The document summarizes research on semi-supervised learning techniques in computer vision, including SemiBoost. SemiBoost is an algorithm that uses a small amount of labeled data and a large amount of unlabeled data to train classifiers. It works by iteratively computing pseudo-labels and weights for unlabeled data based on a similarity measure, then retraining a weak learner. The document discusses extensions of SemiBoost, including learning distance functions from labeled data to define similarities, reusing priors from previous classifiers, and applications to tasks like car detection.


![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
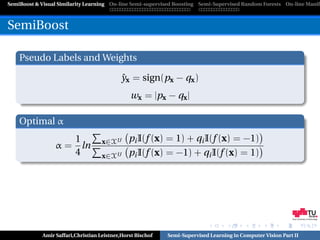
SemiBoost
[Mallapragada et al.,PAMI’09] [Leistner et al.,CVPR’08]
Loss function
(x,y)∈XL e −yF (x) +
F (x)
λu s(x, x ) cosh(F (x) − F (x )) + λl s(x, x )e −2y
x∈XU x ∈XU (x ,y )∈XL
Optimization Problem
arg min = s(x, x )e −2y(F (x )+αf (x ))
f (x),α x ∈XU (x,y)∈XL
+λu s(x, x )e ((F (x )−F (x)) e α(f (x)−f (x ))
x ∈XU Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-3-320.jpg)


![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
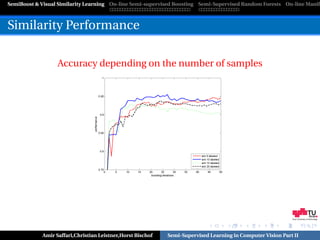
SemiBoost with learned Similarities
[Hertz et al.,CVPR’04]
Radial Basis Function [Zhu et al.,ICML’03]
d(x,x )2
−
σ2
s(x, x ) = e
d(x, x ) . . . distance between points
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-7-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Learning Distance Functions
Idea
Learn distance or metric function on labeled data which then
can discriminatively support task-specific classification.
Distance Function
F d : X × X → Y = [−1 1]
Training Pairs of “same” or “different” [Hertz et al.,CVPR’04]
Dd = {(x, x , +1)|y = y , x, x ∈ DL } ∪
∪{(x, x , −1)|y y , x, x ∈ DL }
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-8-320.jpg)

![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
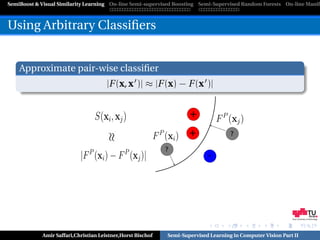
Reusing Prior Classifiers
[Schapire et al,ML’02]
Classifier Combination
F C (x) = α0 F P (x) + F (x)
?
? +
SemiBoost ?
?
- ?
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-11-320.jpg)



![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Simple Data mining method
[Levin et al.,ICCV’03][Rosenberg et al.,2005]
1 Labeled training data (x, y) ∈ XL
2 Train cascaded detector F P (x) on XL using [Viola & Jones,2001]
3 Use a web image search engine in order to collect huge
amounts of possibly useful images XU ; pass phrases that are
much likely related to your target object
4 Apply F P (x) in a sliding window manner on XU and copy all
∗
detections to XU
∗
5 Train a SemiBoost classifier F (x) on XL and XU using F P (x)
as prior
6 Output the final classifier F (x)
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-16-320.jpg)


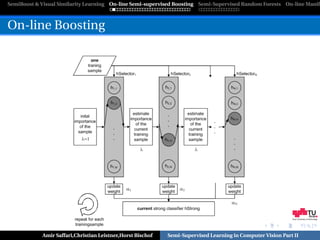
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
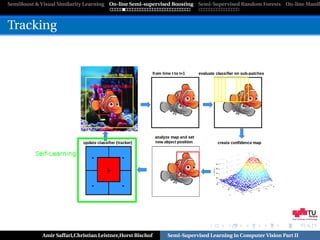
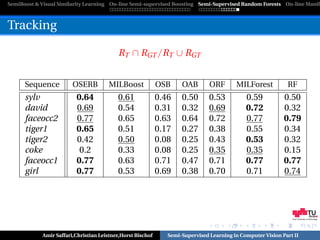
Tracking
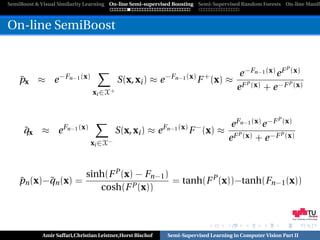
[Oza,PhD-Thesis’01], [Grabner & Bischof,CVPR’06]
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-21-320.jpg)



