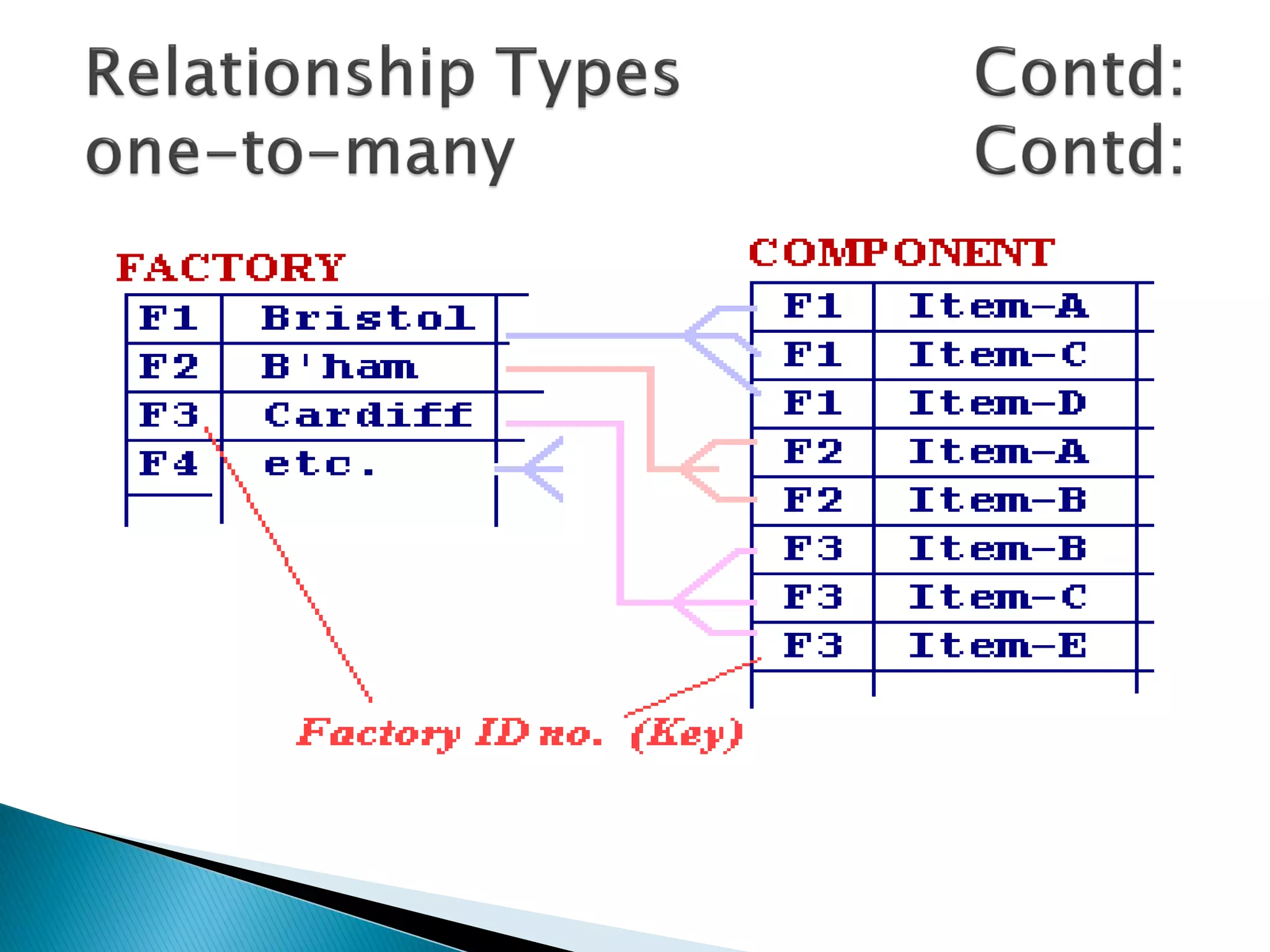



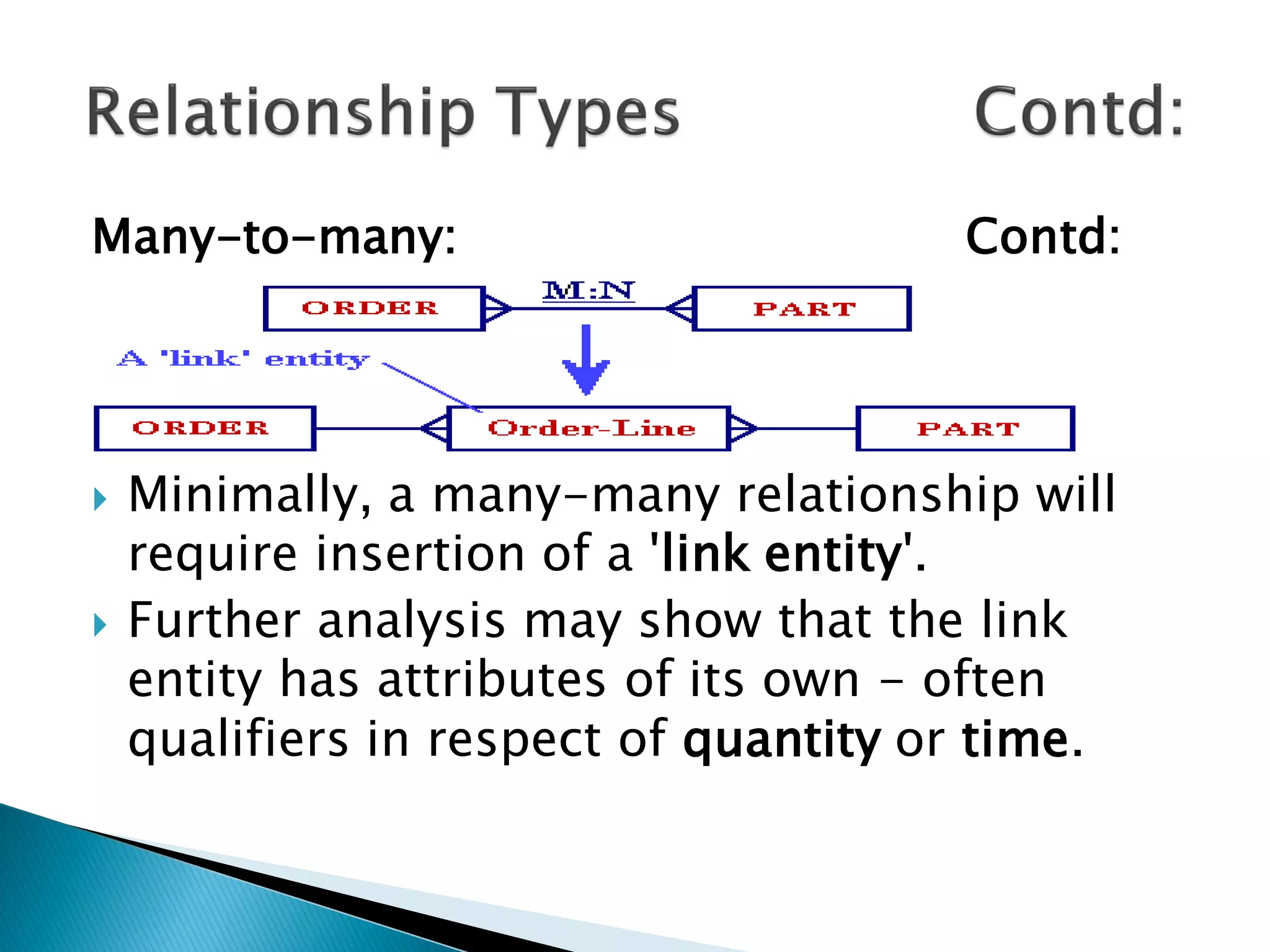
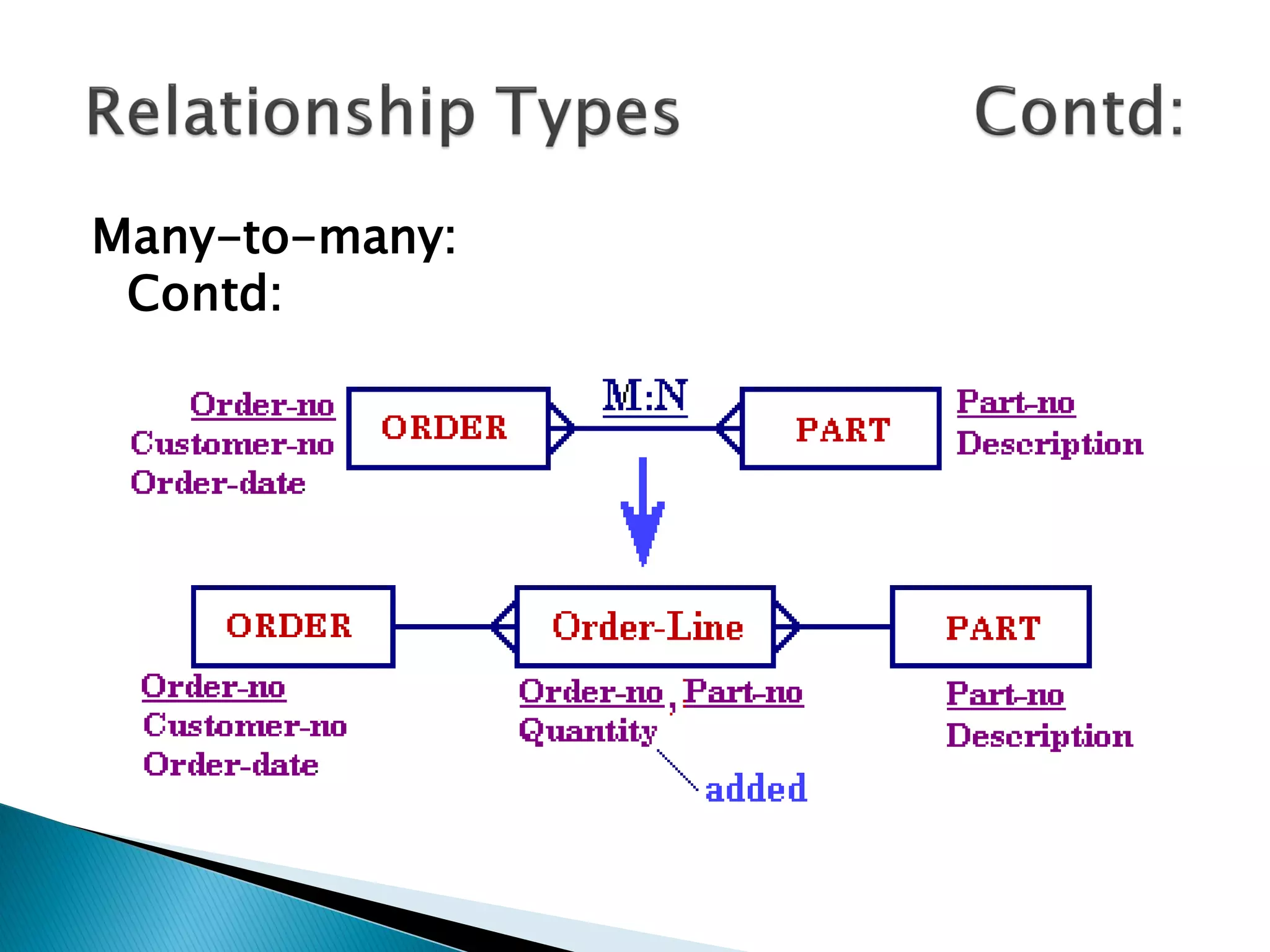





