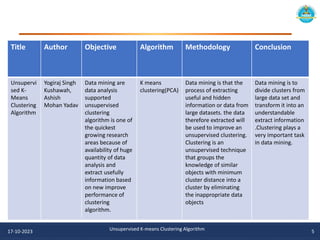
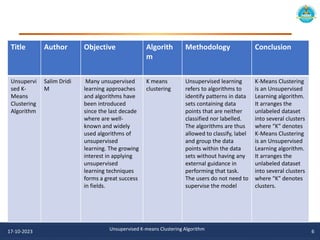
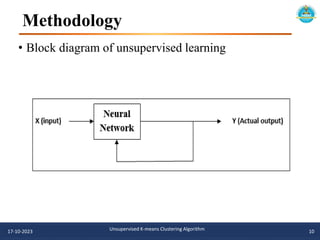
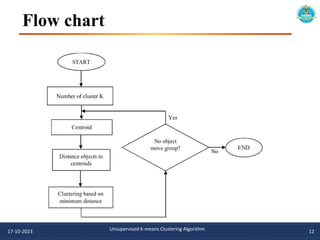
The document describes an unsupervised k-means clustering algorithm project. It includes an introduction to k-means clustering, a literature review of previous related work, and the problem statement, aim, and objectives of proposing a novel unsupervised k-means algorithm. The methodology section outlines the u-k-means clustering algorithm and flowchart. Software implementations in Python are provided using scikit-learn and matplotlib to visualize the clusters. The algorithm is tested on the iris dataset to find the best model parameters.









![def fit(self, X):
n = X.shape[0]
C = X[np.random.choice(n, self.n_clusters), :]
U = np.random.rand(n, self.n_clusters)
U = U / np.sum(U, axis=1, keepdims=True)
for i in range(self.max_iter):
U_old = U.copy()
for j in range(self.n_clusters):
C[j, :] = np.sum(U[:, j].reshape(-1, 1) * X, axis=0) / np.sum(U[:, j])
dist = np.linalg.norm(X[:, :, np.newaxis] - C.T[np.newaxis, :, :], axis=1)
U = 1 / (dist ** (2 / (self.fuzziness - 1)))
U = U / np.sum(U, axis=1, keepdims=True)
if np.allclose(U, U_old):
break
17-10-2023 Unsupervised K-means Clustering Algorithm 14](https://image.slidesharecdn.com/presentationtemplatetyaimlie2project1-231017180927-7d63323b/85/Presentation-Template__TY_AIML_IE2_Project-1-pptx-14-320.jpg)

![or fuzziness in [1.5, 2, 2.5]:
for max_iter in [50, 100, 200]:
model = UKMeans(n_clusters=n_clusters, fuzziness=fuzziness,
max_iter=max_iter)
model.fit(X)
accuracy = np.mean(model.labels_ == y)
if accuracy > best_accuracy:
best_accuracy = accuracy
best_model = model
# Print the best accuracy and corresponding parameters
print(f"Best accuracy: {best_accuracy}")
print(f"Number of clusters: {best_model.n_clusters}")
print(f"Fuzziness: {best_model.fuzziness}")
print(f"Maximum number of iterations: {best_model.max_iter}"
17-10-2023 Unsupervised K-means Clustering Algorithm 16](https://image.slidesharecdn.com/presentationtemplatetyaimlie2project1-231017180927-7d63323b/85/Presentation-Template__TY_AIML_IE2_Project-1-pptx-16-320.jpg)
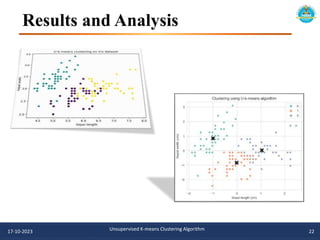
![# Visualize the clusters using scatter plot
sns.set_style("whitegrid")
sns.scatterplot(x=X[:, 0], y=X[:, 1], hue=best_model.labels_, palette="Set2")
sns.scatterplot(x=best_model.centroids_[:, 0], y=best_model.centroids_[:, 1], color="black", marker="X",
s=200, legend=False)
plt.title("Clustering using U-k-means algorithm")
plt.xlabel("Sepal length (cm)")
plt.ylabel("Sepal width (cm)")
plt.show()
# Visualize the distribution of samples across clusters using bar graph
sns.set_style("whitegrid")
sns.countplot(x=best_model.labels_, palette="Set2")
plt.title("Distribution of samples across clusters")
plt.xlabel("Cluster")
plt.ylabel("Number of samples")
plt.show()
17-10-2023 Unsupervised K-means Clustering Algorithm 17](https://image.slidesharecdn.com/presentationtemplatetyaimlie2project1-231017180927-7d63323b/85/Presentation-Template__TY_AIML_IE2_Project-1-pptx-17-320.jpg)




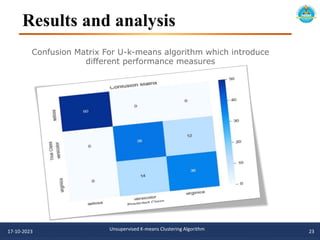

![References
[1] A. K. Jain and R. C. Dubes, Algorithms for Clustering Data, Englewood Cliffs, NJ, USA: Prentice-Hall,
1988.
[2] L. Kaufman and P. J. Rousseeuw, Finding Groups in Data: An Introduction to Cluster Analysis. New
York, NY, USA: Wiley, 1990.
[3] G. J. McLachlan and K. E. Basford, Mixture Models: Inference and Applications to Clustering. New
York, NY, USA: Marcel Dekker, 1988.
[4] A. P. Dempster, N. M. Laird, and D. B. Rubin, ‘‘Maximum likelihood from incomplete data via the EM
algorithm (with discussion),’’ J. Roy. Stat. Soc., Ser. B, Methodol., vol. 39, no. 1, pp. 1–38, 1977.
[5] J. Yu, C. Chaomurilige, and M.-S. Yang, ‘‘On convergence and parameter selection of the EM and DA-
EM algorithms for Gaussian mixtures,’’ Pattern Recognit., vol. 77, pp. 188–203, May 2018.
[6] A. K. Jain, ‘‘Data clustering: 50 years beyond K-means,’’ Pattern Recognit. Lett., vol. 31, no. 8, pp.
651–666, Jun. 2010.
[7] M.-S. Yang, S.-J. Chang-Chien, and Y. Nataliani, ‘‘A fully-unsupervised possibilistic C-Means
clustering algorithm,’’ IEEE Access, vol. 6, pp. 78308–78320, 2018.
[8] J. MacQueen, ‘‘Some methods for classification and analysis of multivariate observations,’’ in Proc. 5th
Berkeley Symp. Math. Statist. Probab., vol. 1, 1967, pp. 281–297.
[9] M. Alhawarat and M. Hegazi, ‘‘Revisiting K-Means and topic modeling, a comparison study to cluster
arabic documents,’’ IEEE Access, vol. 6, pp. 42740–42749, 2018.
17-10-2023 Unsupervised K-means Clustering Algorithm 25](https://image.slidesharecdn.com/presentationtemplatetyaimlie2project1-231017180927-7d63323b/85/Presentation-Template__TY_AIML_IE2_Project-1-pptx-25-320.jpg)
















![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)
































