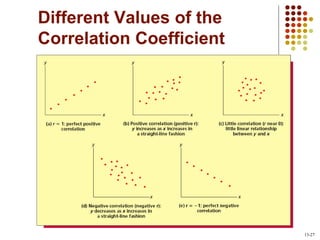
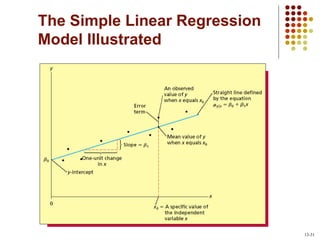
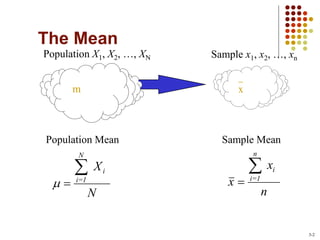
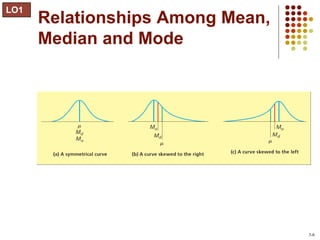
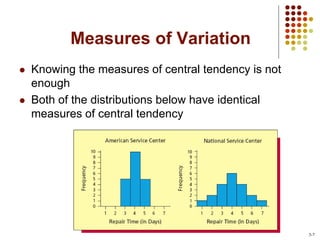
This document provides an introduction to key concepts in statistics including measures of central tendency, variation, distributions, and linear regression. It defines the mean, median, and mode as measures of central tendency. Measures of variation described include range, variance, and standard deviation. Common distributions like the normal distribution are explained and its key properties outlined. Hypothesis testing and p-values are also introduced. Finally, the concepts of covariance, correlation, and simple linear regression models are summarized.














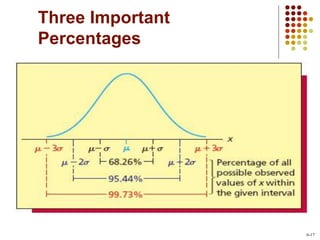
![The Empirical Rule for
Normal Populations
If a population has mean µ and standard
deviation σ and is described by a normal
curve, then
68.26% of the population measurements lie within
one standard deviation of the mean: [µ-σ, µ+σ]
95.44% of the population measurements lie within
two standard deviations of the mean: [µ-2σ, µ+2σ]
99.73% of the population measurements lie within
three standard deviations of the mean: [µ-3σ,
µ+3σ]
3-18](https://image.slidesharecdn.com/introstatsslidespost-230406204833-dd35cba6/85/IntroStatsSlidesPost-pptx-18-320.jpg)