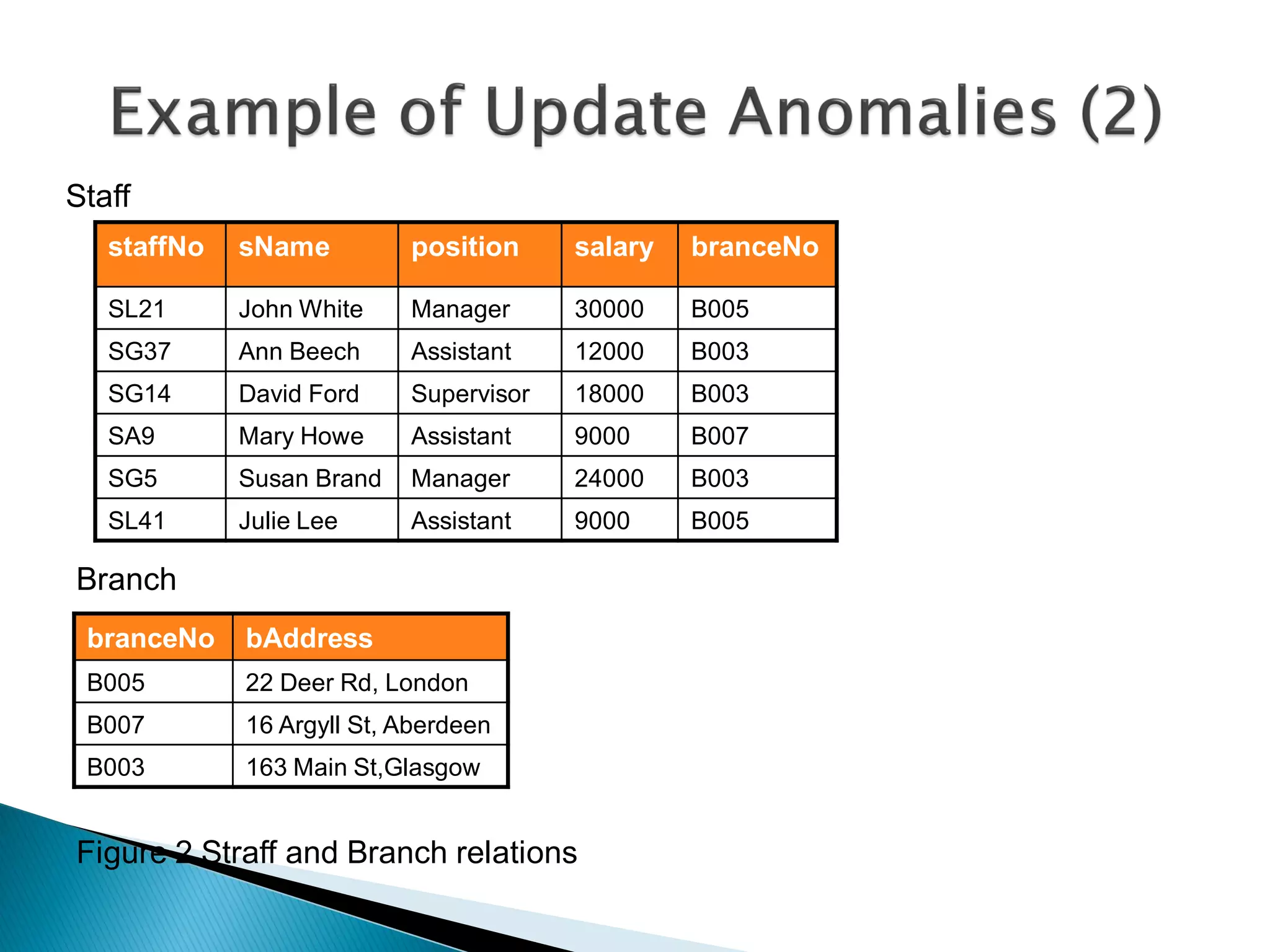
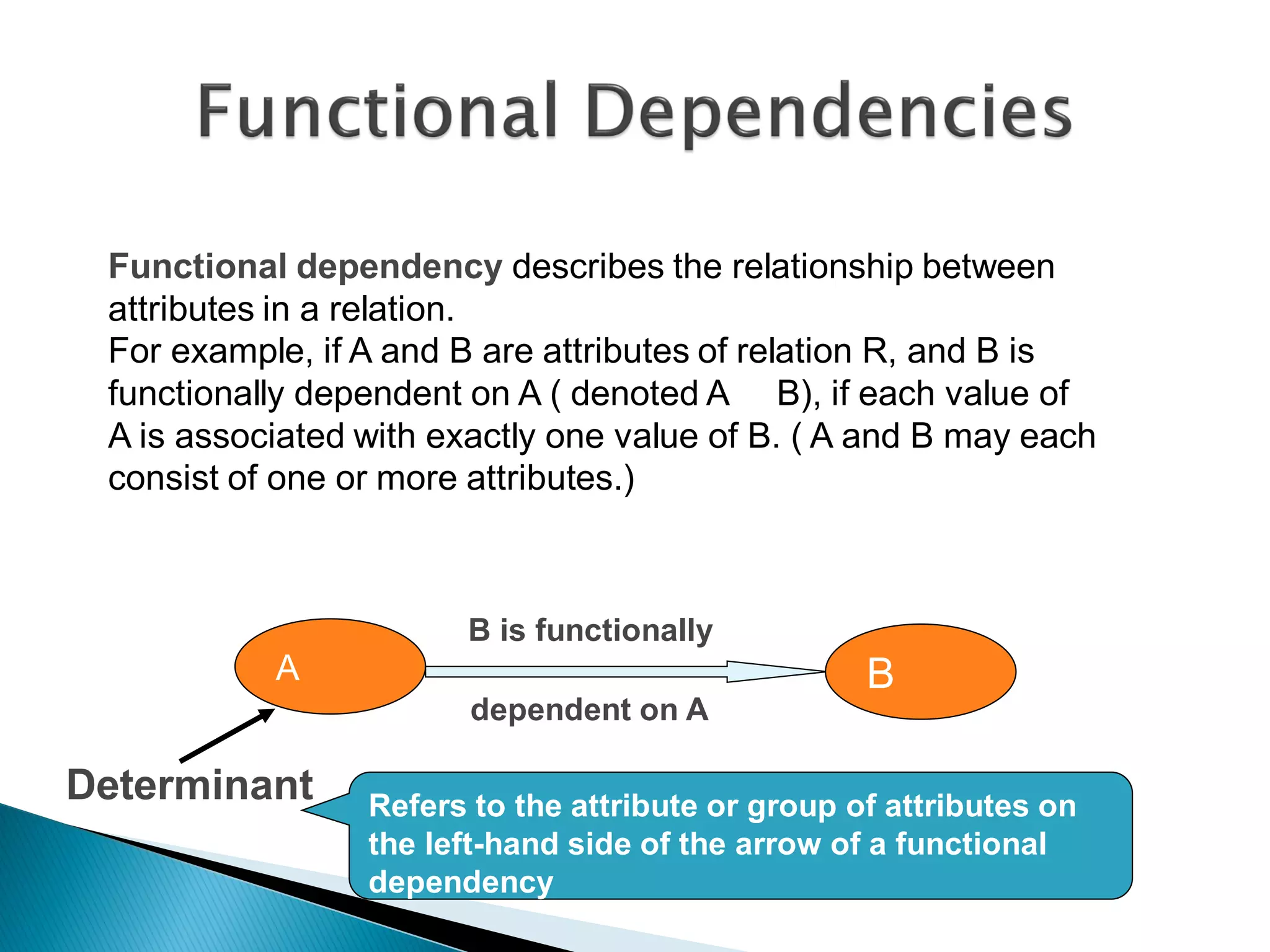


















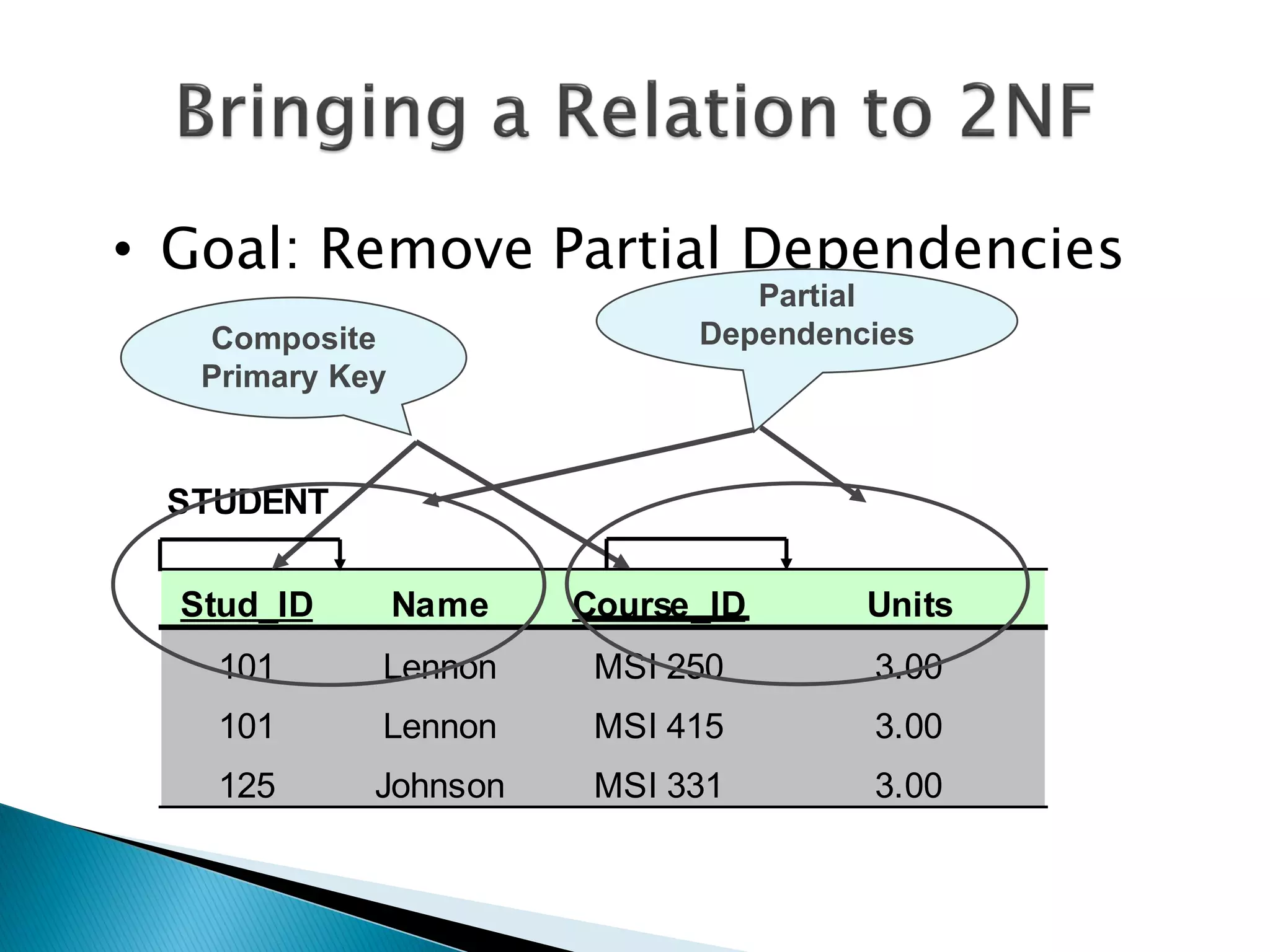