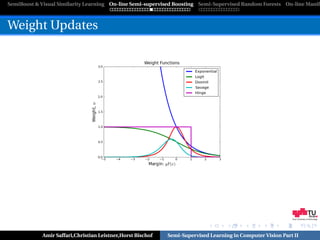
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Loss Functions
Random classification noise defeats all convex potential boosters
[Long and Servidio,ICML’08]
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-32-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
On-line Gradient Boost
Gradient Descent Functional Gradient Descent
GradientBoost [Friedman et al.,Annals of Statistics’01]
ft (x) = arg max − LT f (x)
f (x)
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-33-320.jpg)

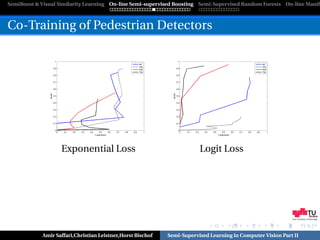
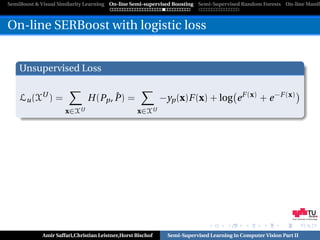
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
SERBoost
Expectation Regularization [Mann and MacCallum,ICML’07]
Penalize model predictions on unlabeled data that deviate from
certain expectation.
SERBoost [Saffari et al.,ECCV’08]
L(H (x), X) = Ll (H (x), Xl ) + βLu (H (x), Xu )
L(H (x), X) = e −yH (x) + e −yp H (x) cosh(H (x))
x∈XL x∈XU
Pseudo Label
+
yp = 2Pp (x) − 1
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-37-320.jpg)



![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Multiple Instance Boosting
[Viola et al.,NIPS’05][Babenko et al.,CVPR’09]
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-44-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Multiple Instance Boosting
[Viola et al.,NIPS’05][Babenko et al.,CVPR’09]
Bags
{(B1 , y1 ), . . . , (Bn , yn )}
Bi = {xi1 , xi2 , . . . , xini }
Minimize binary log-likelihood
log L= (yi log p(yi ) + (1 − yi ) log p(yi ))
i
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-45-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Semi-Supervised Multiple Instance Boosting
[Zeisl et al.,CVPR’10]
Combine benefits of MIL and SSL
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-46-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Semi-Supervised Multiple Instance Boosting
[Zeisl et al.,CVPR’10]
Unlabeled Loss of the Bags
Nu
Lu (XB ) = −
u Pp (z|Bu ) log(P(z|Bu ))
i i
i=1 z∈Y
Approximate max with geometric mean
NBi
1/NBi
P(y = 1|Bi ) = 1 − 1 − P(y = 1|xij )
j=1
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-47-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Semi-Supervised Multiple Instance Boosting
[Zeisl et al.,CVPR’10]
Gradient for NOR and geometric mean
2 z − P(y = 1|Bi )
aij (z) = P(y = 1|xij )
NBi P(y = 1|Bi )
Pseudo Labels and Weights
wij =β Pp (z|Bu )aij (z)
i
z∈Y
yij =I β Pp (z|Bu )aij (z) > 0
i
z∈Y
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-48-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Semi-Supervised Multiple Instance Boosting
[Zeisl et al.,CVPR’10]
Experimental Results
Sequence MILSER MIL OSB OAB
sylv 0.64 0.61 0.46 0.50
david 0.71 0.54 0.31 0.32
faceocc2 0.78 0.65 0.63 0.64
coke11 0.18 0.29 0.12 0.20
tiger1 0.60 0.51 0.17 0.27
tiger2 0.46 0.50 0.08 0.25
faceocc1 0.68 0.63 0.71 0.47
girl 0.64 0.53 0.69 0.38
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-49-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
On-line Co-Training
[Liu et al.,ICCV’09][Saffari et al.,ECCV’10]
Performance measured in average location center errors in pixels
Approach sylv david faceocc2 tiger1 tiger2 coke faceocc1 girl
MV-GPBoost 17 20 10 15 16 20 12 15
CoBoost 15 33 11 22 19 14 13 17
SemiBoost 22 59 43 46 53 85 41 52
MILBoost 11 23 20 15 17 21 27 32
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-50-320.jpg)

![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Random Forests
[Breiman,ML’01]
Ensemble of n decision trees
N
F (x) = n=1 f (x)
Information Gain
|Il | |Ir |
∆H = − |I |+|Ir | H (Il ) − |Il |+|Ir | H (Ir )
l
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-52-320.jpg)


![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Random Forests
Advantages:
speed
parallelism
noise robust
inherently multi-class
Applications:
Object Detection, Semantic Segmentation, Categorization,
Tracking, etc.
Disadvantage:
RFs demand a huge amount of data in order to leverage their
full potential [Caruana et al.,ICML’08]
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-55-320.jpg)


