Downloaded 11 times



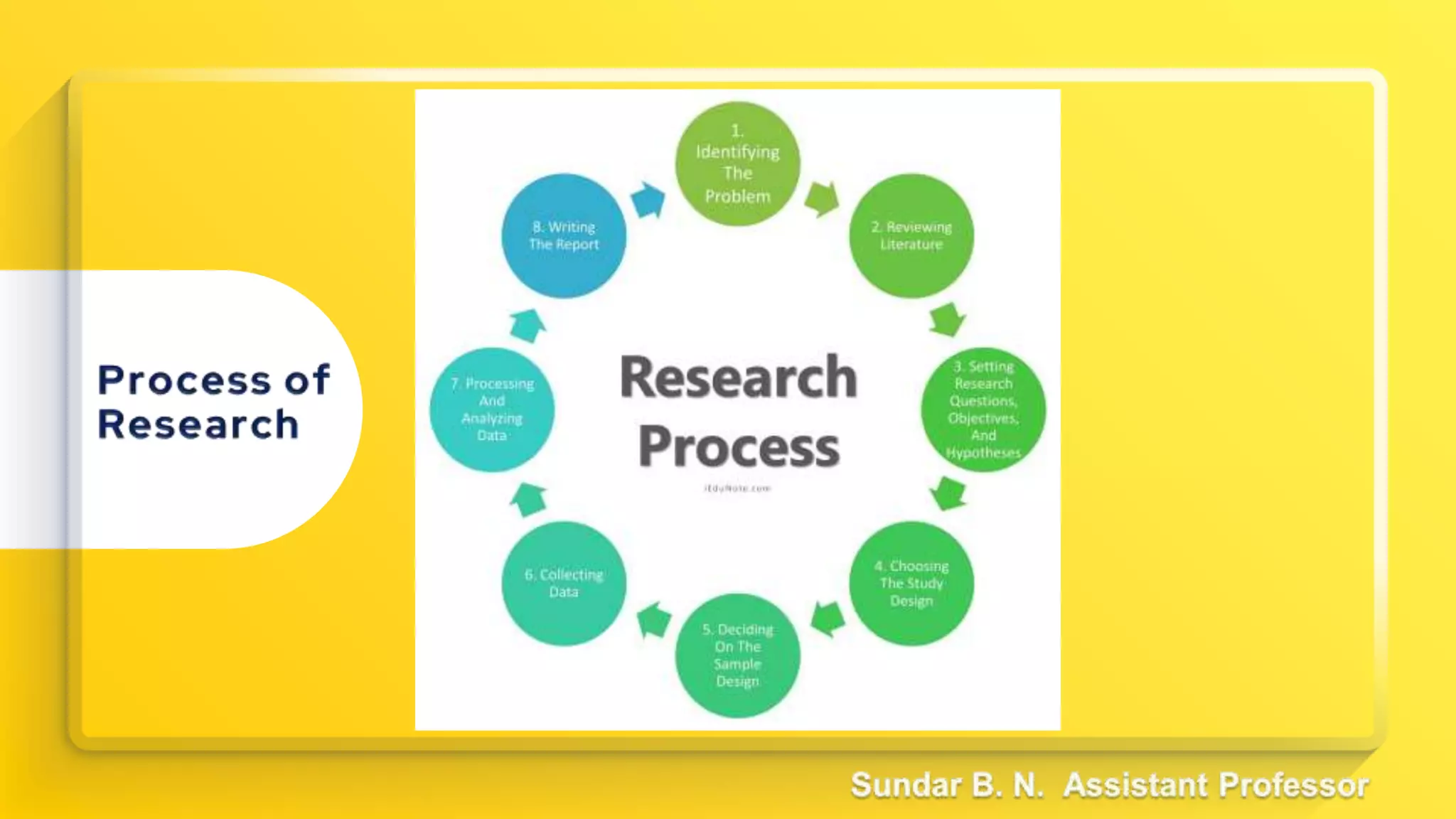





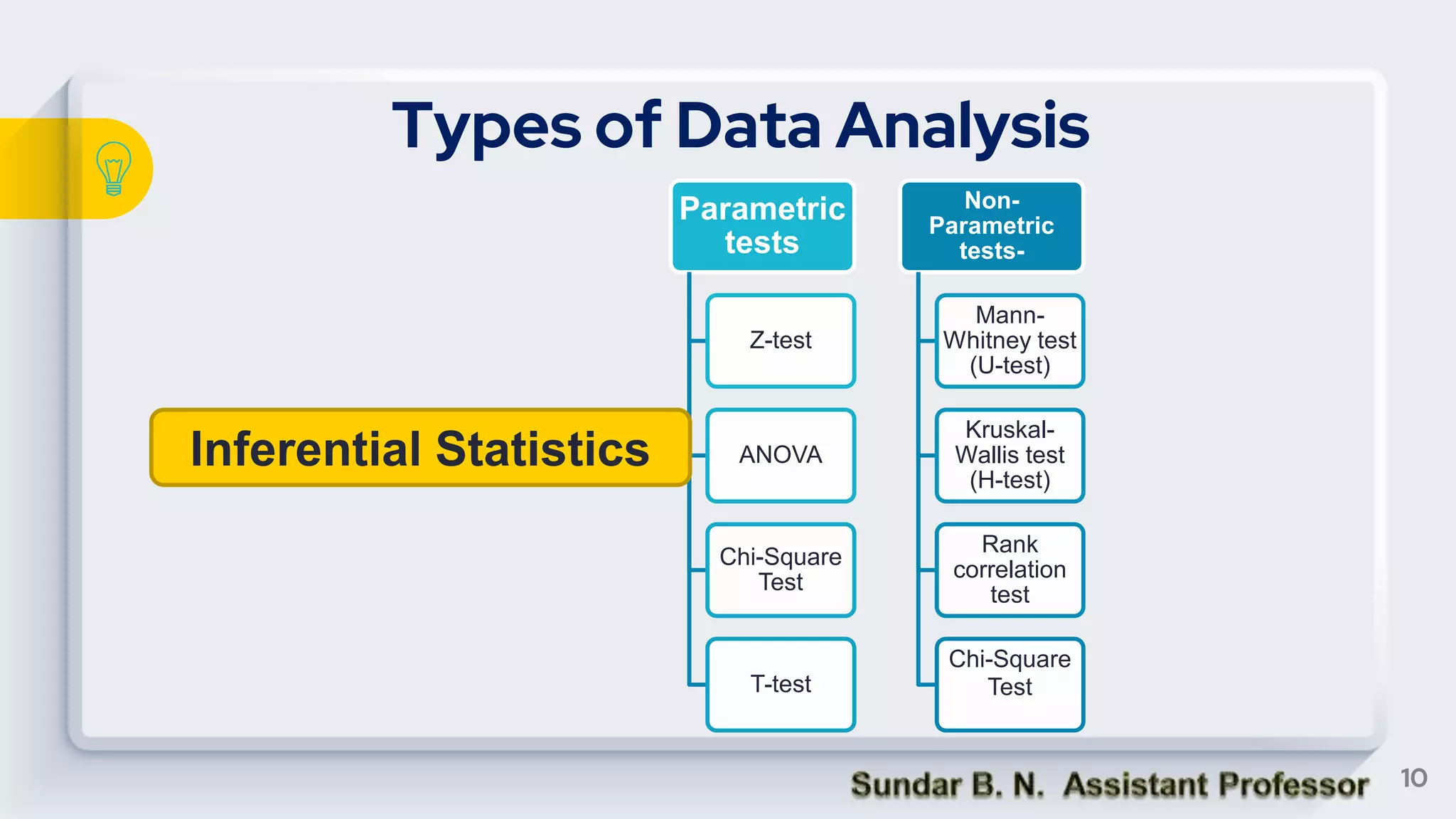























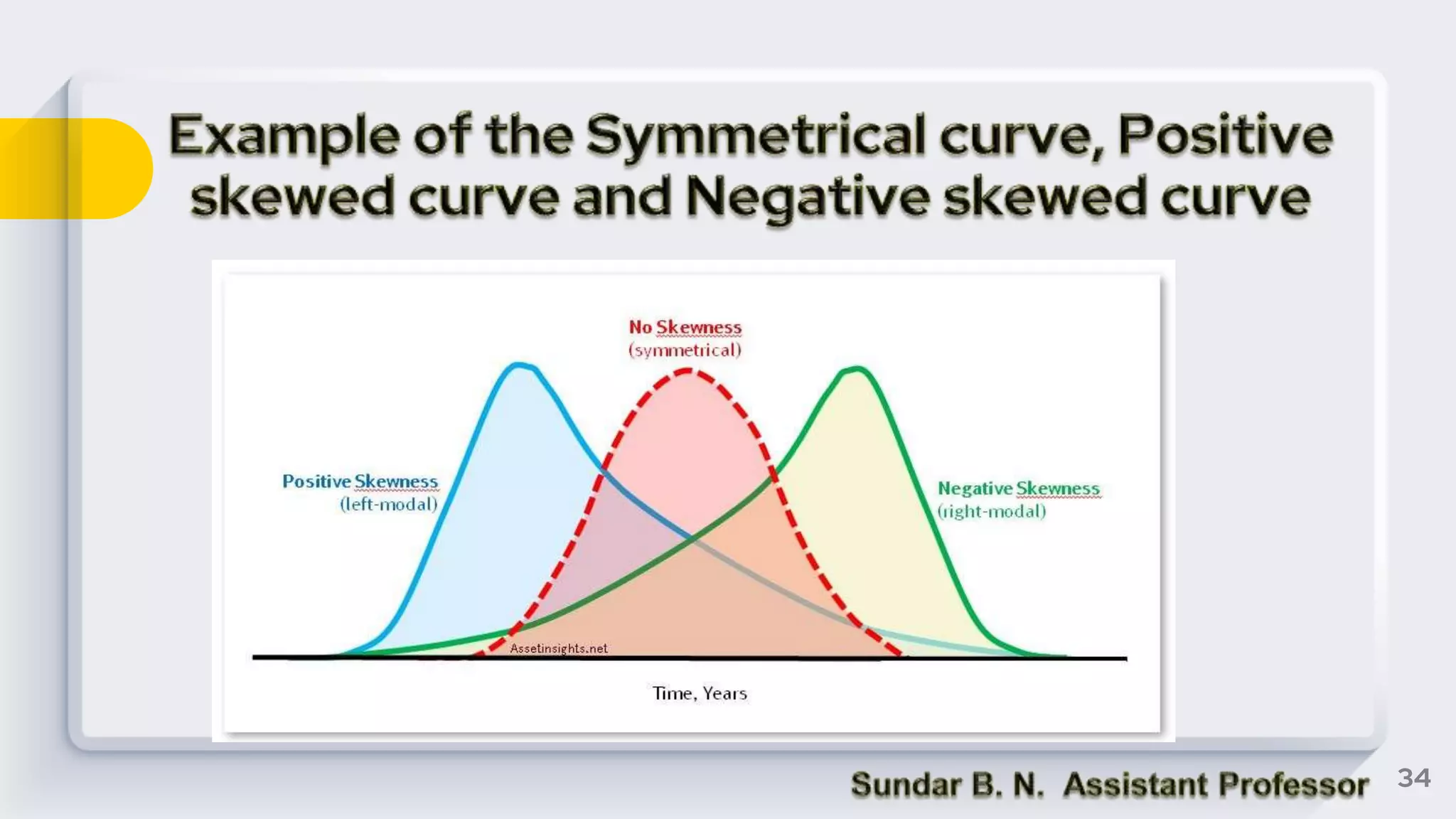



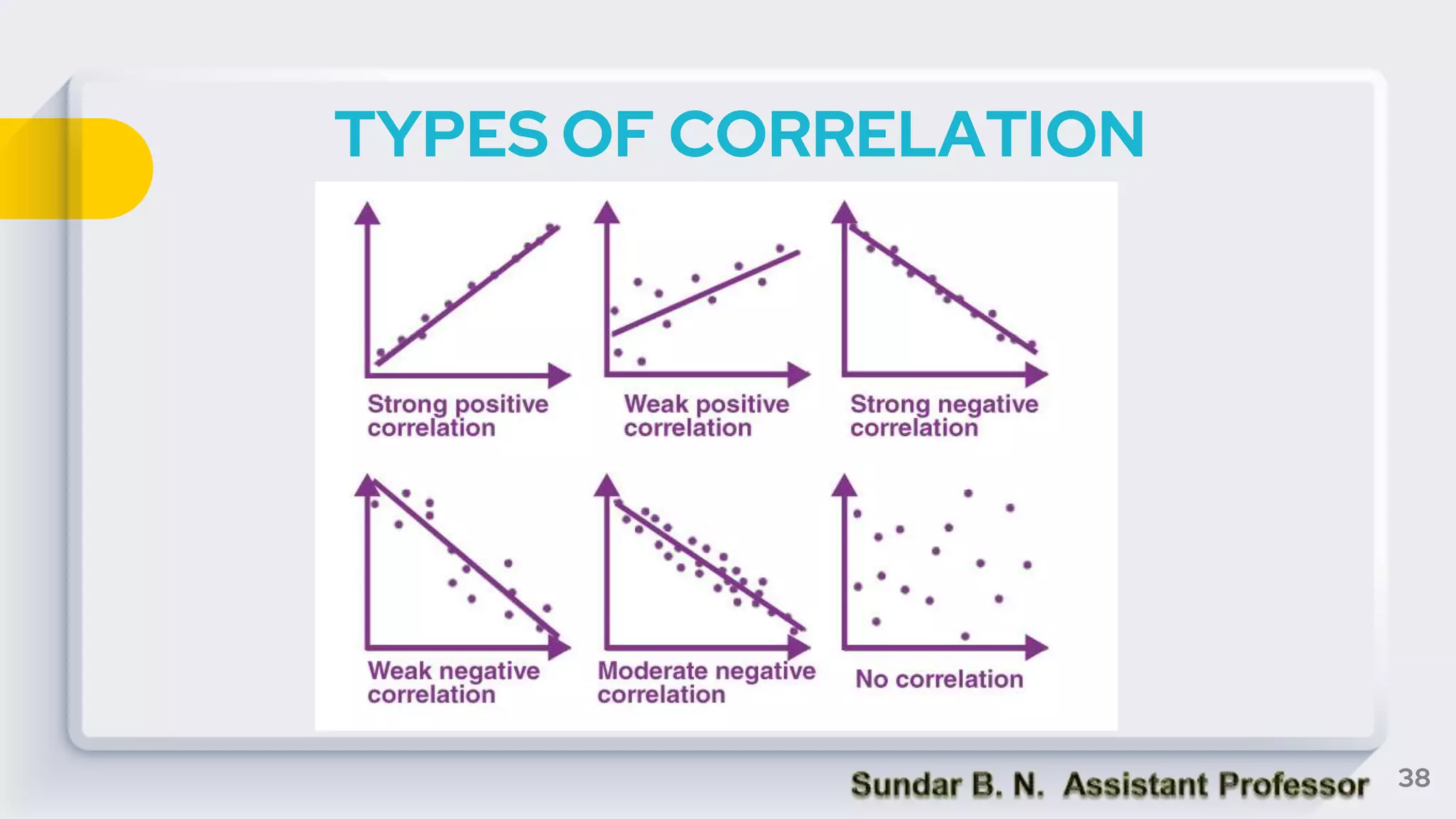





The document provides an overview of key statistical concepts including measures of central tendency, measures of dispersion, data analysis techniques, and the differences between correlation and regression. It details various types of data, methods for analyzing data, and their significance in interpreting statistical findings. Additionally, it describes different statistical measures such as mean, median, mode, variance, and standard deviation, as well as concepts like skewness and its impact on data interpretation.



































