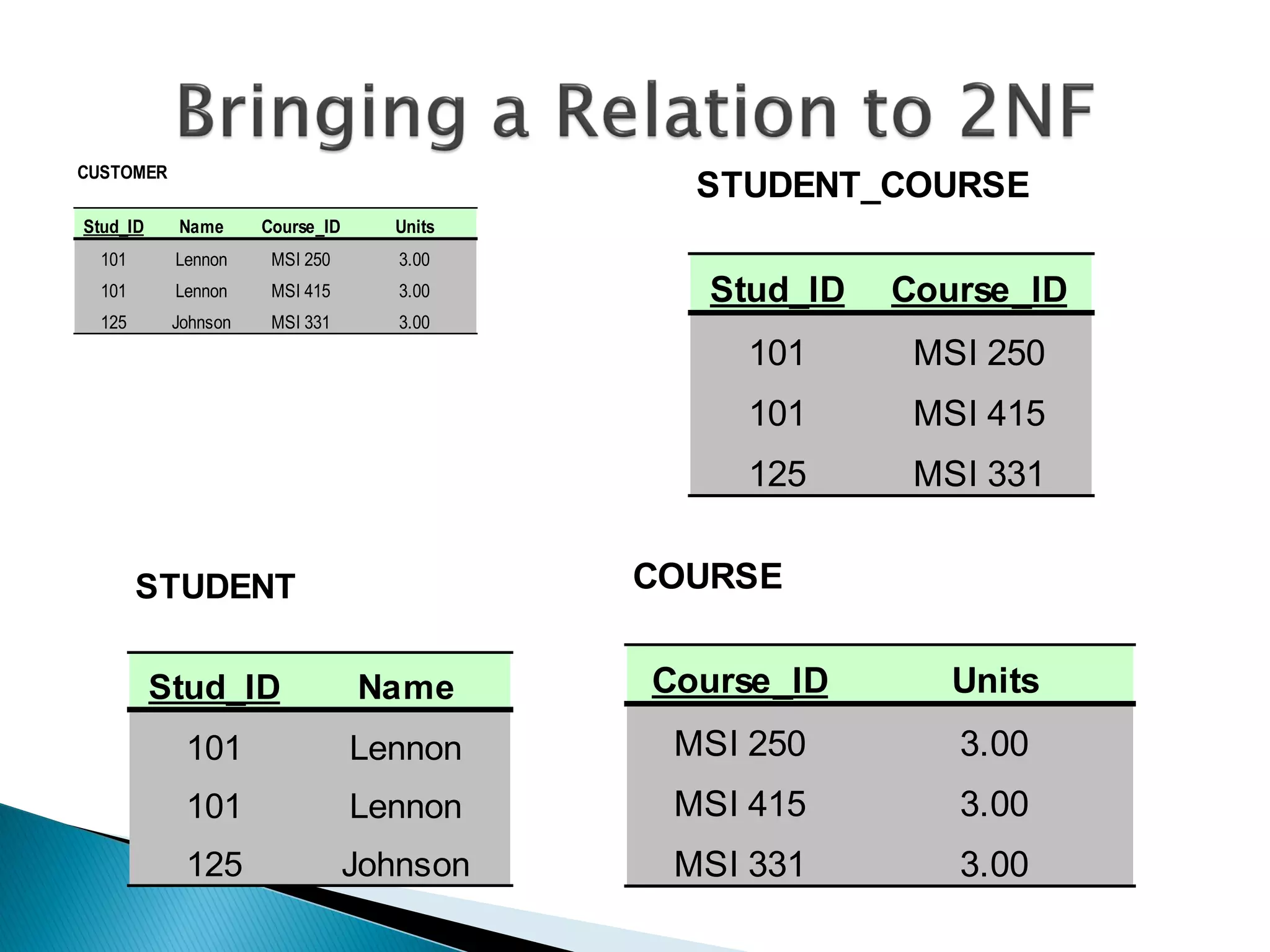
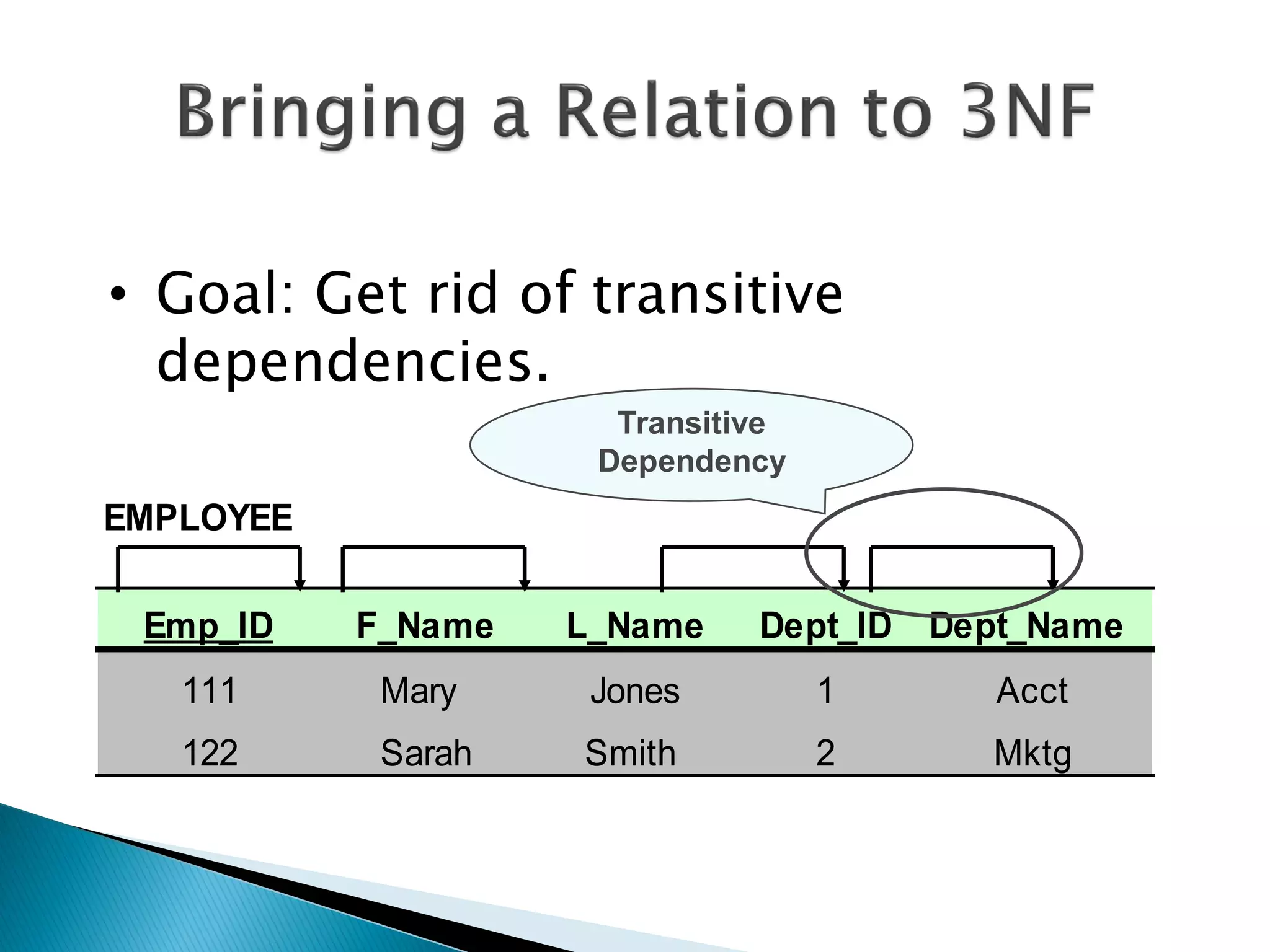
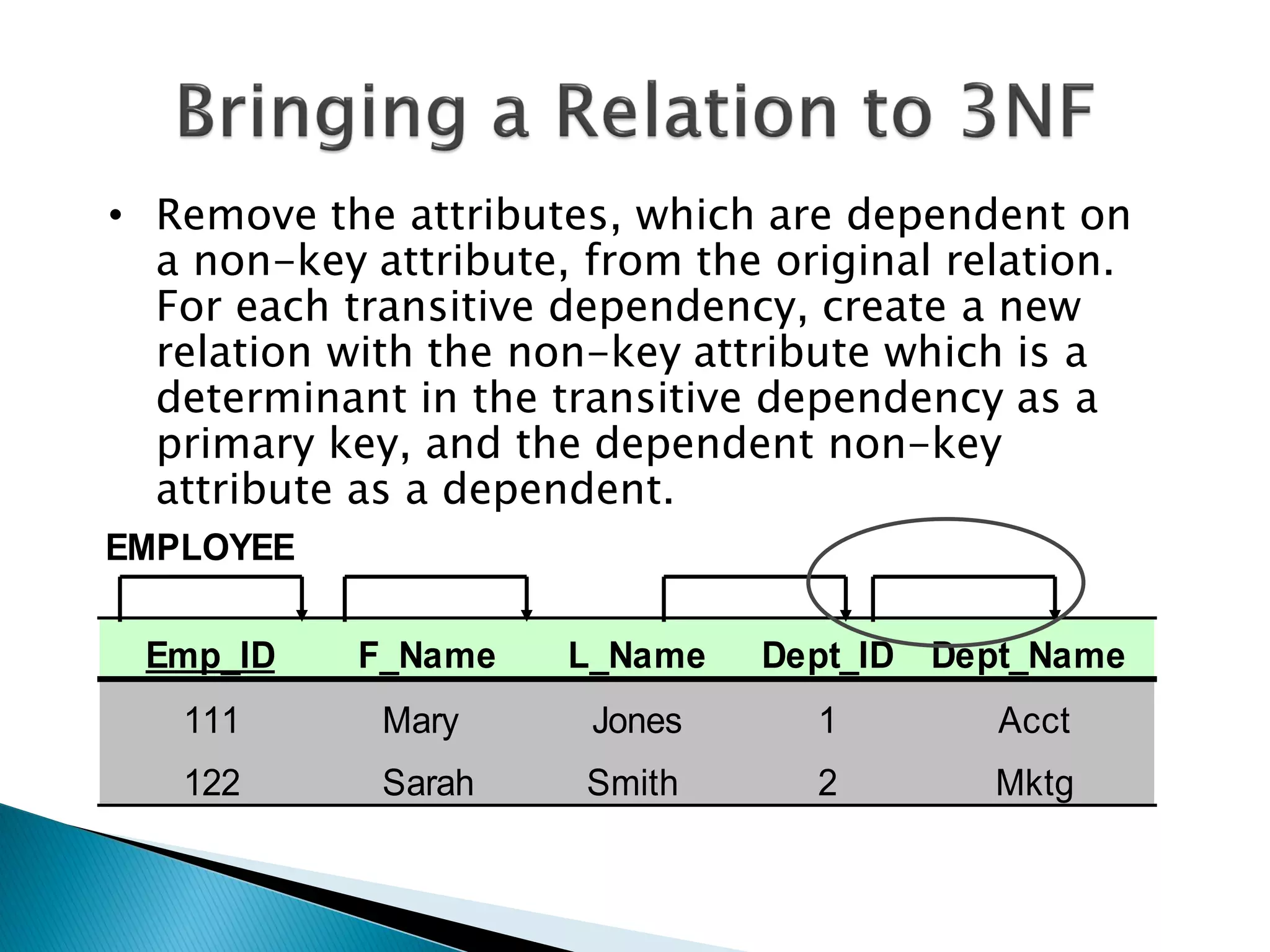
