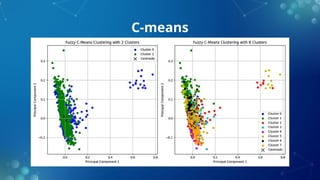
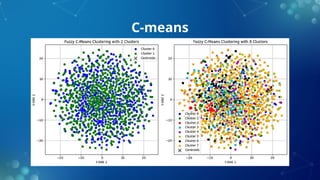
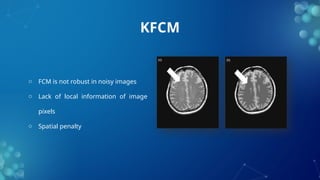
The document discusses fuzzy clustering, a method that allows data points to belong to multiple clusters with varying degrees of membership, contrasting it with traditional clustering methods like k-means. It outlines the benefits of fuzzy clustering, including increased accuracy and flexibility in data analysis, and describes algorithms such as fuzzy c-means, which enhances clustering precision for complex datasets. Additionally, it covers applications of fuzzy clustering in fields like medical imaging and bioinformatics, as well as the pros and cons of the method.








































































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)

