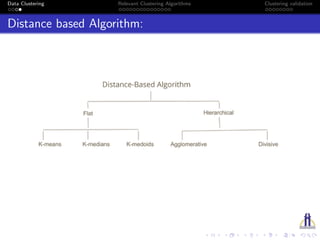
The document discusses data clustering, a method of grouping objects based on similarity, and outlines various clustering algorithms such as K-means and fuzzy C-means. It also addresses feature selection methods, advantages and disadvantages of these algorithms, and clustering validation techniques like the Dunn and Davies-Bouldin indices. Applications of clustering include customer segmentation, data summarization, and social network analysis.




![Data Clustering Relevant Clustering Algorithms Clustering validation
Applications of Clustering:
The applications of clustering are[2]:
1.) Its an intermediate step for other fundamental data mining
problems.
2.) For Collaborative filtering.
3.) Customer Segmentation.
4.) Data summarisation.
5.) Multimedia data analysis.
6.) Biological data analysis.
7.) Social Network Analysis.
etc.](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-4-320.jpg)




![Data Clustering Relevant Clustering Algorithms Clustering validation
K-means algorithm
An unsupervised learning algorithm.
Applies on the m-dimensional hyperspace,for a given data set.
The pre-processing steps are: ’Handling missing values’ and
’Scaling’.
Scaling :
If the attribute is A.and have range [Amin, Amax ].Then, to scale a
value of A as A x, the formula is:
Ax (scaled) = (Ax - Amin)/(Amax - Amin)](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-10-320.jpg)


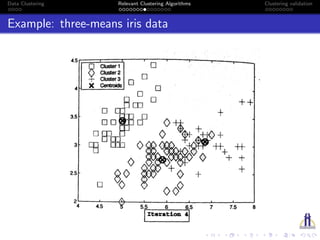



![Data Clustering Relevant Clustering Algorithms Clustering validation
Fuzzy C-means Algorithm
And fill the value of wij in matrix W.
Step 3.) For each cluster,do :
3.i) Calculate the new position(or value) of centroid,ck by :
3.ii) Shift the centroid to the calculated position(or value) in
previous step.
Step 4.) 4.i) compute and update values of elements of W (k) as
W (k+1
4.ii) If ||W (k+1) − W (k)|| > β, then go to Step 2. Else The present
value of W is the resultant partitioning matrix.
where, k is the iteration step.
β is the termination criterion, β ∈ [0, 1].
’W (k)’ is the fuzzy membership matrix in kth iteration.](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-21-320.jpg)

![Data Clustering Relevant Clustering Algorithms Clustering validation
Advantages and disadvantages of K-means and Fuzzy
C-means Algorithms:
The K-means algorithm is fast, robust and easier to
understand. FCM is more complex that K-means.
K-means gives better result when data set are distinct or well
separated from each other, that is for non-overlapping
clusters.FCM is better for overlapping clusters.
The limitations of both is that, the value of K must be known
priorly,
K-mean results in local optima,it is applicable only when
mean is defined, hence fails for categorical data and is unable
to handle noisy data and outliers[1]
The time complexity of the K-Means algorithm is O(tkdn) and
the time complexity of FCM algorithm is O(ndk2t) where, n
is number of data objects, k is number clusters, d is dimension
of each object and t is iterations. Normally, k, t, d << n[5]](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-23-320.jpg)


![Data Clustering Relevant Clustering Algorithms Clustering validation
Cluster validation
Evaluation of clustering results sometimes is referred to as cluster
validation.[7]
Measures are used to compare the quality of different clustering
algorithms.
The measures are classified as:
Internal Indices.
External Indices.](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-26-320.jpg)


![Data Clustering Relevant Clustering Algorithms Clustering validation
Dunn and Dunn index:
It is proposed by [3].
Identifies clusters which are well separated and compact.
Goal is[6]:
to maximize the inter-cluster distance.
minimizing the intra-cluster distance.
The Dunn index for k clusters is defined by:](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-29-320.jpg)



![Data Clustering Relevant Clustering Algorithms Clustering validation
Davies Bouldin index:
The Davies Bouldin index [8] is based on similarity measure of
clusters (Rij ).
Dispersion(si ) of a cluster and dissimilarity between
clusters(dij ) are used to compute the Davies-Bouldin(DB)
index.
Similarity measure of clusters, (Rij ) must satisfy the
conditions:
Rij >= 0
Rij = Rji
if si = 0 and sj = 0 then Rij = 0
if sj >sk and dij = dik then Rij >Rik
if sj = sk and dij <dik then Rij >Rik](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-33-320.jpg)
![Data Clustering Relevant Clustering Algorithms Clustering validation
Davies Bouldin index:
Usually Rij is defined in the following way[4]:
Then the Davies Bouldin index is defined as:
where,](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-34-320.jpg)

![Appendix
References I
[1] site/dataclusteringalgorithms/k-means-clustering-algorithm.
[2] Aggrawal, C. C., and Reddy, C. K.
Data Clustering.
CRC Press.
[3] Dunn, J.
Well separated clusters and optimal fuzzy partitions.
Journal of Cybernetics 4 (1974), 95104.
[4] Ferenc Kovcs, Csaba Legny, A. B.
Cluster validity measurement techniques.](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-36-320.jpg)
![Appendix
References II
[5] Ghosh, S., and Dubey, S. K.
Comparative analysis of k-means and fuzzy c-means
algorithms.
((IJACSA) International Journal of Advanced Computer
Science and Applications 4(4) (2013).
[6] Sandro Saitta, B. R., and Smith, I. F.
A bounded index for cluster validity.
[7] wikipedia.
https://en.wikipedia.org/wiki/cluster analysis#evaluation and assessm](https://image.slidesharecdn.com/dataclusteringinternshippresentation-160629114759/85/Data-clustering-37-320.jpg)














































