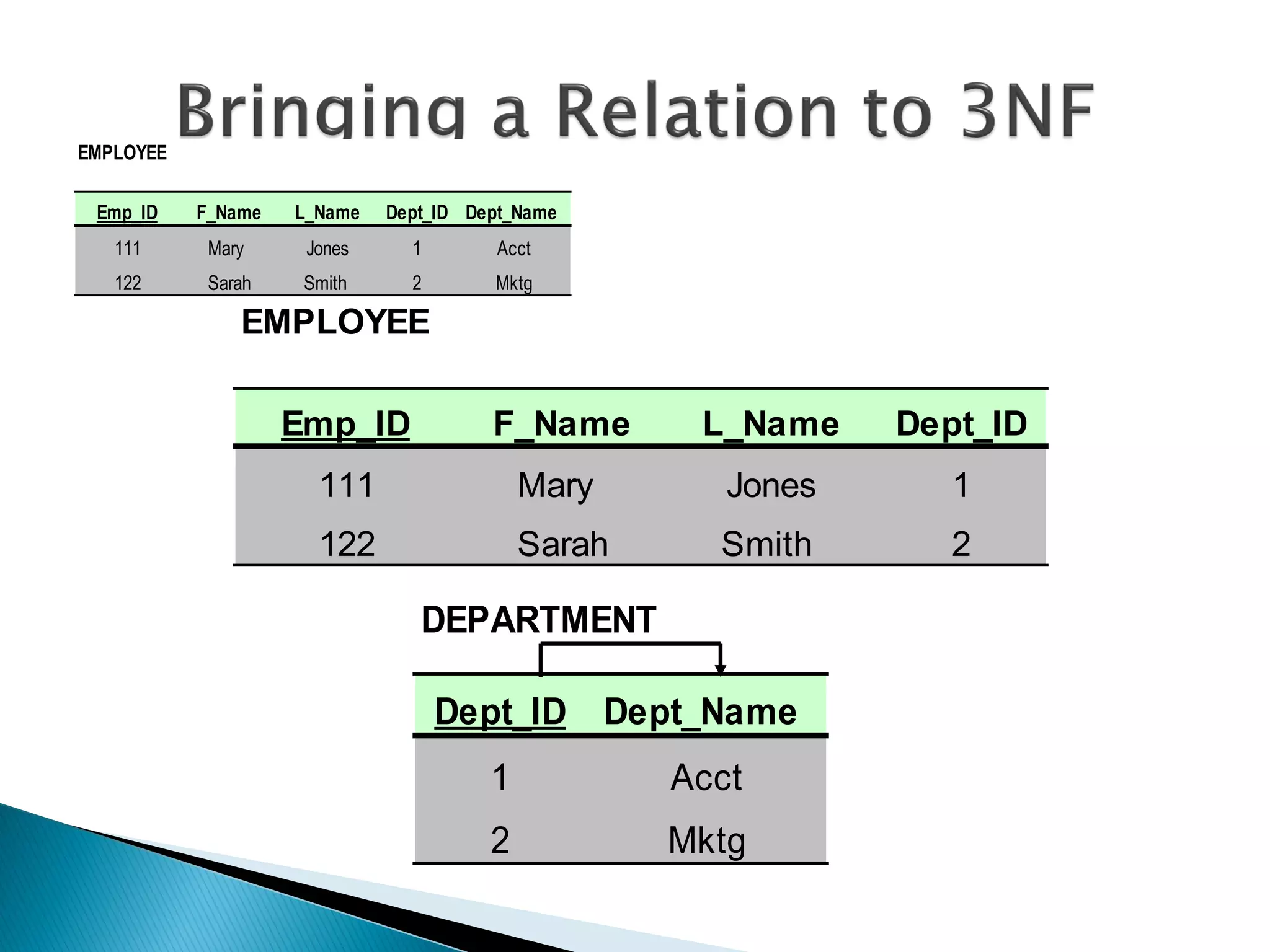
























The document discusses different types of databases including relational databases, analytical databases, operational databases, and object-oriented databases. It describes key characteristics of each type of database such as how they model and store data. Relational databases use tables to store data and link tables using relationships while analytical databases store archived data for analysis and operational databases manage dynamic data. Object-oriented databases integrate object-oriented programming with databases.



































































