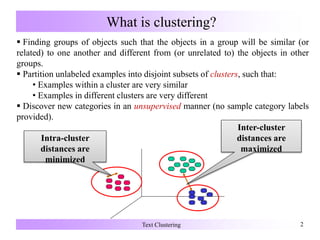
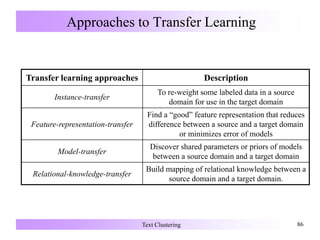
Text clustering involves grouping text documents into clusters such that documents within a cluster are similar to each other and dissimilar to documents in other clusters. Common text clustering methods include bisecting k-means clustering, which recursively partitions clusters, and agglomerative hierarchical clustering, which iteratively merges clusters. Text clustering is used to automatically organize large document collections and improve search by returning related groups of documents.






![Text Clustering 7
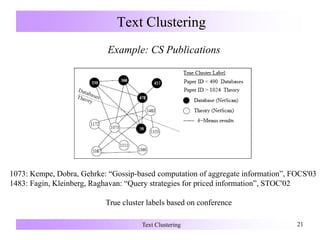
Text Clustering
Bisecting k-means [Steinbach, Karypis & Kumar 2000]
K-means
Bisecting k-means
Partition the database into 2 clusters
Repeat: partition the largest cluster into 2 clusters . . .
Until k clusters have been discovered
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10](https://image.slidesharecdn.com/textclustering-150803041805-lva1-app6891/85/Text-clustering-7-320.jpg)


![Text Clustering 10
Text Clustering
Experimental Comparison
[Steinbach, Karypis & Kumar 2000]
Clustering Quality
Measured as entropy on a prelabeled test data set
Using several text and web data sets
Bisecting k-means outperforms k-means.
Bisecting k-means outperforms agglomerative hierarchical
clustering.
Efficiency
Bisecting k-means is much more efficient than agglomerative
hierarchical clustering.
O(n) vs. O(n2)](https://image.slidesharecdn.com/textclustering-150803041805-lva1-app6891/85/Text-clustering-10-320.jpg)
![Text Clustering 11
Text Clustering
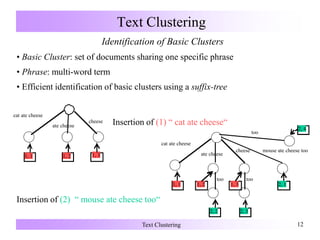
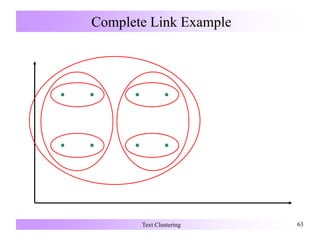
Suffix Tree Clustering
[Zamir & Etzioni 1998]
Forming Clusters
Not by similar feature vectors
But by common terms
Strengths of Suffix Tree Clustering (STC)
Efficiency: runtime O(n) for n text documents
Overlapping clusters
Method
1. Identification of “ basic clusters“
2. Combination of basic clusters](https://image.slidesharecdn.com/textclustering-150803041805-lva1-app6891/85/Text-clustering-11-320.jpg)

![Text Clustering 15
Text Clustering
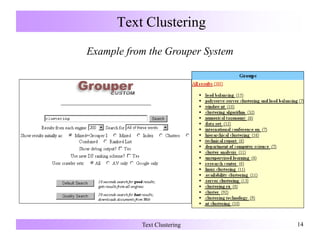
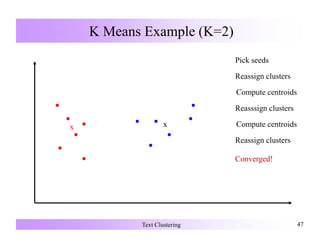
Frequent-Term-Based Clustering
[Beil, Ester & Xu 2002]
• Frequent term set:
description of a cluster
• Set of documents containing
all terms of the frequent term
set: cluster
• Clustering: subset of set of all
frequent term sets covering
the DB with a low mutual
overlap
{} {D1, . . ., D16}
{sun} {fun} {beach}
{D1, D2, D4, D5, {D1, D3, D4, D6, {D2, D7, D8,
D6, D8, D9, D10, D7, D8, D10, D11, D9, D10, D12,
D11, D13, D15} D14, D15, D16} D13,D14, D15}
{sun, fun} {sun, beach} {fun, surf} {beach, surf}
{D1, D4, D6, D8, {D2, D8, D9, . . . . . .
D10, D11, D15} D10, D11, D15}
{sun, fun, surf} {sun, beach, fun}
{D1, D6, D10, D11} {D8, D10, D11, D15}](https://image.slidesharecdn.com/textclustering-150803041805-lva1-app6891/85/Text-clustering-15-320.jpg)