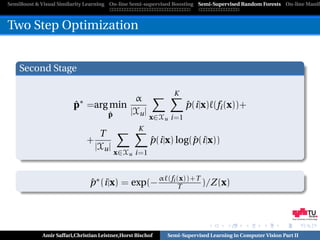
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
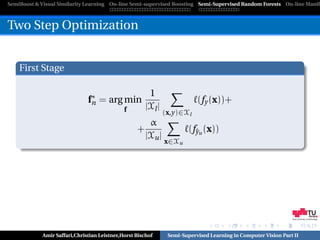
Optimization
Incorporate labels for the unlabeled data as additional
optimization variables!
Deterministic Annealing [Rose,IJCNN’98]
p ∗ = arg minEp (F(y)) − T H(p)
p∈P
T0 > T1 > . . . > T∞ = 0
p ∗ . . . distributions over the label predictions
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-58-320.jpg)




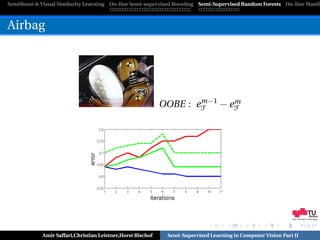
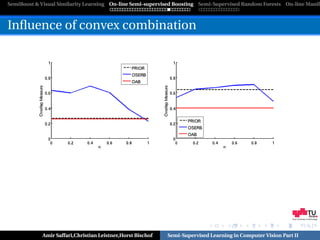
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Multiple Instance Forests
[Leistner et al.,ECCV’10]
-
-
- -
+ -
-
+ -
- -
-
+
-
[Dietterich,AI’97]
Content-based Image Retrieval
Object Detection and Categorization
Tracking
Action Recognition
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-69-320.jpg)



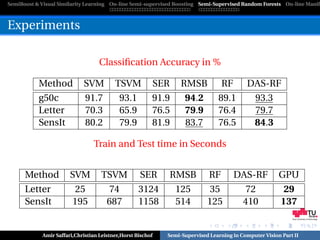
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Evaluation
Method Elephant Fox Tiger Musk1 Musk2
RandomForest[Breiman,2001] 74 60 77 85 78
MILForest 84 64 82 85 82
MI-Kernel[Andrews,2003] 84 60 84 88 89
MI-SVM[Zhou,2009] 81 59 84 78 84
mi-SVM[Zhou,2009] 82 58 79 87 84
MILES[Chen,2006] 81 62 80 88 83
SIL-SVM[Bunescu,2007] 85 53 77 88 87
AW-SVM[Gehler,2007] 82 64 83 86 84
AL-SVM[Gehler,2007] 79 63 78 86 83
EM-DD[Zhang,2001] 78 56 72 85 85
MILBoost-NOR[Viola,2006] 73 58 56 71 61
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-73-320.jpg)

![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Corel Data Set
Results for the COREL image categorization benchmark
Method Corel-1000 Corel-2000 Testing[sec.] Training[sec.]
MILForest 59 66 4.6 22.0
MILES 58 67 180 960
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-75-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
Semantic Segmentation
[Vezhnevets & Buhmann,CVPR’10]
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-76-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
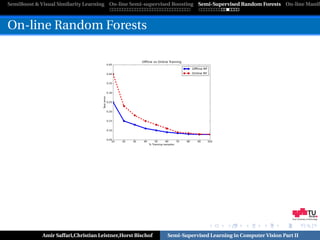
On-line Random Forests
On-line Bagging [Oza,PhD-Thesis’01] → Poisson(λ)
On-line recursive splitting is hard → Tree Growing
Info Gain
|Rjls | |Rjrs |
∆L(Rj , s) = L(Rj ) − L(Rjls ) − L(Rjrs )
|Rj | |Rj |
Splitting Rules
|Rj | > α and ∃s ∈ S : ∆L(Rj , s) > β
On-line DA → Annealing Schedule for each sample xi
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-78-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
On-line Manifold Regularization
[Goldberg et al.,ECML’08]
Based on Convex Programming in kernel space using
stochastic gradient descent
Random Projection Trees [Dasgupta & Freund, TR, 2007]
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-84-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
On-line Manifold Regularization
[Goldberg et al.,ECML’08]
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-85-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
On-line Graph-based SSL
[Kveton et al.,OLCV’10]
Harmonic Function Solution
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-86-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
On-line Graph-based SSL
[Kveton et al.,OLCV’10]
Merge the two most similar vertices and add the new vertex
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-87-320.jpg)
![SemiBoost & Visual Similarity Learning On-line Semi-supervised Boosting Semi-Supervised Random Forests On-line Manifo
On-line Graph-based SSL
[Kveton et al.,OLCV’10]
Face recognition of 8 people
Graz University of Technology
Amir Saffari,Christian Leistner,Horst Bischof Semi-Supervised Learning in Computer Vision Part II](https://image.slidesharecdn.com/presentation2-110515232835-phpapp02/85/CVPR2010-Semi-supervised-Learning-in-Vision-Part-3-Algorithms-and-Applications-88-320.jpg)















































































