![Text Clustering 18
Text Clustering
Joint Cluster Analysis [Ester, Ge, Gao et al 2006]
Attribute data: intrinsic properties of entities
Relationship data: extrinsic properties of entities
Existing clustering algorithms use either attribute or relationship data
Often: attribute and relationship data somewhat related, but contain
complementary information
Joint cluster analysis of attribute and relationship data
Edges = relationships
2D location = attributes
Informative
Graph](https://image.slidesharecdn.com/textclustering-150803041805-lva1-app6891/85/Text-clustering-18-320.jpg)






























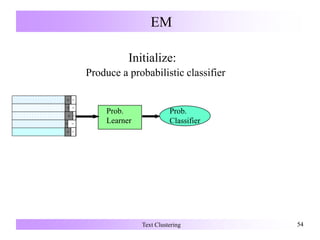
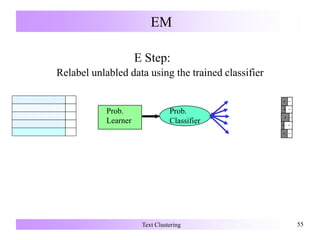
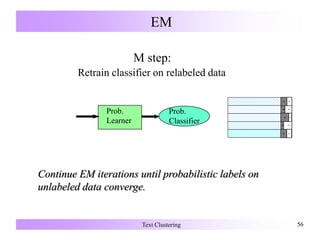




















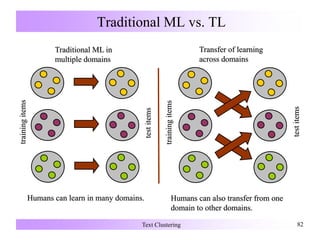
![Search-Based Semi-Supervised Clustering
Alter the clustering algorithm that searches for a good partitioning by:
• Modifying the objective function to give a reward for obeying labels on
the supervised data [Demeriz:ANNIE99].
• Enforcing constraints (must-link, cannot-link) on the labeled data during
clustering [Wagstaff:ICML00, Wagstaff:ICML01].
• Use the labeled data to initialize clusters in an iterative refinement
algorithm (k-Means,) [Basu:ICML02].
Text Clustering 79](https://image.slidesharecdn.com/textclustering-150803041805-lva1-app6891/85/Text-clustering-79-320.jpg)


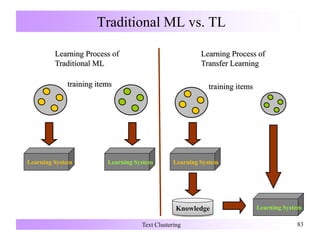

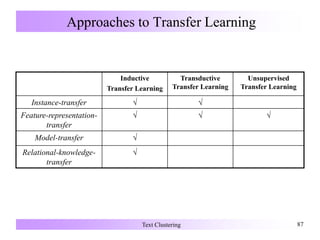
![Unsupervised Transfer Learning
Feature-representation-transfer Approaches
Self-taught Clustering (STC)
[Dai et al. ICML-08]
Text Clustering 88
Input: A lot of unlabeled data in a source domain and a few unlabeled data in
a target domain.
Goal: Clustering the target domain data.
Assumption: The source domain and target domain data share some common
features, which can help clustering in the target domain.
Main Idea: To extend the information theoretic co-clustering algorithm
[Dhillon et al. KDD-03] for transfer learning.](https://image.slidesharecdn.com/textclustering-150803041805-lva1-app6891/85/Text-clustering-88-320.jpg)















































![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)